이장에서는 실용적인 측면에서 맵리듀스 애플리케이션을 개발하는 방법을 살펴본다.
맵리듀스 프로그램은 일련의 개발 절차를 따른다. 먼저 맵과 리듀스 함수를 구현하고 잘 동작하는지 확인하기 위한 단위 테스트를 작성한다.다음 잡을 실행하는 드라이버 프로그램을 작성하고, 정상 작동하는지 검증하기위해 데이터셋 일부를 이용해 IDE를 실행한다. 만일 실패하면 IDE 디버거를 통해 문제원인을 찾는다.이 정보를 활용해서 해당 문제를 검증하도록 단위 테스트를 확장하거나 매퍼와 리듀서가 입력을 정확히 처리하도록 개선할 수있다.
작은 데이터 셋이 예상대로 잘 동작하면 클러스터에서 본격적으로 실행한다. 전체 데이터셋을 실행하면 이전 단계에서 해결했던 것보다 더 많은 새로운 이슈가 발생함. 새로운 문제를 해결하기 위해서는 전처럼 단위 테스트를 확장하고 매퍼와 리듀서를 수정하면 된다. 하지만 클러스터에서 실패한 프로그램의 디버깅은 매우 어렵기 때문에 쉽게 해결할 수 있는 일반적인 기술들을 살펴보자.
먼저 맵리듀스 프로그램이 더 빠르게 수행되도록 표준검사를 실행하고, 그 후 태스크 프로파일링(성능 분석)을 수행한다.
분산 프로그램의 프로파일링은 쉬운일이 아니므로 이를 지원하기위해 하둡은 훅(가로채기)을 제공한다.
맵리듀스 프로그램 작성전 개발환경을 설치하고 설정해야 한다. 이를 위해 하둡의 설정 방법을 조금 배울 필요가 있다.
6-1 환경 설정 API
하둡의 컴포넌트는 하둡 자체의 환경 설정 API를 이용하여 설정할수 있다.org.apache.hadoop.conf 패키지에 있는 Configuration클래스 인스턴스는 환경설정 속성과 값의 집합이다. 속성의 이름은 String 타입을, 속성의 값은 boolean, int, long, float와 같은 자바의 기본 자료형이나 String, Class, java.io.File, 문자열 컬렉션과 같은 자료형을 쓸 수 있다.
Configuration은 리소스라 불리는 이름-값 쌍의 단순한 구조로 정의된 XML 파일로부터 속성 정보를 읽는다.
(자바를 사용해본 사람들은 알태지만 @Configuration 을 사용하면 애플리캐이션에 대한 설정정보를 정의할수 있다)
단순한 설정파일(configuration-1.xml)
<?xml version="1.0"?>
<configuration>
<property>
<name>color</name>
<value>yellow</value>
<description>Color</description>
</property>
<property>
<name>size</name>
<value>10</value>
<description>Size</description>
</property>
<property>
<name>weight</name>
<value>heavy</value>
<final>true</final>
<description>Weight</description>
</property>
<property>
<name>size-weight</name>
<value>${size}, ${weight}</value>
<description>Size and Weight</description>
</property>
</configuration>
다음 코드를 이용하면 환경설정 파일인 configuration-1.xml로부터 속성 정보를 얻을 수 있다.
Configuration conf = new Configuration();
conf.addResource("Configuration-1.xml")
assertThat(conf.get("color"), is("yellow"));
assertThat(conf.getInt("size,0"), is("10"));
assertThat(conf.get("color", "wide"), is("wide"));
여기서 XML파일에 자료형에 대한 정보가 없다는 점에 주의해야 한다. 그대신 속성파일을 읽을때 지정한 자료형으로 해석된다. 또한 get() 메서드에 기본값을 넘길 수 있으며, 예제의 breath와 같이 XML 파일에 정의되지 않은 속성도 사용할 수 있다.
6-1-1 리소스 결합하기
환경설정 세팅시 하나 이상의 리소스(XML 파일)를 사용할 수 있다. 하둡은 이 기능을 활용하여 시스템의 기본 속성은 내부의 core-default.xml 파일로, 특정 속성은 core-site.xml 파일로 분리해서 정의했다. 아래 xml은 size와 weight 속성을 정의한것이다.
<?xml version="1.0"?>
<configuration>
<property>
<name>size</name>
<value>12</value>
</property>
<property>
<name>weight</name>
<value>light</value>
</property>
</configuration>
리소스들은 다음과 같이 환경 설정에 순서대로 추가된다.
Configuration conf = new Configuration();
conf.addResource("configuration-1.xml");
conf.addResource("configuration-2.xml");
나중에 추가된 리소스에 정의된 속성은 이전에 정의된 속성을 오버라이드 한다.따라서 size 속성은 두 번째 설정 파일 configuration-2.xml에 정의된 값을 따른다.
assertThat(conf.getInt("size",0), is(12));
그러나 final로 지정된 속성은 이후에 다시 정의해도 변경되지 않는다. 따라서 weight 속성은 첫번째 설정 파일에서 final로 지정되었기 때문에 두번째 오버라이드 시도는 실패하고 처음 할당된 값을 그대로 갖게된다.
assertThat(conf.get("weight"), is("heavy"));
일반적으로 final 속성을 재정의하려는 시도는 환경 설정 오류의 원인이 되므로 장애 진단을 위해 경고 메세지를 로그로 남긴다. 관리자는 클라이언트의 설정파일이나 잡 제출 매개변수를 사용자가 변경하지 못하도록 데몬 사이트 파일의 속성을 final로 지정할수 있다.
6-1-2 변수 확장
환경 설정 속성은 다른 속성이나 시스템 속성으로도 정의할 수 있다. 예를 들어 앞서 첫 번째 설정 파일인 size-weight 속성은 ${size}, ${weight}로 정의되며, 이 속성들은 환경 설정에서 찾은 값을 사용한다.
assertThat(conf.get("size-weight"), is("12,heavy"));시스템 속성은 리소스 파일에 정의된 속성보다 우선순위가 높다.
System.setProperty("size", "14");
assertThat(conf.get("size-weight"), is("14,heavy"));
이 기능은 명령행에서 -Dproperty=value 라는 JVM 인자를 이용하여 속성을 오버라이드 할때 유용하다.
환경설정 속성은 시스템 속성으로도 정의할 수 있지만 주의할 점이 있다. 미리 정의되지 않은 속성을 시스템 속성으로 재정의한다면 환경 설정 API는 새로운 시스템 속성을 전혀 인식하지 못한다.
System.setProperty("length", "2");
assertThat(conf.get("length"), is((String) null));
6-2 개발환경 설정
맵리듀스 프로그램을 명령행이나 IDE 환경에서 빌드하고 로컬(독립) 모드로 실행하려면 먼저 프로젝트를 생성해야한다 메이븐 POM으로, 맵리듀스 프로그램을 빌드하고 테스트 하는데 필요한 의존성을 보여준다.
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>mapreduce-app</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<hadoop.version>3.3.6</hadoop.version> <!-- 사용하는 하둡 버전에 맞게 설정 -->
</properties>
<dependencies>
<!-- Hadoop Client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
<!-- Unit Test -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<!-- MapReduce Test (MRUnit) -->
<dependency>
<groupId>org.apache.mrunit</groupId>
<artifactId>mrunit</artifactId>
<version>1.1.0-hadoop2</version> <!-- 하둡 3은 별도 설정 필요할 수 있음 -->
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Fat Jar (Uber Jar) 생성을 위한 Shade Plugin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
POM에서 흥미로운 부분은 바로 의존성 섹션이다. 여기서 정의한 의존성과 동일하다면 그레이들(Gradle)이나 아파치 앤트의 아이비 같은 빌드 도구를 사용하는 것이 더 직관적이다. 맵리듀스 잡을 빌드하려면 하둡의 클라이언트 클래스(HDFS 및 맵리듀스와 통신하기 위한)를 모두 포함한 hadoop-client 의존성만 있으면 된다. 단위 테스트에는 junit을, 맵리듀스 테스트에는 mrunit을 사용할 수 있다. hadoop-minicluster 라이브러리는 단일 JVM으로 실행되는 하둡 클러스터에서 테스트 할때 유용한 '미니'클러스터를 포함하고 있다.
많은 IDE에서 메이븐 POM을 직접 지원하기 때문에 pom.xml 파일을 포함한 디렉터리를 지정한 후 바로 코드를 작성하면 된다. 아니면 메이븐을 사용하여 IDE를 위한 설정 파일을 만들 수도 있다. 예를 들어 다음 명령은 프로젝트를 이클립스로 임포트하기 위해 이클립스용 설정 파일을 생성하는 예제다.
% mvn eclipse:eclipse -DdownloadSources=true -DdownloadJavadocs=true
6-2-1 환경설정 파일 관리하기
하둡 애플리케이션 개발할때는 로컬모드와 클러스터 모드를 번갈아 가며 테스트하는 것이 좋다. 보통 여러대의 머신으로 구성된 클러스터에서 실제 작업을 수행한다. 하지만 테스트를 위해 단일 로컬 머신에서 모든 데몬을 실행하는 의사분산클러스터를 하나쯤 가지고 있는 경우가 많다.
다양한 클러스터 환경을 이용할수 있도록 각 클러스터의 연결 정보를 가진 환경 설정 파일들을 먼저 만들고 하둡 애플리케이션이나 도구를 실행할 때 그중 하나를 지정하는 방법이 있다. 설정 파일의 중복이나 분실을 방지하기 위해 하둡 설치 디렉터리 외부에 이러한 파일을 보관할것을 권장한다
hadoop-cluster.xml 등 세게의 환경설정 파일이 있다 가정하자. 이 파일들에 특별한 명명규칙이 있는건 아니지만 환경설정 정보를 패키지로 편리하게 관리하려고 하는것이다 3가지에 대해 비교해보자
로컬모드 : hadoop-local.xml 파일은 기본 파일시스템과 맵리듀스 잡을 실행하는 로컬(단일 JVM) 프레임워크에 적합한 하둡 설정을 가진다.
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>file:///</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>local</value>
</property>
</configuration>
의사분산 모드 : hadoop-localhost.xml 파일에 로컬에서 작동하는 네임노드와 YARN 리소스 매니저의 위치를 설정한다.
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8032</value>
</property>
</configuration>
완전분산 모드 : hadoop-cluster.xml 파일은 클러스터의 네임노드와 YARN 리소스 매니저의 주소를 가진다. 실무에서는 예제에 사용된 'cluster'라는 이름 대신 실제 클러스터의 이름을 사용할 것을 권장한다.
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode/</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>resourcemanager:8032</value>
</property>
</configuration>
필요시 설정 파일에 다른 환경 설정속성을 추가할수도 있다.
사용자 인증 설정
하둡은 클라이언트 시스템에서 whoami 명령어를 실행하여 알게 된 사용자에 대해 HDFS의 접근 권환을 확인한다.
비슷하게 그룹명은 groups 명령으로 확인할 수 있다.
만약 하둡의 사용자 이름과 클라이언트 머신의 사용자 계정이 다르면 HADOOP_USER_NAME 환경 변수에 사용자 이름을 명시적으로 설정하면 된다. 그리고 사용자 그룹은 hadoop.user.group.static.mapping.overrides 설정 속성으로 재정의할 수 있다. 예를 들어 dr.who=; preston=dir ectors,inventors는 dr.who 사용자는 그룹이 없고 preston은 directors와 inventors 그룹에 속한다는 것을 의미한다.
하둡 웹 인터페이스를 실행하는 사용자 이름은 hadoop.http.staticuser.user 속성에 설정한다. 슈퍼유저가 아닌 dr.who가 기본 사용자이므로 웹 인터페이스를 통해서는 시스템 파일에 접근할 수 없다.
하둡은 기본적으로 시스템 내에 인증 기능을 제공하지 않는다는 점을 명심해야 한다.
명령행에서 -conf 뒤에 설정 파일을 명시적으로 지정하면 원하는 환경설정을 쉽게 이용할수 있다. 예를들어 다음 명령행은 로컬호스트에서 의사분산 모드로 실행중인 HDFS 서버의 디렉터리 목록을 보여준다.
% hadoop fs -conf conf/hadoop-localhost.xml -ls.
Found 2 items
drwxr -xr-x - tom supergroup 0 2014-09-08 10:19 input
drwxr -xr-x - tom supergroup 0 2014-09-08 10:19 output
-conf 옵션을 생략하면 $HADOOP_HOME 아래에 있는 etc/hadoop 디렉터리에서 하둡 설정을 찾는다. 또한 HADOOP_CONF_DIR를 별도로 설정했다면 그 위치에서 하둡 설정 파일을 찾는다.
하둡이 제공하는 도구는 -conf 옵션을 지원하지만 Tool 인터페이스를 이용하여 사용자 프로그램(맵리듀스 잡을 실행하는 프로그램)에서 이 옵션을 지원하도록 작성하는 것이 더 직관적이다.
6-2-2 GenericOptionsParser, Tool, ToolRunner
하둡은 명령행에서 잡을 쉽게 실행할수 있도록 몇가지 헬퍼 클래스를 제공한다.
-GenericOptionsParser : 명령행 옵션을 해석하여 Configuration 객체에 값을 설정함, GenericOptionsParser클래스를 직접 사용하기 보다 Tool 인터페이스를 구현한 애플리케이션을 작성한 후 GenericOptionsParser를 내부에서 호출하는 ToolRunner 프로그램을 실행하는 것이 더 편리함.
public interface Tool extends Configurable {
int run(String [] args) throws Exception;
}
Tool의 Configuration 객체에 속한 모든 키와 그값을 출력하는 예제이다.
public class Configurationprinter extends Configured implements Tool {
static {
Configuration.addDefaultResource("hdfs-default.xml");
Configuration.addDefaultResource("hdfs-site.xml");
Configuration.addDefaultResource("yarn-default.xml");
Configuration.addDefaultResource("yarn-site.xml");
Configuration.addDefaultResource("mapred-default.xml");
Configuration.addDefaultResource("mapred-site.xml");
}
@Override
public int run(String[] args) throws Exception{
Configuration conf = getConf();
for (Entry<String, String> entry: conf) {
System.out.printf("%s=%s\n", entry.getKey(), entry.getValue());
}
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new ConfigurationPrinter(), args);
System.exit(exitCode);
}
}
Configurable 인터페이스를 구현한 Configured 클래스를 상속받아 ConfigurationPrinter를 만든다. Configured 클래스를 상속받으면 Tool 인터페이스의 부모인 Configurable 인터페이스를 쉽게 구현할 수 있다(Tool이 이를 확장함). run() 메서드는 Configurable의 getConf() 메서드를 통해 Configuration 객체를 반복적으로 얻고 모든 속성을 표준 출력으로 출력한다.
정적(static) 블록은 핵심 환경 설정(Configuration이 이미 알고있는)외에 HDFS,YARN,맵리듀스 환경 설정을 명시적으로 추가한다.
ConfigurationPrinter의 main() 메서드는 자신의 run() 메서드를 직접 호출하지는 않는다. 그대신 우리는 Tool의 Configuration 객체를 책임지고 생성하는 ToolRunner의 run() 정적 메서드를 호출한다. ToolRunner는 GenericOptionsParser를 이용하여 명령행에 명시된 표준 옵션을 추출하여 Configuration 객체에 설정한다. 다음 명령을 실행하면 conf/hadoop-localhost.xml에 명시된 속성을 추출하는 것과 동일한 효과를 얻을 수 있다.
% mvn compile
% export HADOOP_CLASSPATH=target/classes/
% hadoop ConfigurationPrinter -conf conf/hadoop-localhost.xml \
| grep yarn.resourcemanager. address=
yarn.resourcemanager.address=localhost:8032핵심 구조 먼저 이해
- Configuration
→ 하둡 설정값 모음 (XML 설정들) - Configurable 인터페이스
→ “Configuration을 받아서 쓰는 객체”라는 규칙 - Configured 클래스
→ Configurable을 이미 구현해 둔 편의 클래스
→ 이걸 상속받으면 설정 다루는 코드 직접 안 만들어도 됨 - Tool 인터페이스
→ 실행 가능한 하둡 프로그램 규칙 (run() 있음)
→ 내부적으로 Configurable도 포함 - ToolRunner
→ 프로그램 실행 도와주는 실행기
→ Configuration 생성 + 옵션 파싱 담당
해석
ConfigurationPrinter라는 프로그램을 만들 때,
Configurable을 직접 구현하지 말고
이미 구현되어 있는 Configured 클래스를 상속받아 만든다.
“설정 다루는 기능은 이미 만들어져 있으니 그걸 가져다 쓰자”
GenericOptionsParser는 또한 개별 속성을 지정할 수 있는 기능을 제공한다.
% hadoop ConfigurationPrinter -D color=yellow | grep color
color=yellow
여기서 -D 옵션으로 color 키에 yellow 값을 설정했다. -D로 명시한 옵션은 환경 설정 파일에서 설정한 속성보다 우선순위가 높다.
이는 환경설정 파일에 기본값을 정의하고 필요할 때 -D 옵션으로 값을 재정의 할수 있어서 매우 유용하다. 예를들어 맵리듀스 잡의 리듀서 수를 -D mapreduce.job.reduces=n 으로 설정하면 클러스터나 클라이언트 측 환경설정 파일에 설정했던 리듀서 수를 오버라이드 한다.
GenericOptionsParser와 ToolRunner의 옵션
| 옵션 | 설명 |
| -D property=value | 지정된 하둡 환경 설정 속성을 주어진 값으로 설정한다. 환경설정 파일에 존재하는 기본 또는 사이트 속성과 -conf 옵션을 통해 설정한 모든 속성을 오버라이드 한다. |
| -conf filename... | 환경 설정의 리소스 목록에 지정한 파일을 추가한다. 사이트 속성이나 다수의 속성을 한번에 설정할 때 편리하다. |
| -fs uri | 지정된 URI로 기본 파일시스템을 설정한다. 이는 -D fs.defaultFS=uri의 단축 명령이다. |
| -jt host:port | 지정된 호스트와 포트로 YARN 리소스 매니저를 설정한다(하둡 버전 1에서는 이 옵션으로 잡트래커의 주소를 설정했다). 이는 -D yarn, resourcemanager.address=host:port의 단축 명령이다. |
| -files file1, file2, ... | 지정된 파일을 로컬 파일시스템(또는 URI 스킴으로 지정된 모든 파일 시스템)에서 맵리듀스가 사용할 공유 파일시스템(대개 HDFS)으로 복사해서 태스크 작업 디렉터리 안에 존재하는 맵리듀스 프로그램이 사용 가능하게 한다. |
| -archives archive1,archive2, ... | 지정된 아카이브 로컬 파일시스템(또는 URI 스킴으로 지정된 모든 파일시스템)에서 맵리듀스가 사용할 공유 파일시스템(HDFS)으로 복사한 후 이 아카이브를 해제한다. 맵리듀스 프로그램은 이를 태스크의 작업 디렉터리에서 활용할 수 있다. |
| -libjars jar1,jar2, ... | 지정된 JAR 파일을 로컬 파일시스템(또는 URI 스킴으로 지정된 모든 파일시스템)에서 맵리듀스가 사용할 공유 파일시스템(HDFS)으로 복사한 후 맵리듀스 태스크의 클래스패스에 추가한다. 이 옵션은 잡이 의존하는 JAR 파일을 전송하는 효과적인 방법이다. |
6-3 엠알유닛으로 단위 테스트 작성하기
맵리듀스의 맵과 리듀스 함수는 개별적으로 테스트하기 쉬운데, 이것이 바로 함수형 스타일의 장점이다.
엠알유닛(MRUnit) 은 매퍼와 리듀서에 데이터를 전달하고 예상대로 출력되는지 점검할 수 있는 테스트 라이브러리다. 제이유닛과 같은 표준 테스트 실행 프레임워크와 연동하여 일반적인 개발 환경에서 맵리듀스 잡의 실행이 가능하다.
6-3-1 매퍼
자바에서도 Mapper와 Repository를 많이 사용한다. 자바의 mapper는 00.xml과 같이 sql문을 정의해놓은 파일과 많이 사용한다. SQL문을 정의하고 그 결과를 정의해놓은 모델에 매핑시키는 ibatis(mybatis) 방식에서 사용하는 것으로 mapper는 매핑이라는 단어에서 유추할 수 있듯이 sql문(xml)을 메소드(java)로 매핑 시켜주는 것을 의미한다.
import java.io.IOException;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.junit.*;
public class MaxTemperatureMapperTest {
@Test
public void processesValidRecord() throws IOException, InterruptedException {
Text value = new Text("518091280580912850912890580+678253+32432FM-12+0384" +
// 연도 ^^^^
"9a8s7d987sa9d79ad9as9d9a8-00111+9999999999999");
// 기온 ^^^^
new MapDriver<LongWritable, Text, Text, IntWritable>()
.withMapper(new MaxTemperatureMapper())
.withInput(new LongWritable(0), value)
.withOutput(new Text("1950"), new IntWritalbe(-11))
.runTest();
}
}
매퍼를 테스트하기 위해 엠알유닛의 MapDriver를 사용했다. 먼저 MaxTemperatureMapper 인스턴스를 설정하고, 입력키와 값, 예상되는 출력키(연도는 Text 객체로 1950)와 값(기온은 IntWritable로 -1.1도)을 설정한 다음 최종적으로 runTest()함수를 호출한다.
매퍼의 출력값이 예상과 다르면 엠알유닛 테스트는 실패한것이다. 여기서 입력키는 매퍼가 무시하므로 임의의 값을 넣어도 상관없다.
// 레코드 파서 클래스를 활용한 매퍼
public class MaxTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritalbe> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
Public void map(LongWritable key, Text value, Context conetext)
throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
context.write(new Text(parser.getYear()),
new IntWritable(parser.getAirTemperature()));
}
}
}6-3-2 리듀서
리듀서는 입력받은 키의 최대 기온값을 찾는다. 다음은 ReducerDriver를 사용해서 이 기능을 테스트하는 간단한 코드다.
@Test
public void returnsMaximumIntegerInValues() throws IOException,
InterruptedException {
new ReduceDriver<Text, IntWritable, Text, IntWritalbe>()
.withReducer(new MaxTemperatureReducer())
.withInput(new Text("1950"),
Arrays.asList(new IntWritable(10), new IntWritable(5)))
.withOutput(new Text("1950"), new IntWritable(10))
.runTest();
}
테스트를 위해 입력할 IntWritable 값의 목록을 만들고 MaxTemperatureReducer가 최댓값을 제대로 찾는지 검증해보자.
아래 코드는 테스트를 통과한 MaxTemperatureReducer를 구현한것이다.
// 최대 기온 예제의 리듀서
public class MaxTemperatureReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
6-4 로컬에서 실행하기
지금까지 임의로 생성한 입력에 대해 잘 작동하는 매퍼와 리듀서를 만들었다. 다음으로 잡 드라이버를 작성하고 개발 머신에서 테스트 데이터로 실행해보자.
6-4-1 로컬 잡 실행하기
이 장 앞에서 소개한 Tool 인터페이스를 활용하면 연도별 최대 기온을 찾는 맵리듀스 잡을 실행하는 드라이버를 쉽게 작성할수 있다.
// 최대 기온을 찾는 애플리케이션
public class MaxTemperatureDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws exception {
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output> \n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Job job = new Job(getConf(), "Max temperature");
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(ture) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MaxTemperatureDriver(), args);
System.exit(exitCode);
}
}
MaxTemperatureDriver는 Tool 인터페이스의 구현체로, GenericOptionsParser가 제공하는 옵션 설정 기능을 이용할 수 있다.
run() 메서드는 잡이 시작될 때 사용하는 Tool의 환경 설정을 기반으로 Job 객체를 생성한다. 지정할 수 있는 잡 환경 설정 중 입출력 파일 경로, 매퍼, 리듀서, 컴바이너 클래스, 출력 타입을 설정했다. 여기서 입력타입은 기본 입력 포맷인 TextInputFormat이며
LongWritable 키와 Text 값을 가진다. 잡이름을 MaxTemperature로 지정하여 실행중 그리고 종료후 잡 목록에서 쉽게 찾을수 있도록 하였다. 기본으로 잡의 이름은 JAR 파일의 이름인데, 별로 적절하진 않다.
이제 로컬파일로 애플리케이션을 실행해보자. 하둡은 맵리듀스 실행 엔진의 축소 버전으로, 단일 JVM에서 동작하는 로컬 잡 실행자를 제공한다. 이 실행자는 테스트 용도로 설계되었으며 매퍼와 리듀서 코드를 단계별로 실행하며 디버깅 할수 있으므로 IDE에서 편하게 실행할 수 있다.
환경설정에서 mapreduce.framework.name 속성을 기본값인 local로 설정하면 로컬 잡 실행자가 사용된다.
다음과 같이 명령행에서 드라이버를 실행할 수 있다.
% mvn compile
% export HADOOP_CLASSPATH=target/classes/
% hadoop v2.MaxTemperatureDriver -conf conf/hadoop-local.xml \
input/ncdc/micro output
또는 GenericOptionsParser가 제공하는 -fs와 -jt 옵션을 사용해도 된다.
% hadoop v2.MaxTemperatureDriver -fs file:/// -jt local input/ncdc/micro output
이 명령은 로컬 input/ncdc/micro 디렉터리의 데이터를 입력받아 로컬 output 디렉터리에 결과를 저장하는 MaxTemperatureDriver를 실행한다. 여기에서는 -fs에 로컬 파일시스템(file:///)을 설정했지만, 로컬 잡 실행자는 HDFS를 포함한 모든 파일 시스템에서 잘 작동한다. 따라서 HDFS에 몇 개의 파일만 있다면 한번 실행해 보는것도 괜찮다.
이제 로컬 파일시스템에 저장된 결과를 확인해보자.
% cat output/part-r-00000
1949 111
1950 22
6-4-2 드라이버 테스트하기
Tool을 구현한 애플리케이션을 만들면 환경설정 옵션을 유연하게 넣을 수 있는 장점도 있지만 Configuration 객체를 직접 만들어 넣을 수 있기 때문에 테스트하기에도 좋다. 로컬 잡 실행자를 이용해서 테스트용 입력 데이터를 넣고 원하는 출력 결과가 나오는지 점검하는 테스트 코드를 작성할 때 이를 활용할 수 있다.
이를 위한 두가지 방법이 존재한다. 첫번째 방법은 로컬 잡 실행자를 사용해서 로컬 파일 시스템에 있는 테스트 파일로 실행하는 것이다.
// 로컬단일 - 프로세스 잡 실행자를 사용한 MaxTemperatureDriver 테스트
@Test
public void test() throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "file:///");
conf.set("mapreduce.framework.name", "local");
conf.setInt("mapreduce.task.io.sort.mb", 1);
path input = new Path("input/ncdc/micro");
path output = new Path("output");
FileSystem fs = FileSystem.getLocal(conf);
fs.delete(output, true); // 이전 출력 삭제
MaxTemperatureDriver driver = new MaxTemperatureDriver();
driver.setConf(conf);
int exitCode = driver.run(new String[] {
input.toString(), output.toString() });
assertThat(exitCode, is(0));
checkOutput(conf, output);
}
이 테스트는 로컬 파일시스템과 로컬 잡 실행자를 사용하기 위해 fs.defaultFS와 mapreduce.framework.name을 명시적으로 설정했다. 그다음에 작은 입력 데이터로 Tool 인터페이스를 구현한 MaxTemperatureDriver를 실행한다. 테스트의 마지막 부분에서 실제 출력 결과와 예상 결과를 한 줄씩 비교하는 checkOutput() 메서드를 호출한다.
드라이버를 테스트하는 두번째 방법은 '미니' 클러스터에서 수행하는 것이다. 하둡은 MiniDFS Cluster, MiniMRCluster, MiniYARNCluster 테스트 클래스를 제공한다. 이 클래스를 이용하면 단일 프로세스 클러스터를 생성할 수 있으며, 로컬 잡 실행자와 달리 HDFS, 맵리듀스, YARN과 기술적으로 똑같은 환경에서 테스트를 할 수 있다. 미니 클러스터의 노드 매니저는 태스크를 실행하기 위해 별도의 JVM을 구동하며 이로 인해 디버깅이 매우 어려워 질 수 있다는 점을 주의해야 한다.
% hadoop jar \
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-*-tests.jar \
minicluster
미니 클러스터는 하둡 자체의 자동 테스트 도구로 자주 쓰이지만, 사용자 코드를 테스트할때도 사용할 수 있다. 하둡의 Cluster MapReduceTestCase 추상 클래스는 테스트코드 작성을 위한 원형이다. 단일 프로세스 HDFS와 YARN 클러스터의 시작과 중단은 setUp() 과 tearDown() 메서드에서 제어할수 있으며, 테스트에 필요한 Configuration 객체도 만들어준다. 서브클래스는 HDFS에 데이터를 올리고(아마도 로컬 파일에서 복사하여) 맵리듀스 잡을 실행하고 출력 결과를 확인할 때만 필요하다. 이 책의 예제 코드에 있는 MaxTemperatureDriverMiniTest 클래스를 참조하라.
이러한 방식의 테스트는 회귀 검사나 입력 극한 사례를 위한 테스트 저장소로 유용하다. 새로운 테스트 사례가 나오면 입력 파일에 추가하고 예상되는 출력 파일을 변경하면 된다.
6-5 클러스터에서 실행하기
지금까지는 작은 테스트 데이터셋으로 프로그램이 제대로 실행되는 것을 확인했다. 이제 하둡 클러스터에서 전체 데이터셋으로 시도해보자.
6-5-1 잡 패키징
로컬 잡 실행자는 잡을 실행할 때 단일 JVM을 사용하므로 잡에 필요한 모든 클래스가 로컬의 클래스 경로에 존재하면 문제없이 잘 작동한다. 하지만 분산환경은 조금더 복잡하다. 잡을 시작할때 필요한 모든 클래스를 잡 JAR 파일에 패키징해서 클러스터로 보내야 한다. 하둡은 (JobConf 또는 Job의) setJarByClass() 메서드에 지정된 클래스 집합을 모두 포함하고 있는 드라이버의 클래스경로에서 잡 JAR 파일을 찾는다. 대신 JAR파일의 경로를 명시적으로 지정하고 싶으면 setJar() 메서드를 사용하면 된다. JAR 파일의 경로는 로컬이나 HDFS 파일 경로일 수 있다.
잡 JAR 파일은 앤트나 메이븐 같은 빌드 도구를 사용해서 쉽게 생성할수 있다.
POM을 이용하여 다음과 같이 메이븐 명령어를 실행하면 프로젝트 디렉터리에 컴파일된 클래스를 모두 포함한 hadoop-examples.jar 파일이 생성된다.
% mvn package -DskipTests
JAR 파일에 잡이 하나만 있을 때는 JAR 파일의 manifest에 메인 클래스를 지정할 수 있다. manifest에 메인 클래스를 지정하지 않았다면 반드시 명령행에 지정해주어야 한다.
의존 JAR 파일은 잡 JAR 파일의 lib 서브디렉터리에 패키징하거나 뒤에서 다룰 다른 방식을 적용해도 된다. 이와 비슷하게 리소스 파일은 classes 서브디렉터리에 패키징한다. 패키징하는 방식은 자바 웹 애플리케이션 아카이브(WAR) 파일과 유사하지만, JAR파일은 WEB-INF/lib 서브디렉터리에, WAR 파일의 클래스는 WEB-INF/classes 서브디렉터리에 존재한다.
클라이언트 클래스 경로
hadoop jar<jar>로 지정하는 클라이언트의 클래스 경로는 다음과 같이 구성한다.
- 잡 JAR 파일
- 잡 JAR 파일의 lib 디렉터리에 있는 모든 JAR 파일과 classes 디렉터리
- HADOOP_CLASSPATH에 정의한 클래스경로
이는 가끔 로컬 잡 실행자를 잡 JAR 파일 없이 실행(hadoop CLASSNAME) 할 때 HADOOP_CLASSPATH에 의존 클래스와 라이브러리를 지정해야 하는 이유를 잘 설명해준다.
태스크 클래스 경로
클러스터(의사분산 모드 포함)에서 맵과 리듀스 태스크는 개별 JVM으로 실행되며 클래스경로로 HADOOP_CLASSPATH를 지정해도 소용없다. HADOOP_CLASSPATH는 클라이언트 측 설정이며 따라서 잡을 제출하는 드라이버 JVM의 클래스경로에만 해당되기 때문이다.
대신 태스크 클래스 경로는 다음과 같이 구성된다.
- 잡 JAR 파일
- 잡 JAR 파일의 lib 디렉터리에 있는 모든 JAR 파일과 classes 디렉터리
- -libjars 옵션이나 DistributedCache 혹은 Job의 addFileToClassPath() 메서드를 사용해서 분산 캐시에 추가한 모든 파일
의존 라이브러리 패키징
클라이언트와 태스크의 클래스경로를 지정하는 다양한 방식이 있고, 각 방식에 따라 잡의 의존 라이브러리를 포함하는 옵션이 있다.
- 라이브러리를 푼 후 잡 JAR에 넣고 다시 패키징한다.
- 잡 JAR의 lib 디렉터리에 라이브러리를 패키징한다
- 잡 JAR와 다른 위치에 라이브러리를 두고, 이를 HADOOP_CLASSPATH와 -libjars를 이용해서 클라이언트의 클래스 경로와 태스크의 클래스경로에 각각 추가한다.
분산캐시를 사용하는 마지막 옵션은 의존 라이브러리를 잡 JAR 안에 다시 넣을 필요가 없기 때문에 빌드 관점에서 가장 간단하다. 또한 여러 태스크를 수행할 때 각 노드에 파일이 캐시되기 때문에 클러스터에 전송할 JAR파일의 개수를 줄일수 있다.
태스크 클래스 경로의 우선순위
사용자JAR 파일은 클라이언트의 클래스경로와 태스크 클래스경로에 마지막에 추가되므로, 하둡이 사용자 코드에서 사용하는 라이브러리와 다르거나 호환되지 않는 버전을 사용하면 하둡의 내장 라이브러리와 충돌할 가능성이 존재한다. 그래서 때론 사용자 클래스가 먼저 선택되도록 태스크 클래스경로를 제어할 필요가 있다. 먼저 클라이언트에서는 HADOOP_USER_CLASSPATH_FIRST 환경변수를 true로 설정하여 사용자 클래스경로를 하둡의 클래스경로 검색 순서의 맨 앞에 강제로 둘 수 있다. 마찬가지로 태스크 클래스경로에서는 mapreduce.job.user.classpath.first 속성을 true로 설정하면 된다. 이러한 옵션을 설정하면 하둡 프레임워크 의존성을 위해 로딩할 클래스가 변경될 수 있고 따라서 잡 제출이나 태스크가 실패할 가능성이 있으므로 주의해야 한다.
6-5-2 잡 구동하기
잡을 구동하기 위해 드라이버를 실행할때 -conf 옵션(-fs와 -jt 옵션도 동일한 목적으로 사용됨)으로 잡을 실행할 클러스터를 지정해야 함
% unset HADOOP_CLASSPATH
% hadoop jar hadoop-examples.jar v2.MaxTemperatureDriver \
-conf conf/hadoop-cluster.xml input/ncdc/all max-temp
Job의 waitForCompletion() 메서드는 잡을 구동하고 진행 상황을 주기적으로 보고하는 일을 맡고 있으며, 맵과 리듀스의 처리과정에 변화가 생기면 이를 요약하여 출력한다.다음은 출력 결과로, 보기 쉽게 하기 위해 일부 행을 삭제했다.
6-5-3 맵리듀스 웹 UI
하둡은 잡에 대한 정보를 보여주는 웹 UI를 제공한다. 수행중인 잡의 진행상황을 살펴보거나 완료된 잡의 통계 정보와 로그를 찾을 때 유용하다.http://resource-manager-host:8088/에서 UI를 볼 수 있다.
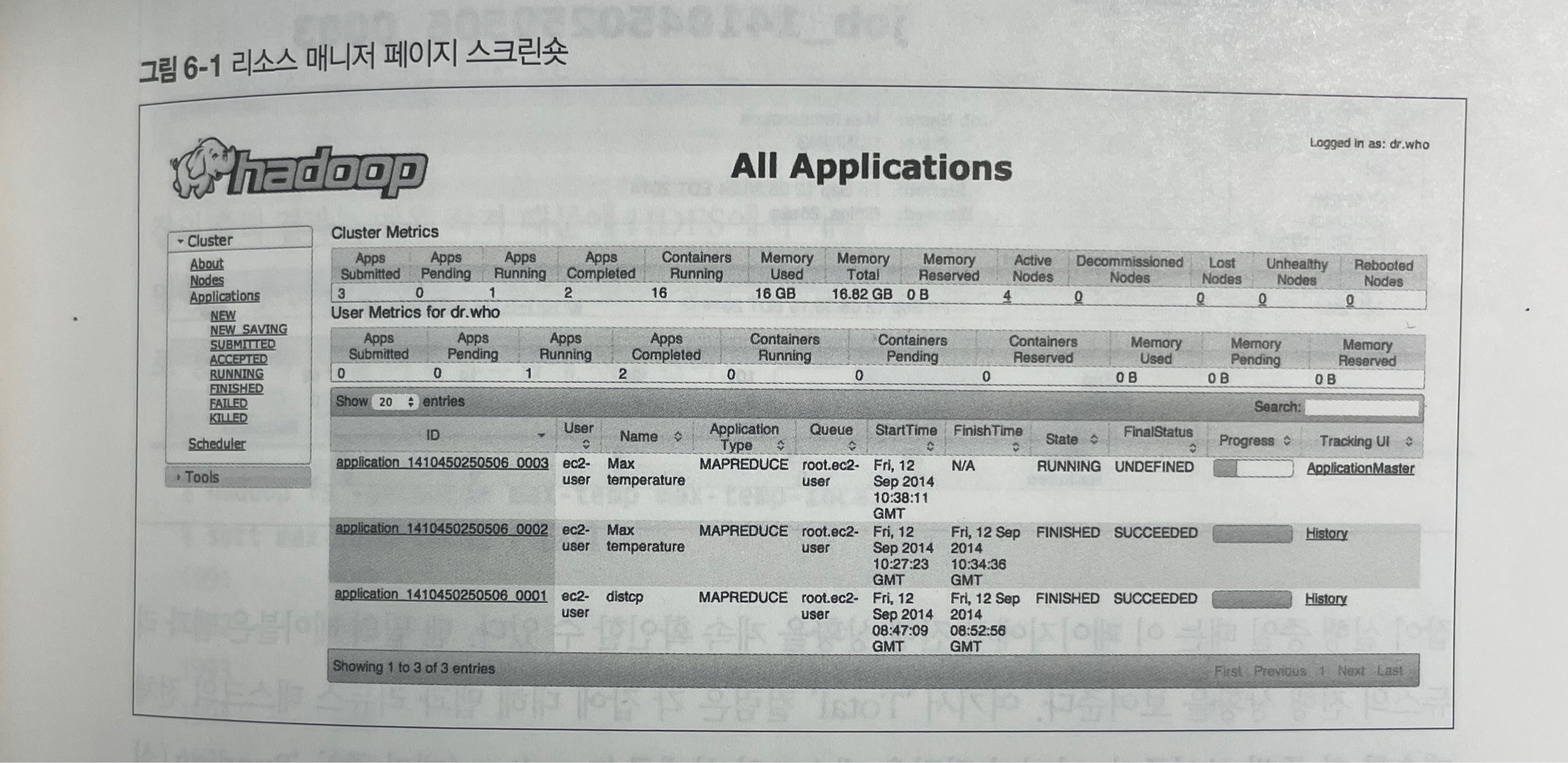
리소스 매니저 페이지
리소스 매니저 홈페이지의 스크린숏이다. '클러스터 메트릭스'부분에서 클러스터의 요약정보를 볼 수 있다. 여기에는 클러스터(그리고 다양한 상태)에서 현재 실행중인 애플리케이션의 개수, 클러스터 가용 자원의 수량(전체 메모리), 노드 매니저 정보가 포함되어 있다.
메인 테이블은 클러스터에서 완료되었거나 현재 실행 중인 모든 애플리케이션을 보여준다. 그리고 특정 애플리케이션을 찾을 수 있도록 검색 창을 제공한다. 메인 화면은 페이지당 100개의 애플리케이션을 보여준다. 리소스 매니저는 10,000개 완료된 애플리케이션을 메모리 상에 유지한다. 리소스 메니저에서 삭제된 애플리케이션은 잡 히스토리 페이지에서 조회할 수 있다. 잡 히스토리는 영속적이므로 리소스 매니저에서 예전에 실행했던 잡도 확인할 수 있다.
맵리듀스 잡 페이지
'Tracking UI'를 클릭하면 애플리케이션 마스터의 웹 UI로 이동한다. 애플리케이션의 타입이 맵리듀스라면 맵리듀스 잡 페이지로 이동한다.

잡이 실행중일때는 이페이지에서 진행 상황을 계속 확인할 수 있다. 맨 밑의 테이블은 맵과 리듀스의 진행 상황을 보여준다. 여기서 'Total' 컬럼은 각 잡에 대해 맵과 리듀스 태스크의 전체 개수를 한줄씩 보여준다. 나머지 컬럼은 태스크의 상태를 'Pending(대기중)', 'Running(실행 중)', 'Complete(실행 성공)' 로 구분하여 보여준다.
이 테이블의 마지막 부분은 맵 또는 리듀스 태스크에 대해 실패했거나 죽은 태스크 시도의 전체 개수를 보여준다. 투기적 실행 중복, 태스크를 실행하던 노드의 죽음, 사용자의 강제 종료로 태스크 시도가 실패했을 때는 killed로 표시된다.
탐색기에는 유용한 링크도 있다. 예를 들어 'Configuration' 링크를 클릭하면 잡을 실행할 때 영향을 미치는 모든 속성과 값을 가진 통합 설정 파일로 이동한다. 어떤 속성 값을 확인하고 싶다면 해당 설정 파일을 클릭하면 된다.
6-5-4 결과 얻기
잡이 완료되면 다양한 방법으로 그 결과를 얻을수 있다. 각 리듀서는 하나의 출력 파일을 생성하기 때문에 max-temp 디렉터리에는 part-r-00000부터 part-r-00029까지 명명된 30개의 부분 파일이 있다.
잡의 출력 결과는 매우 작기 때문에 HDFS에서 개발 머신으로 쉽게 복사할 수 있다. hadoop fs 명령의 -getmerge 옵션은 원본으로 지정된 디렉터리에 있는 모든 파일을 가져와서 하나의 파일로 병합한 후 로컬 파일 시스템에 저장한다.
% hadoop fs -getmerge max-temp max-temp-local
% sort max-temp-local | tail
1991 607
1992 605
1993 567
1994 568
1995 567
1996 561
1997 565
1998 568
1999 568
2000 568
리듀스 출력 파티션은 정렬되지 않았기 때문에 출력하기전에 sort 명령으로 결과를 정렬했다. R, 스프레드시트,관계형 데이터베이스와 같은 분석도구로 맵리듀스의 결과를 전달하기 전에 약간의 후처리를 하는 것은 흔한일이다.
출력 결과가 적다면 -cat 옵션을 사용해서 출력 파일의 전체 내용을 콘솔에 출력하는 방법도 있다.
% hadoop fs -cat max-temp/*
자세히 살펴보면 일부 결과가 이상하다는 것을 알 수 있다. 예를 들어 여기선 보이지 않지만 1951년의 최고 기온은 590도다 그렇다면 이러한 결과를 초래한 원인을 어떻게 찾을수 있을까? 혹시 입력 데이터가 손상되었거나 프로그램에 버그가 있나??
6-5-5 잡 디버깅
디버깅 과정에서 생성되는 로그 데이터의 양이 매우 클때는 선택할수 있는 몇가지 대안이 있다. 하나는 표준 에러 대신 맵의 출력으로 필요한 정보를 내보낸 후 리듀스 태스크에서 분석과 집계를 하는 것이다. 이러한 접근 방식은 프로그램의 구조적인 변경이 필요하므로 다른기법을 먼저 고려해보자. 또 다른 대안은 잡이 생성하는 로그를 분석하는 프로그램을 맵리듀스로 직접 작성하는 것이다.
비정상적인 결과의 원인이 되는 원본 데이터를 찾기 위한 것이므로 리듀서가 아닌 매퍼에 디버깅 코드를 추가해봤다.
public class MaxTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
enum Temperature {
OVER_100
}
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
int airTemperature = parser.getAirTemperature();
if (airTemperature > 1000) {
System.err.println("Temperature over 100 degrees for input: " + value);
context.setStatus("Detected possibly corrupt record: see logs.");
context.getCounter(Temperature.OVER_100).increment(1);
}
context.write(new Text(parser.getYear()), new IntWritable(airTemperature));
}
}
}
기온이 100도 이상이면 Context의 setStatus() 메서드를 사용하여 맵의 상태 메세지를 변경하고, 의심스러운 행을 표준 출력으로 내보낸다. 또한 자바에서 enum 타입의 필드로 표현되는 카운터를 증가시킨다. 이 프로그램에서는 OVER_100 필드를 정의하여 100도 이상의 기온을 가진 레코드 수를 세었다.
이렇게 수정하고 코드를 다시 컴파일 한 후 JAR 파일을 생성하고 잡을 다시 실행하자. 그리고 잡이 실행되면 태스크 페이지로 다시 가보자.
태스크와 태스크 시도 페이지
잡 페이지에는 잡의 태스크를 더욱 자세히 보여주기 위한 몇개의 링크가 있다. 예를 들어 'Map' 링크를 클릭하면 모든 맵 태스크의 정보를 보여주는 페이지로 이동한다 스크린숏은 태스크의 'Status' 컬럼에 디버깅 문장에서 지정한 메세지를 보여주는 잡 페이지다.

6-5-6 하둡로그
하둡은 다양한 사용자를 위해 여러장소에 로그를 생성한다.
| 로그 | 주 사용자 | 설명 | 추가 정보 |
| 시스템 데몬 로그 | 관리자 | 각 하둡 데몬은 로그파일(log4j를 사용하여)과 표준 출력과 에러를 결합한 파일을 생성한다. 이는 HADOOP_LOG_DIR 환경변수에 지정한 디렉터리에 쓰인다 | 10.3.2절의 '시스템 로그 파일'과 11.2.1절 '로깅' |
| HDFS 감사 로그 | 관리자 | HDFS와 관련된 모든 요청에 대한 로그로, 기본적으로 사용하지 않는다. 무엇으로 설정되든 네임노드 로그에 쓰인다. | 11.1.3절'감사 로깅' |
| 맵리듀스 잡 히스토리 로그 | 사용자 | 잡을 실행하는 과정에 발생하는 이벤트(태스크 완료와 같은)로그다. HDFS 내의 한곳에 모아서 저장된다 | 6.5.3 절의 '잡 히스토리' 글상자 |
| 맵리듀스 태스크 로그 | 사용자 | 각 태스크 자식 프로세스는 log4j를 사용하는 로그 파일(syslog로 불리는), 표준 출력(stdout)으로 보낸 데이터 파일, 표준 에러(stderr)를 위한 파일을 생성한다. 이는 YARN_LOG_DIR 환경변수에 지정한 디렉터리의 userlogs 서브디렉터리에 쓰인다. | 본절 |
YARN은 완료된 애플리케이션의 모든 태스크 로그를 가져온 후 병합하여 HDFS에 있는 기록 보관용 컨테이너 파일에 저장하는 로그 통합 서비스를 제공한다. yarn.log-aggregation-enable 속성을 true로 설정하여 이 서비스를 활성화했으면 태스크 시도 웹 UI에 있는 로그 링크를 클릭하거나 mapred job - logs 명령을 실행하여 원하는 태스크 로그를 볼 수 있다.
로그 통합 기능은 기본적으로 비활성화되어 있다. 이때는 노드 매니저의 웹 UI인 http://node-manager-host:8042/logs/userlogs에서 태스크 로그를 볼 수 있다.
이처럼 로그파일을 기록하는 것은 매우 직관적이다. 즉, 표준 출력이나 표준 에러에 쓰는 모든 것은 관련된 로그파일에 기록된다. 물론 스트리밍의 표준 출력은 맵과 리듀스 출력에 사용되므로 표준 출력 로그에는 나타나지 않는다.
자바에서는 아파치 공통 로깅 API(또는 실제 log4j에 기록할 수 있는 로깅 API라면)를 사용하여 태스크의 syslog파일에 기록할 수 있다.
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.mapreduce.Mapper;
public class LoggingIdentityMapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
extends Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
private static final Log LOG = LogFactory.getLog(LoggingIdentityMapper.class);
@Override
@SuppressWarnings("unchecked")
public void map(KEYIN key, VALUEIN value, Context context)
throws IOException, InterruptedException {
// 표준출력 파일에 로깅
System.out.println("Map key: " + key);
// syslog 파일에 로깅
LOG.info("Map key: " + key);
if (LOG.isDebugEnabled()) {
LOG.debug("Map value: " + value);
}
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
기본 로그 수준은 INFO이기 때문에 DEBUG 수준의 메세지는 syslog 태스크 로그파일에 나타나지 않는다. 그러나 가끔은 이런 메세지가 필요할 때가 있다. 이를 위해서는 mapreduce.map.log.level이나 mapreduce.reduce.log.level 속성을 적절한 값으로 변경해야 한다. 예를 들어 로그에서 맵의 값을 보기 위해서는 다음과 같이 매퍼를 설정하면 된다.
% hadoop jar hadoop-examples.jar LoggingDriver -conf conf/hadoop-cluster.xml \
-D mapreduce.map.log.level=DEBUG input/ncdc/sample.txt logging-out
태스크 로그의 보관 기간과 용량을 관리하기 위한 설정이 있다. 기본적으로 로그는 3시간 후에 삭제된다. 또한 mapreduce.task.userlog.limit.kb 속성으로 각 로그파일의 최대 크기를 설정할 수 있다. 이 속성의 기본값은 0이므로 크기 제한은 없다.
6-5-7 원격 디버깅
어떤 태스크 하나가 실패했을 때 에러를 진단하기 위한 로그 정보가 충분하지 않다면 이러한 태스크를 위한 디버거를 하나 만들어서 실행하고 싶을 것이다. 클러스터에서 잡을 실행할 때는 어느 노드가 입력 데이터셋의 어떤 부분을 처리할지 모르기 때문에 실패하기 전에 디버거를 미리 설정할 수 없는 어려움이 있다. 하지만 이러한 문제를 해결할 수 있는 옵션이 몇 개 있다.
- 로컬에서 실패를 재현하기
- 특정 입력 데이터에 대해 지속적으로 실패하는 태스크가 있을 수 있다. 태스크 실패를 일으키는 파일을 로컬에 내려받은 후 로컬에서 잡을 실행하면 로컬에서 문제를 재현할 수 있다. 가능하면 자바의 VisualVM과 같은 디버거를 사용하라.
- JVM 디버깅 옵션 사용하기
- 실패의 주된 이유는 태스크 JVM의 자바 메모리 부족 때문이다. mapred.child.java.opts 속성에 -xx :- HeapDumpOnOutOfMemoryError -XX : HeapDumpPath= /path/to/dumps 옵션을 추가하면 된다. 이 설정은 jhat이나 이클립스 메모리 분석기와 같은 도구로 사후 분석이 가능한 힙 덤프를 생성한다. 이 JVM 옵션은 mapred.child.java.opts로 지정된 기존 메모리 설정의 뒷부분에 추가해야 한다.
- 테스크 프로파일링 사용하기
- 자바 프로파일러는 JVM에 대한 상당한 통찰력을 제공하며, 하둡은 잡의 일부 태스크에 대한 프로파일링 기법을 제공한다.
사후 분석을 위해서는 실패한 태스크 시도의 중간 파일을 보관하는 것이 유용하다. 특히 태스크의 작업 디렉터리에 생성된 추가 덤프나 프로파일 파일이 중요하다. mapreduce.task.files.preserve.failedtasks 속성을 true로 설정하면 실패한 태스크의 파일을 보관할 수 있다.
실패하지 않은 태스크도 분석할 필요가 있기 때문에 원한다면 성공한 태스크의 중간 파일도 보관할 수 있다. 정규표현식으로 mapreduce.task.files.preserve.filepattern 속성에 파일을 보관하고 싶은 태스크의 ID를 지정하면 된다.
디버깅 속성인 yarn.nodemanager.delete.debug-delaysec은 태스크 컨테이너 JVM을 구동하기 위해 사용되는 스크립트와 같은 로컬 태스크 시도 파일을 삭제하지 않고 대기하는 시간을 지정하는 유용한 속성이다. 예를 들어 클러스터에 적당히 큰 값(600, 즉 10분)을 설정하면 파일이 삭제되기 전에 충분히 살펴볼 수 있다.
태스크 시도 파일을 조사하기 위해서는 태스크가 실패한 노드에 로그를 남긴 후 태스크 시도와 관련된 디랙터리를 찾아야 한다.
이 디렉터리는 mapreduce.cluster.local.dir 속성에 설정한 로컬 맵리듀스 디렉터리 중 한곳에 존재할 것이다.
이 속성이 콤마로 구분된 디렉터리 목록이면 특정 태스크 시도와 관련된 디렉터리를 찾기 위해서는 모든 디렉터리를 살펴봐야 한다. 태스크 시도와 관련된 디렉터리는 다음 위치에 존재한다.
mapreduce.cluster.local.dir/usercache/user/appcache/application-ID/output/task-attempt-ID
6-6 잡 튜닝하기
잡이 제대로 작동하면 개발자들은 '어떻게 하면 더욱 빠르게 실행할 수 있을까?' 라는 고민을 한다.
성능 문제와 관련이 있는 하둡 특유의 유력한 용의자가 있다. 태스크 수준에서 프로파일링이나 최적화를 시도하기 전에 아래 표에 있는 점검 목록을 순서대로 실행해 보는 것이 좋다.
| 영역 | 모범 사례 | 추가정보 |
| 매퍼 수 | 매퍼가 얼마나 오랫동안 수행되고 있는가? 만약 평균 몇 초 내로 수행된다면 더 적은 수의 매퍼로 더 오래 실행할 수 있는 방법이 있는지(경험상 1분 내외로)확인해보길 권한다. 이것이 가능한 정도는 사용중인 입력 포맷에 달려 있다. | '작은 파일과 CombineFileInputFormat' |
| 리듀서 수 | 두개 이상의 리듀서를 사용 중인지 확인해보라. 리듀스 태스크는 경험상 5분 내외로 실행되며 최소 하나의 의미 있는 데이터 블록을 생성하길 권장한다. | '리듀서 수 선택'글상자 |
| 컴바이너 | 셔플을 통해 보내는지 데이터양을 줄이기 위해 컴바이너를 활용할 수 있는지 확인해 보라. | '컴바이너 함수' |
| 중간 데이터 압축 | 맵 출력을 압축하면 잡 실행 시간을 거의 대부분 줄일 수 있다. | '맵 출력 압축' |
| 커스텀 직렬화 | 커스텀 Writable 객체나 비교기를 사용하고 있다면 RawComparator를 구현했는지 반드시 확인해라. | '성능 향상을 위해 RawComparator 구현하기' |
| 셔플 튜닝 | 맵리듀스 셔플은 메모리 관리를 위해 대략 12개 정도의 튜닝 인자를 제공하는데, 이는 성능을 조금이라도 더 향상시키는데 도움을 줄 수 있다. | '설정 조절' |
6-7 맵리듀스 작업 흐름
지금까지 맵리듀스로 프로그램을 작성하는 기법을 살펴봤다. 그러나 맵리듀스 모델로 데이터 처리 문제를 해결하는 방법은 아직 고려하지 않았다.데이터 처리가 더 복잡해지면 복잡한 맵과 리듀스 함수를 만드는 것보다는 맵리듀스 잡을 더 많이 만드는 것이 더 좋은 방법이다. 다시말해, 잡을 복잡하게 만들기보다는 잡을 더 많이 만드는 것이 좋다.
그리고 매우 복잡한 문제는 맵리듀스 대신 피그, 하이브, 캐스케이딩, 크런치, 스파크와 같은 고수준 언어를 사용하는 것이 좋다.
이러한 도구를 사용할 때 당장 얻을수 있는 장점은 맵리듀스 잡으로 변환하는 작업을 하지 않아도 되므로 분석 작업에만 집중할 수 있다는 것이다.
6-7-1 맵리듀스 잡으로 문제 분해하기
좀더 복잡한 문제를 맵리듀스 작업 흐름으로 변환하는 사례를 하나 살펴보자.
기상 관측소 및 날짜별로 전체 연도의 일일 최고 기온의 평균값을 계산해보자. 예를 들어 기상 관측소 029070-99999의 1월 1일의 평균값을 계산한다면 1901년 1월 1일, 1902년 1월 1일, ... 이런식으로 2000년 1월 1일까지의 일일 최고 기온을 모아서 평균을 구하는 것이다.
맵리듀스로 어떻게 계산할 수 있을까? 두 단계로 나누어 계산하는 것이 가장 자연스럽다.
1. 기상 관측소 - 날짜 쌍 별로 최고 기온을 계산한다.
여기서 맵리듀스 프로그램은 단일 필드인 연도 대신 (기상관측소-날짜) 쌍의 복합 필드로 키를 지정한 점을 제외하고는 앞에서 설명한 최고 기온 프로그램과 다른 점이 없다.
2. 기상관측소 -일 -월 키로 최고 기온의 평균을 계산한다.
매퍼는 이전 잡의 출력 레코드(기상관측소-날짜, 최고 기온)를 가져와서 연도를 제거한 (기상관측소-일-월,최고 기온)레코드를 내보낸다. 그 다음에 리듀스 함수는 (기상관측소-일-월) 키에 대한 최고 기온의 평균값을 구한다.
앞에서 언급한 기상관측소에 대한 첫번째 단계의 출력은 다음과 같다.
029070-99999 19010101 0
029070-99999 19020101 -94
...
앞에 두 필드는 키를 구성하고, 마지막 컬럼은 특정 기상관측소와 날짜에 대한 최고 기온을 의미한다. 두 번째 단계는 전체 연도를 대상으로 일일 최곳값의 평균을 구하는 것이다.
029070-99999 0101 -68
이는 한 세기에 걸친 기상관측소 209070-99999의 1월 1일 최고 기온의 평균이 -6.8도 임을 의미한다.
이를 한 단계의 맵리듀스로 계산할 수도 있지만 프로그래머의 작업이 더 많아지게 된다.
맵리듀스 단계를 줄이거나 늘리는 것은 매퍼와 리듀서의 구성 및 유지보수와 관련이 있다. 5부 '사례 연구'에서는 맵리듀스로 해결할 수 있는 현실의 문제를 다루며 각 사례에서 데이터 처리 태스크는 두 개 이상의 맵리듀스 잡으로 구현된다. 각 장의 세부 내용을 보면 문제 처리 과정을 맵리듀스 작업 흐름으로 분해하는 방법에 대한 더 좋은 아이디어를 얻을 수 있다.
맵과 리듀스 함수로 지금까지 본 것보다 더 좋은 구성을 만들 수 있다. 매퍼는 주로 입력 포맷 파싱, 프로젝션, 필터링 을 수행한다.
지금까지 본 매퍼는 이런 기능을 단일 매퍼에서 구현했다. 하지만 각 기능을 독립적인 매퍼로 분리하고 하둡이 제공하는 ChainMapper 라이브러리 클래스를 사용하여 이들을 단일 매퍼로 연결하는 방법도 있다. ChainReducer와 결합하면 단일 맵리듀스 잡에서 매퍼 체인을 실행한 후 리듀서나 다른 매퍼 체인도 실행할 수 있다.
6-7-2 JobControl
맵리듀스 작업 흐름에 두 개 이상의 잡이 존재한다면'잡을 순서대로 실행하도록 관리하려면 어떻게 해야 할까?' 라는 의문점이 생길 것이다. 몇 가지 접근 방법이 있는데, 잡의 작업 흐름이 선형 체인 형태인지 아니면 매우 복잡한 방향성 비순환 그래프(DAG)인지에 따라 큰 차이가 있다.
선형 체인의 가장 간단한 접근 방법은 잡을 하나씩 순차적으로 실행하는 것으로, 현재 잡이 성공적으로 완료될 때까지 기다린 후 다음 잡을 실행하는 것이다.
JobClient.runJob(conf1);
JobClient.runJob(conf2);
잡이 실패하면 runJob() 메서드는 IOException을 던지고 따라서 파이프라인에 있는 다음 잡은 실행되지 않는다. 애플리케이션에 따라 다르지만 예외 상황을 적절히 처리하고 이전 잡에서 생성된 중간 파일을 삭제하길 바랄 수도 있다.
이방식은 새로운 맵리듀스 API와 유사하지만 Job의 waitForCompletion() 메서드의 Boolean 반환값을 조사할 필요가 있다는 점은 다르다.
선형 체인보다 더 복잡한 작업 흐름을 조율할 때 도움이 되는 라이브러리가 있다. org.apache.mapreduce.jobcontrol 패키지에 있는 JobControl 클래스가 가장 단순하다. JobControl 객체는 실행할 잡의 순서를 그래프로 표현한다. 잡 환경설정을 추가한 후 JobControl 객체에 잡 사이의 종속관계를 알려주면 된다. 단일 스레드에서 JobControl을 실행하면 잡의 종속관계에 따라 잡을 순차적으로 실행한다. 진행 상황을 주기적으로 확인할 수 있으며 잡이 완료되면 모든 잡의 상태를, 실패하면 관련 에러를 질의할 수 있다.
어떤 잡이 실패하면 JobControl은 이 잡에 종속된 다음 잡을 실행하지 않는다.
6-7-3 아파치 오지
아파치 오지는 종속관계가 있는 여러 잡을 작업흐름에 따라 실행해주는 시스템이다. 오지는 두 개의 중요부분으로 나누어진다. 워크플로 엔진은 다른 형태의 하둡잡 을 구성하는 작업 흐름을 저장하고 실행하며, 코디네이터 엔진 은 미리 정의된 일정과 데이터 가용성을 기반으로 워크플로 잡을 실행한다. 오지는 확장 가능하도록 설계되었고 하둡 클러스터 내에 수천 개의 워크플로를 시의 적절하게 실행하도록 관리한다.
오지는 실패한 워크플로를 다시 실행할 때 성공한 부분에 대해서는 다시 실행하지 않기 때문에 효율적이며 따라서 시간 낭비도 없다. 복잡한 배치 시스템을 다뤄본 사람이라면 시스템 정지나 장애로 누락된 잡을 찾는 일이 얼마나 어려운지 잘 알고 있기 때문에 이러한 기능에 대해 매우 만족할 것이다. 심지어 하나의 데이터 파이프라인으로 표현된 코디네이터 애플리케이션은 한 묶음 으로 패키징되어 함께 실행될 수도 있다.
잡을 제출한 클라이언트 머신에서 실행되는 JobControl과 달리 오지는 클러스터에서 실행되는 서비스로, 클라이언트는 즉시 혹은 나중에 실행하라는 워크플로 명세를 제출할 수 있다. 문법만 보면 오지의 워크플로는 액션노드 와 제어흐름 노드 로 이루어진 DAG다.
액션 노드는 HDFS에 저장된 파일을 옮기거나 맵리듀스, 스트리밍, 피그, 하이브 잡을 실행하거나 스쿱 임포트를 수행하거나 쉘 스크립트나 자바 프로그램을 실행하는 등 워크플로의 태스크를 수행한다.제어흐름 노드는 조건부 로직과 같은 구문을 통해 액션 사이의 워크플로 실행을 관장한다. 따라서 액션노드의 결과에 따라 뒤에 실행되는 워크플로의 가지가 달라질 수 있다. 워크플로가 완료되면 오지는 HTTP 콜백을 만들어 워크플로 상태를 클라이언트에 통지한다. 물론 워크플로에서 액션노드를 시작하거나 종료할 때 마다 콜백을 받는것도 가능하다.
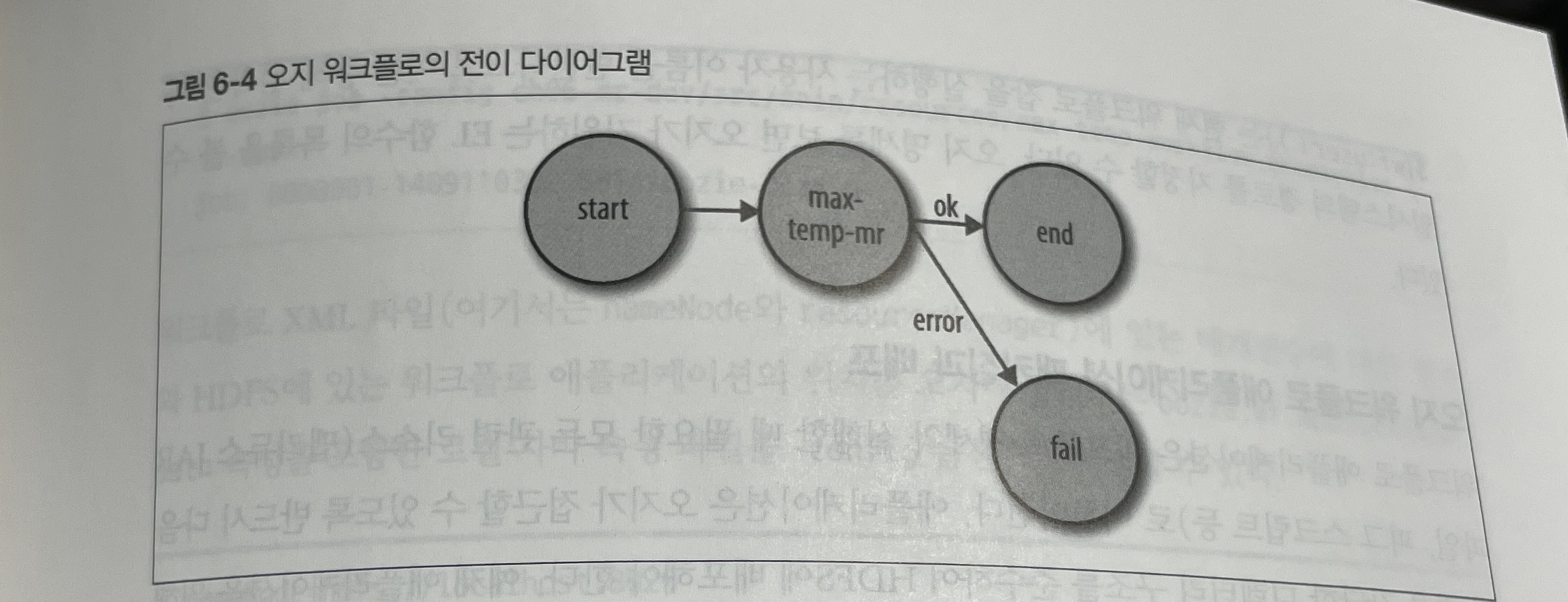
워크플로는 반드시 하나의 start 노드와 하나의 end 노드를 가져야 한다. 워크플로 잡이 시작되면 start 노드가 가리키는 노드로 전이된다. 워크플로 잡은 end 노드에 도달하면 종료된다. 그러나 워크플로 잡이 kill 노드에 도달하면 실패한 것으로 간주하고 워크플로 명세의 메세지 항목에서 적절한 에러 메세지를 출력한다.
워크플로 명세의 대부분은 map-reduce 액션을 기술하는 것이다. map-reduce 액션의 처음 두 항목인 job-tracker와 name-node는 잡을 제출할 YARN 리소스 매니저와 입출력 데이터를 위한 네임노드를 지정하는데 사용된다. 이 두 값은 특정 클러스터에 고정되어 있지 않도록 매개변수로 처리했다. 나중에 살펴보겠지만 이 매개변수는 제출시점에 워크플로 잡 속성으로 지정된다.
선택사항인 prepare 항목은 맵리듀스 잡이 실행되기 전에 실행된다.예제에서는 디렉터리를 삭제하는 용도로 사용되었다. 잡을 실행하기 전에 출력 디렉터리가 고정된 상태임을 보장할 수 있으면 오지는 잡이 실패해도 안심하고 액션을 다시 실행할 수 있다.
configuration 항목 안에 내부 항목으로 맵리듀스 잡이 정의되어 있다. 내부 항목은 하둡 환경 설정을 이름-값 쌍으로 지정할 수 있다. 맵리듀스 configuration 부분은 맵리듀스 프로그램을 실행하기 위해 사용했던 드라이버 클래스를 서술적으로 대채한것으로 보면 된다.
워크플로 명세의 여러 곳에서 JSP 표현 언어 (EL) 문법의 장점을 제대로 활용한 것을 볼 수 있다. 오지는 워크플로와 상호작용할 수 있는 여러 함수를 제공한다. 예를들어 ${wf:user()}는 현재 워크플로 잡을 실행하는 사용자 이름을 반환하므로 이를 통해 정확한 파일 시스템 의 경로를 지정할 수 있다. 오지 명세를 보면 오지가 지원하는 EL함수의 목록을 볼 수 있다.
오지 워크플로 애플리케이션 패키징과 배포
워크플로 애플리케이션은 워크플로 명세와 실행할 때 필요한 모든 관련 리소스 로 이루어 진다. 애플리케이션은 오지가 접근할 수 있도록 반드시 다음과 같은 간단한 디렉터리 구조를 준수하여 HDFS에 배포해야 한다.
오지 워크플로 잡 실행하기
애플리케이션의 워크플로 잡을 실행하는 방법을 살펴보자. 이를 위해 오지 서버와 통신하는 클라이언트 프로그램인 oozie 명령행 도구를 사용할 것이다. 편의를 위해 OOZIE_URL 환경변수에 oozie 명령을 수행할 오지 서버를 지정했다.
% export OOZIE_URL=http://localhost:11000/oozie
오지 도구에는 많은 하위 명령이 있다. 여기서는 워크플로 잡을 실행할 때 -run 옵션으로 job 하위 명령어도 함께 사용한다.
% oozie job -config ch06-mr-dev/src/main/resources/max-temp-workflow.properties \ -run
job: 000001-140911033236814-oozie-oozi-W
워크플로 XMl 파일에 있는 매개변수에 대한 정의와 HDFS에 있는 워크플로 애플리케이션의 위치를 오지에 알려주는 oozie.wf.application.path 속성을 포함한 로컬 자바 속성 파일을 -config 옵션으로 지정할 수 있다.
nameNode=hdfs://localhost:8020
resourceManager=localhost:8032
oozie.wf.application.path=${nameNode}/user/${user.name}/max-temp-workflow
앞에서 -run 옵션을 추가한 명령을 실행하여 얻은 잡의 ID를 -info 옵션으로 지정하면 워크플로 잡의 상태에 대한 정보를 얻을 수 있다.
% oozie job -info 000001-140911033236814-oozie-oozi-W출력 결과를 보면 RUNNING, KILLED, SUCCEEDED와 같은 잡의 상태를 알수 있다 오지 웹 UI 에서 이러한 정보를 확인할 수 있다.
잡이 성공하면 기존 방식대로 결과를 확인할 수 있다.
% hadoop fs -cat output/part-*
1949 111
1950 22이 예제는 오지 워크플로를 대충 살펴본것이다. 오지 웹사이트 문서를 보면 복잡한 워크플로를 생성하는 방법과 코디네이터 잡을 작성하고 실행하는 자세한 정보를 얻을 수 있다.
'책&스터디' 카테고리의 다른 글
| [하둡 완벽 가이드] - PART2 08장 맵리듀스 타입과 포맷 (0) | 2026.02.08 |
|---|---|
| [하둡 완벽 가이드] - PART2 07장 맵리듀스 작동 방법 (0) | 2026.02.07 |
| [하둡 완벽 가이드] - PART1 05장 하둡 I/O (0) | 2026.02.04 |
| [하둡 완벽 가이드] - PART1 04장 YARN (0) | 2026.02.03 |
| [하둡 완벽 가이드] - PART1 03장 하둡 분산 파일시스템 HDFS (1) | 2026.02.02 |