
Apache Kafka를 활용한 분산 메세징 시스템에서 컨슈머 그룹(Consumer Group)은 효율적이고 안정적인 메세지 처리를 위한 핵심 개념이다. 이 글에서는 컨슈머 그룹의 개념과 동작 원리, 그리고 실무에서 알아야 할 중요한 특징들을 살펴보겠다.
컨슈머 그룹의 정의
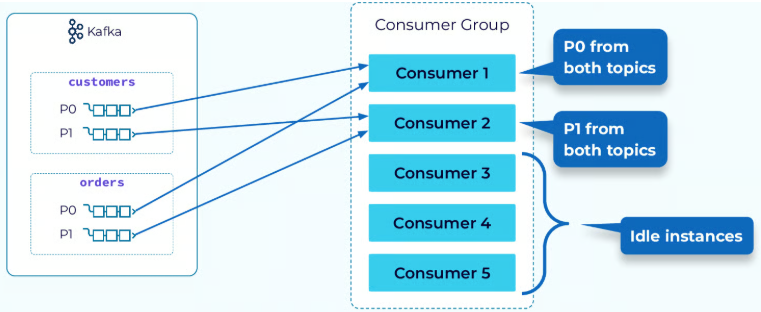
1. 파티션 소유권 공유
컨슈머 그룹 내의 컨슈머들은 토픽의 파티션(Partition)에 대한 소유권을 나눠서 가진다. 이는 병렬 처리와 부하 분산을 가능하게 하는 핵심 매커니즘이다.
- 하나의 파티션은 컨슈머 그룹 내에서 오직 하나의 컨슈머에만 할당된다.
- 하나의 컨슈머는 여러개의 파티션을 담당할 수 있다.
- 파티션 수보다 컨슈머 수가 많으면, 일부 컨슈머는 유후 상태가 된다.
2. 메세지 중복 방지
동일한 컨슈머 그룹 내에서 각 메세지는 단 한번만 처리 된다. 레코드(Record)는 컨슈머 그룹 내의 오직 하나의 컨슈머로만 전달되므로, 메세지 중복 처리를 방지할 수 있다.
내결함성(Fault Tolerance)
컨슈머 그룹의 가장 강력한 장점 중 하나는 장애 대응 능력이다. 특정 컨슈머에 문제가 발생하면 다음과 같다.
- 동일 그룹 내의 다른 컨슈머가 자동으로 해당 파티션을 인계 받는다.
- 이 과정을 리밸런싱(Rebalancing)이라고 한다.
- 서비스 중단 없이 지속적인 메세지 처리가 가능하다.
리밸런싱(Rebalancing)
리밸런싱은 컨슈머 그룹 내에서 파티션 소유권을 재분배하는 프로세스이다. 다음과 같은 경우에 발생한다.
- 새로운 컨슈머가 그룹에 추가 될 때
- 기존 컨슈머가 종료되거나 장애가 발생했을 때
- 토픽의 파티션 수가 변경되었을 때
리밸런싱 동안에는 일시적으로 메세지 처리가 중단될 수 있으므로, 최소화 하는것이 중요하다.
컨슈머와 파티션의 관계
이상적인 구성
토픽 : 파티션 4개
컨슈머 그룹: 컨슈머 4개
→ 각 컨슈머가 1개의 파티션씩 담당 (최적 분산)
컨슈머가 적은 경우
토픽 : 파티션 4개
컨슈머 그룹: 컨슈머 2개
→ 각 컨슈머가 2개의 파티션씩 담당
컨슈머가 많은 경우
토픽 : 파티션 4개
컨슈머 그룹: 컨슈머 6개
→ 4개의 컨슈머만 활성화,2개는 유후 상태
Offset 관리
카프카의 컨슈머 그룹은 각 파티션에서 어디까지 메세지를 읽었는지를 Offset으로 관리한다.
- Offset은 컨슈머 그룹별로 독립적으로 관리된다.
- 카프카의 내부 토픽(__consumer_offsets)에 저장된다.
- 컨슈머 장애 후 복구 시, 마지막 처리 위치부터 재개할 수 있다.
- 동일 토픽을 구독하는 다른 컨슈머 그룹은 독립적인 Offset을 유지한다.
실무 활용 시나리오
시나리오 1: 스케일 아웃
트래픽이 증가하면 컨슈머를 추가하여 처리 용량을 확장할 수 있다.
# 초기상태
Consumer Group A: Consumer 1, Consumer 2 (파티션 4개 처리)
# 트래픽 증가 후
Consumer Group A: Consumer 1, Consumer 2, Consumer 3, Consumer 4
→ 처리 속도 2배 향상
시나리오 2: 멀티 애플리케이션
동일한 토픽을 여러 목적으로 사용하는 경우
# 주문 토픽을 여러 서비스가 구독
- Consumer Group "payment-service": 결제 처리
- Consumer Group "notification-service": 알림 발송
- Consumer Group "analytics-service": 데이터 분석
→ 각 그룹이 독립적으로 모든 메시지 처리
컨슈머 그룹 설정 예시
Java 설정
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "my-consumer-group"); // 컨슈머 그룹 ID
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
주요 설정 파라미터
- group.id : 컨슈머 그룹의 고유 식별자
- enable.auto.commit: Offset 자동 커밋 여부
- auto.offset.reset: 초기 Offset 설정 (earliest, latest, none)
- max.poll.records : 한번의 poll()에서 가져올 최대 레코드 수
정리
카프카 컨슈머 그룹은 다음과 같은 핵심 가치를 제공한다.
✅ 병렬 처리: 여러 컨슈머가 파티션을 나눠서 처리
✅ 확장성: 컨슈머 추가를 통한 손쉬운 스케일 아웃
✅ 내결함성: 컨슈머 장애 시 자동 복구
✅ 메시지 순서 보장: 파티션 내에서 순서 보장
✅ Offset 관리: 정확한 처리 위치 추적
카프카를 활용한 분산 시스템을 설계할 때, 컨슈머 그룹의 특성을 잘 이해하고 활용한다면 안정적이고 확장 가능한 아키텍처를 구축할 수 있다.
'🔥 Data Engineer > Kafka' 카테고리의 다른 글
| [Kafka] - 카프카 CLI 명령어 핵심 정리 (0) | 2026.01.26 |
|---|---|
| [Kafka] - 카프카 KSQL(KsqlDB)란? 스트리밍 SQL로 실시간 데이터 처리하기 (0) | 2026.01.22 |
| [Kafka] - 카프카 server.properties 설정방법 (1) | 2026.01.20 |
| [Kafka] - 카프카 스키마 레지스트리(kafka Schema Registry) (1) | 2026.01.20 |
| [Kafka] - 멱등성,At least once,At most once,Exactly once (0) | 2026.01.13 |


