

프로그래머스에 SELECT문을 모두 풀어보았다. 마지막문제쯤 되었을때
GENOTYPE, CTE로 문제풀이와 오답관련되서 어려웠던 문제들과, 풀이방식에 대해 정리해보려고 한다.
GENOTYPE, CTE에 대한 개념도 따로 적어두도록 하겠다.
Programmers - 특정형질을 가지는 대장균 찾기
https://school.programmers.co.kr/learn/courses/30/lessons/301646
프로그래머스
SW개발자를 위한 평가, 교육의 Total Solution을 제공하는 개발자 성장을 위한 베이스캠프
programmers.co.kr
문제 설명
대장균들은 일정 주기로 분화하며,
분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다.
ECOLI_DATA 테이블의 구조는 다음과 같으며,
ID, PARENT_ID, SIZE_OF_COLONY, DIFFERENTIATION_DATE, GENOTYPE 은 각각
대장균 개체의 ID, 부모 개체의 ID, 개체의 크기, 분화되어 나온 날짜, 개체의 형질을 나타냅니다
테이블 구조 - 'FISH_INFO'
| COLUMN NAME | TYPE | NULLABLE |
| ID | INTEGER | FALSE |
| PARENT_ID | INTEGER | TRUE |
| SIZE_OF_COLONY | INTEGER | FALSE |
| DIFFERENTIATION_DATE | DATE | FALSE |
| GENOTYPE | INTEGER | FALSE |
최초의 대장균 개체의 PARENT_ID는 NULL 값이다
[ 문제 ]
2번 형질이 보유하지 않으면서 1번이나 3번 형질을 보유하고 있는 대장균 개체의 수(COUNT)를 출력하는
SQL 문을 작성해 주세요
1번과 3번 형질을 모두 보유하고 있는 경우도
1번이나 3번 형질을 보유하고 있는 경우에 포함합니다.
[ 예시 ]
예를 들어 ECOLI_DATA 테이블이 다음과 같다면
| ID | PARENT_ID | SIZE_OF_COLONY | DIFFERENTIATION_DATE | GENOTYPE |
| 1 | NULL | 10 | 2019/01/01 | 8 |
| 2 | NULL | 2 | 2019/01/01 | 15 |
| 3 | 2 | 100 | 2020/01/01 | 1 |
| 4 | 2 | 16 | 2020/01/01 | 13 |
각 대장균 별 형질을 2진수로 나타내면 다음과 같습니다.
ID 1 : 1000₍₂₎
ID 2 : 1111₍₂₎
ID 3 : 1₍₂₎
ID 4 : 1101₍₂₎
각 대장균 별 보유한 형질을 다음과 같다
ID 1 : 4
ID 2 : 1, 2, 3, 4
ID 3 : 1
ID 4 : 1, 3, 4
따라서 2번 형질이 없는 대장균 개체는 ID 1, ID 3, ID 4 이며
이 중 1번이나 3번 형질을 보유한 대장균 개체는 ID 3, ID 4이다
따라서 결과는 다음과 같아야 한다.
정답 쿼리
SELECT COUNT(*) AS COUNT
FROM ECOLI_DATA
WHERE 1=1
AND (GENOTYPE & 2) != 2
AND ((GENOTYPE & 4) = 4 OR (GENOTYPE & 1) = 1)
풀이 설명
문제 접근 설명
1. ECOLI_DATA 테이블에서 조건에 맞는 데이터 추출하기(WHERE)
2. 추출한 데이터의 개수 세기(COUNT 함수)
1안 쿼리 작성 설명
이진법이 나와서 조금 생소했는데, 문제를 읽어보면 이진법으로 변환한 후에
2번 형질은 보유하지 않아야 한다
또한 1번 혹은 3번의 형질은 보유해야 하기 때문에
이를 비트 연산을 이용해서, 작성하면 아래와 같다.
SELECT *
FROM ECOLI_DATA A
WHERE 1=1
AND (GENOTYPE & 2) != 2
AND ((GENOTYPE & 4) = 4 OR (GENOTYPE & 1) = 1)
비트 연상에 대해서 간단하게 설명하면, 비트연산은 각 비트 단위로 연산을 수행
두 숫자의 각 비트를 비교하여 둘 다 1인 경우에만 1을 반환한다
예를 들어서 보여드리면 GENOTYPE = 5 (2진수로 101)
GENOTYPE & 2
= 101 & 010
= 거짓 거짓 거짓
= 0
따라서, 결과는 000으로 0이 됩니다.
이렇게 비트 연산을 통해 조건문에 넣어서 2번의 형질을 가지는 것은 포함이 되지 않고
1번 혹은 3번의 형질을 가지는 데이터만을 추출하였다
나머지는 COUNT()함수를 이용해서 필터링한 데이터 숫자를 산출하였다.
Programmers - 특정세대의 대장균 찾기
https://school.programmers.co.kr/learn/courses/30/lessons/301650
프로그래머스
SW개발자를 위한 평가, 교육의 Total Solution을 제공하는 개발자 성장을 위한 베이스캠프
programmers.co.kr
문제 설명
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다. 다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다. ECOLI_DATA 테이블의 구조는 다음과 같으며,
ID, PARENT_ID, SIZE_OF_COLONY, DIFFERENTIATION_DATE, GENOTYPE 은 각각 대장균 개체의 ID,
부모 개체의 ID, 개체의 크기, 분화되어 나온 날짜, 개체의 형질을 나타냅니다.

최초의 대장균 개체의 PARENT_ID 는 NULL 값입니다.
[ 문제 ]
3세대의 대장균의 ID(ID) 를 출력하는 SQL 문을 작성해주세요. 이때 결과는 대장균의 ID 에 대해 오름차순 정렬해주세요.
[ 예시 ]

ID 5 가 2 세대입니다. ID 4 에서 분화된 ID 6, ID 3에서 분화된 ID 7 이 3 세대이며 ID 6에서 분화된 ID 8은 4 세대입니다. 따라서 결과를 ID 에 대해 오름차순 정렬하면 다음과 같아야 합니다.

풀이 설명
문제 접근 설명
이쿼리는 부모(PARENT_ID) → 자식(ID) 관계를 타고 내려가면서 "몇 세대인지"를 계산한 다음, 3세대만 뽑는 쿼리다.
1) WITH RECURSIVE gen AS (...)
gen이라는 임시결과를 만들고, 재귀(RECURSIVE)로 계속 아래 세대(자식)들을 붙여 나가겠다는 뜻이다.
트리구조(계층 구조)를 펼처서 ID / PARENT_ID / generation을 만들어 낸다.
2) 재귀의 시작(Anchor) 부분
SELECT
ID,
PARENT_ID,
1 AS generation
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
PARENT_ID IS NULL인 행은 “부모가 없는 개체” → 최상위(1세대) 로 보고 generation을 1로 고정해서 시작한다.
ex:) ID 1, ID 2가 여기에 들어오면 (1, NULL, 1), (2, NULL, 1) 이런 형태의 행이 생긴다.
3) UNION ALL 아래 재귀부분
SELECT
e.ID,
e.PARENT_ID,
g.generation + 1
FROM ECOLI_DATA e
JOIN gen g
ON e.PARENT_ID = g.ID
- gen g : “이미 구해진 세대 정보 - 부모들”
- ECOLI_DATA e : “원본 테이블 - 자식 후보들”
ON e.PARENT_ID = g.ID
어떤 개체 e의 부모가 g의 ID라면,
e는 g의 자식이므로 세대는 부모 세대 + 1.
예를 들어:
- 1세대에 ID 1이 있다면,
- PARENT_ID = 1인 애들(ID 3 등)을 붙이고 generation을 2로 만든다.
이 과정을 더 이상 자식이 없을 때까지 반복하면서 2세대, 3세대, 4세대…가 계속 쌓인다
4) 최종 SELECT
SELECT ID
FROM gen
WHERE generation = 3
ORDER BY ID;
이렇게 만들어진 gen 결과에서 generation = 3인 행만 남기고 ID를 오름차순으로 정렬해서 출력한다.
정답 쿼리
WITH RECURSIVE gen AS (
SELECT
ID,
PARENT_ID,
1 AS generation
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
UNION ALL
SELECT
e.ID,
e.PARENT_ID,
g.generation + 1
FROM ECOLI_DATA e
JOIN gen g
ON e.PARENT_ID = g.ID
)
SELECT ID
FROM gen
WHERE generation = 3
ORDER BY ID;
결과적으로 gen CTE에는 이런 형태의 데이터가 쌓인다.
- 1세대: (1, NULL, 1), (2, NULL, 1)
- 2세대: (3, 1, 2), (4, 2, 2), (5, 2, 2)
- 3세대: (6, 4, 3), (7, 3, 3)
- 4세대: (8, 6, 4)
그리고 마지막에 3세대만 골라서 6, 7 같은 값이 나온다.
Programmers - 멸종위기의 대장균 찾기
https://school.programmers.co.kr/learn/courses/30/lessons/301651
프로그래머스
SW개발자를 위한 평가, 교육의 Total Solution을 제공하는 개발자 성장을 위한 베이스캠프
programmers.co.kr
문제 설명
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다. ECOLI_DATA 테이블의 구조는 다음과 같으며, ID, PARENT_ID, SIZE_OF_COLONY, DIFFERENTIATION_DATE, GENOTYPE 은 각각 대장균 개체의 ID, 부모 개체의 ID, 개체의 크기, 분화되어 나온 날짜, 개체의 형질을 나타냅니다.
[ 문제 ]
각 세대별 자식이 없는 개체의 수(COUNT)와 세대(GENERATION)를 출력하는 SQL문을 작성해주세요.
이때 결과는 세대에 대해 오름차순 정렬해주세요. 단, 모든 세대에는 자식이 없는 개체가 적어도 1개체는 존재합니다.
[ 예시 ]
다음과 같은 데이터가 있을 경우
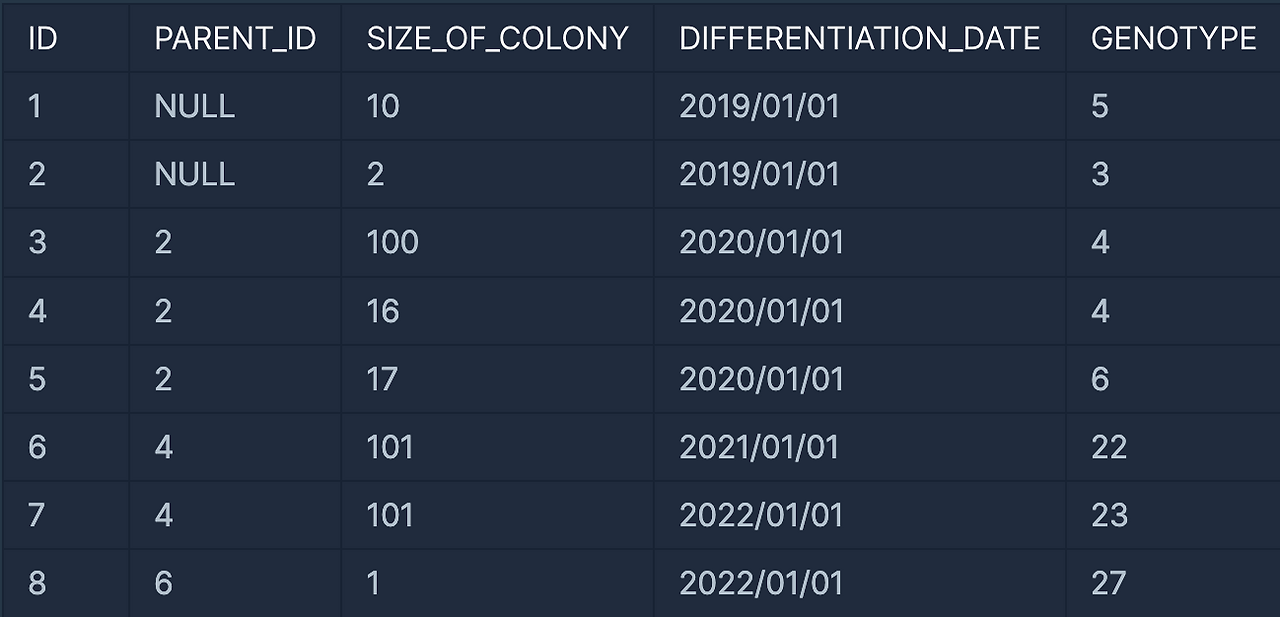
- 1세대는 ID 1, 2
- 2세대는 ID 3, 4, 5
- 3세대는 ID 6, 7
- 4세대는 ID 8이다.
- 이 중 자식이 없는 대장균은 각각 ID 1, (3, 5), 7, 8이다.
따라서, 출력 결과는 다음과 같아야 한다.

풀이 설명
문제 접근 설명
이쿼리는 세대(GENERATION )를 계산한 뒤, 각 세대별로 '자식이 없는 Leaf' 개체 수를 세서 출력하는 쿼리다.
1) WITH RECURSIVE gen AS (...)
GEN 이라는 임시 결과 테이블(CTE)를 만들고, 재귀적으로(계층 구조를 따라) 데이터를 쌓는다
GEN에는 최종적으로 3개의 컬럼이 들어간다
- ID
- PARENT_ID
- GENERATION
2) Anchor 시작점
SELECT
ID,
PARENT_ID,
1 AS GENERATION
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
- PARENT_ID IS NULL → 부모가 없는 개체 = 트리의 루트
- 이들을 1세대(GENERATION = 1) 로 지정해서 시작
3) Recursive : 자식 세대 쌓기
SELECT
E.ID,
E.PARENT_ID,
G.GENERATION + 1
FROM ECOLI_DATA E
JOIN GEN G
ON E.PARENT_ID = G.ID
- GEN G : 이미 세대가 계산된 부모 후보들
- ECOLI_DATA E : 원본 테이블의 자식 후보들
E.PARENT_ID = G.ID
E의 부모가 G라면, E는 G의 자식이니까 E의 세대는 부모 세대 +1이다.
이과정에서 더이상 자식이 없을때까지 반복하면서 2세대, 3세대...가 계속 GEN에 추가된다.
4) Leaf : 자식없는 개체만 필터링
자식이 없는 개체(leaf) 만 골라서 세대별로 카운트하는 단계다.
WHERE NOT EXISTS (
SELECT 1
FROM ECOLI_DATA C
WHERE C.PARENT_ID = G.ID
)
- 어떤 개체 G.ID가 부모로 등록된 적이 있으면
- ECOLI_DATA에 PARENT_ID = G.ID인 행(자식)이 존재하고, leaf가 아님
- 반대로 PARENT_ID = G.ID인 행이 하나도 없으면
- 자식이 없는 개체 = leaf
NOT EXISTS는 “그런 자식 행이 존재하지 않는다”니까 결국 자식 없는 개체만 남긴다는 뜻이다.
5) 세대별로 개수 세기
SELECT
COUNT(*) AS COUNT,
GENERATION
FROM GEN G
...
GROUP BY GENERATION
ORDER BY GENERATION;
- leaf로 남은 것들을 GENERATION별로 묶고(GROUP BY)
- 각 세대에 leaf가 몇 개인지 COUNT(*)로 계산
- 세대 오름차순(ORDER BY GENERATION)으로 출력
정답 쿼리
WITH RECURSIVE GEN AS (
SELECT
ID,
PARENT_ID,
1 AS GENERATION
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
UNION ALL
SELECT
E.ID,
E.PARENT_ID,
G.GENERATION + 1
FROM ECOLI_DATA E
JOIN GEN G
ON E.PARENT_ID = G.ID
)
SELECT
COUNT(*) AS COUNT,
GENERATION
FROM GEN G
WHERE NOT EXISTS (
SELECT 1
FROM ECOLI_DATA C
WHERE C.PARENT_ID = G.ID
)
GROUP BY GENERATION
ORDER BY GENERATION;
결과적으로 출력되는건
- 1세대: 1개
- 2세대: 2개
- 3세대: 1개
- 4세대: 1개
이런 식으로 세대별 leaf 개수가 출력된다.
'SQL' 카테고리의 다른 글
| [SQL] - 프로그래머스 프로그래머스 SQL 고득점 KIT GROUP BY (1) | 2026.01.10 |
|---|---|
| [SQL] - 프로그래머스 SQL 고득점 KIT SUM, MAX, MIN 오답노트 (0) | 2026.01.05 |
| [SQL] - MySQL CTE란? (0) | 2026.01.04 |
| [SQL] - 프로그래머스 - 평균 일일 대여 요금 구하기 (0) | 2025.12.30 |
| [SQL] - LEETCODE SQL 50 (0) | 2025.12.30 |