정렬이란 데이터를 순서대로 나열하는 방법을 의미합니다.
정렬은 알고리즘의 굉장히 중요한 주제입니다.
이진 탐색을 가능하게도 하고, 데이터를 조금 더 효율적으로 탐색할 수 있게 만들기 때문입니다.
[4, 6, 2, 9, 1] # 정렬되지 않은 배열
[1, 2, 4, 6, 9] # 오름차순으로 정렬된 배열
[9, 6, 4, 2, 1] # 내림차순으로 정렬된 배열
정렬에대해서 혹시 말로설명해 보신적이 있나요?
어떤 순서로 정렬하셨나요?
이를 한 번 말로 설명해보실 수 있으신가요?
생각보다 설명하기 힘드시다는 걸 느낄겁니다.
이를 위해 컴퓨터에게 정렬을 시키기 위해서는 명확한 과정을 설명해줘야 합니다
버블 정렬 - (bubble sort)
- 서로 인접한 두 원소를 검사하여 정렬하는 알고리즘
- 인접한 2개의 레코드를 비교하여 크기가 순서대로 되어 있지 않으면 서로 교환한다.
- 선택 정렬과 기본 개념이 유사하다.
버블 정렬은 첫 번째 자료와 두 번째 자료를, 두 번째 자료와 세 번째 자료를, 세 번째와 네 번째를, …
이런 식으로 (마지막-1)번째 자료와 마지막 자료를 비교하여 교환하면서 자료를 정렬한다.
1회전을 수행하고 나면 가장 큰 자료가 맨 뒤로 이동하므로
2회전에서는 맨 끝에 있는 자료는 정렬에서 제외되고,
2회전을 수행하고 나면 끝에서 두 번째 자료까지는 정렬에서 제외된다.
이렇게 정렬을 1회전 수행할 때마다 정렬에서 제외되는 데이터가 하나씩 늘어난다.

1회전
첫 번째 자료 7을 두 번째 자료 4와 비교하여 교환하고, 두 번째의 7과 세 번째의 5를 비교하여 교환하고, 세 번째의 7과 네 번째의 1을 비교하여 교환하고, 네 번째의 7과 다섯 번째의 3을 비교하여 교환한다. 이 과정에서 자료를 네 번 비교한다. 그리고 가장 큰 자료가 맨 끝으로 이동하므로 다음 회전에서는 맨 끝에 있는 자료는 비교할 필요가 없다.
2회전
첫 번째의 4을 두 번째 5와 비교하여 교환하지 않고, 두 번째의 5와 세 번째의 1을 비교하여 교환하고, 세 번째의 5와 네 번째의 3을 비교하여 교환한다. 이 과정에서 자료를 세 번 비교한다. 비교한 자료 중 가장 큰 자료가 끝에서 두 번째에 놓인다.
3회전
첫 번째의 4를 두 번째 1과 비교하여 교환하고, 두 번째의 4와 세 번째의 3을 비교하여 교환한다. 이 과정에서 자료를 두 번 비교한다. 비교한 자료 중 가장 큰 자료가 끝에서 세 번째에 놓인다.
4회전
첫 번째의 1과 두 번째의 3을 비교하여 교환하지 않는다.
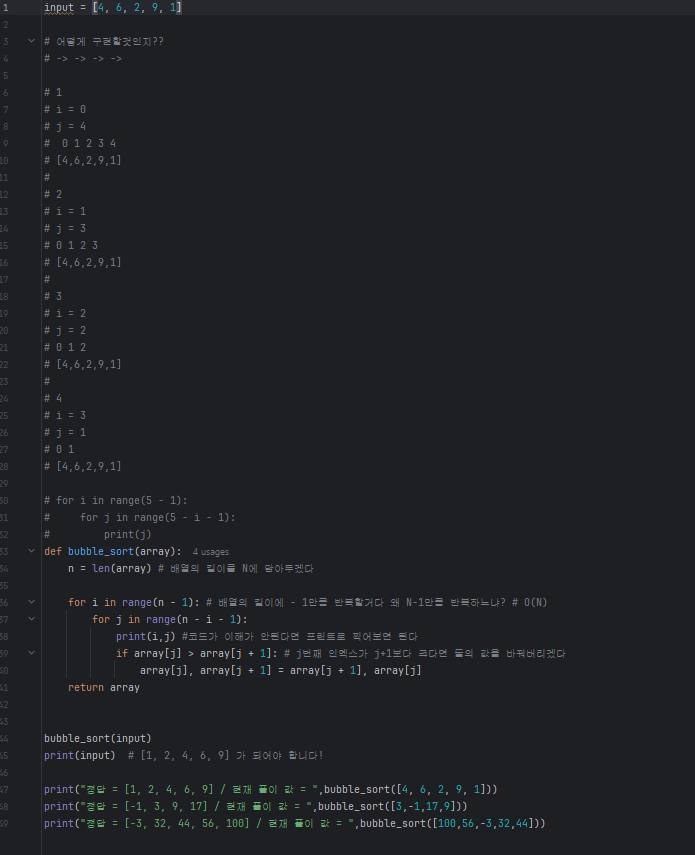
선택 정렬 - (selection_sort)
제자리 정렬(in-place sorting) 알고리즘의 하나
입력 배열(정렬되지 않은 값들) 이외에 다른 추가 메모리를 요구하지 않는 정렬 방법
해당 순서에 원소를 넣을 위치는 이미 정해져 있고, 어떤 원소를 넣을지 선택하는 알고리즘
첫 번째 순서에는 첫 번째 위치에 가장 최솟값을 넣는다.
두 번째 순서에는 두 번째 위치에 남은 값 중에서의 최솟값을 넣는다.
...
이렇게 얘기하니까 조금 어려운거같아서 쉽게 얘기하자면
다음과 같이 군인들이 일렬로 쭉~ 서 있는데,
한번 둘러보면서 가장 키 작은 사람을 찾는겁니다.
그리고 전부 다 봤다면, 그 중 가장 키 작은 사람 맨 앞으로 와
한 다음에 또 둘러보면서 두 번째로 키 작은 사람을 두 번째에 배치 시킵니다.
예시를 들어보자
배열에 9, 6, 7, 3, 5가 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해 보자.

1회전:
첫 번째 자료 9를 두 번째 자료부터 마지막 자료까지와 비교하여 가장 작은 값을 첫 번째 위치에 옮겨 놓는다. 이 과정에서 자료를 4번 비교한다.
2회전:
두 번째 자료 6을 세 번째 자료부터 마지막 자료까지와 비교하여 가장 작은 값을 두 번째 위치에 옮겨 놓는다. 이 과정에서 자료를 3번 비교한다.
3회전:
세 번째 자료 7을 네 번째 자료부터 마지막 자료까지와 비교하여 가장 작은 값을 세 번째 위치에 옮겨 놓는다. 이 과정에서 자료를 2번 비교한다.
4회전:
네 번째 자료 9와 마지막에 있는 7을 비교하여 서로 교환한다.
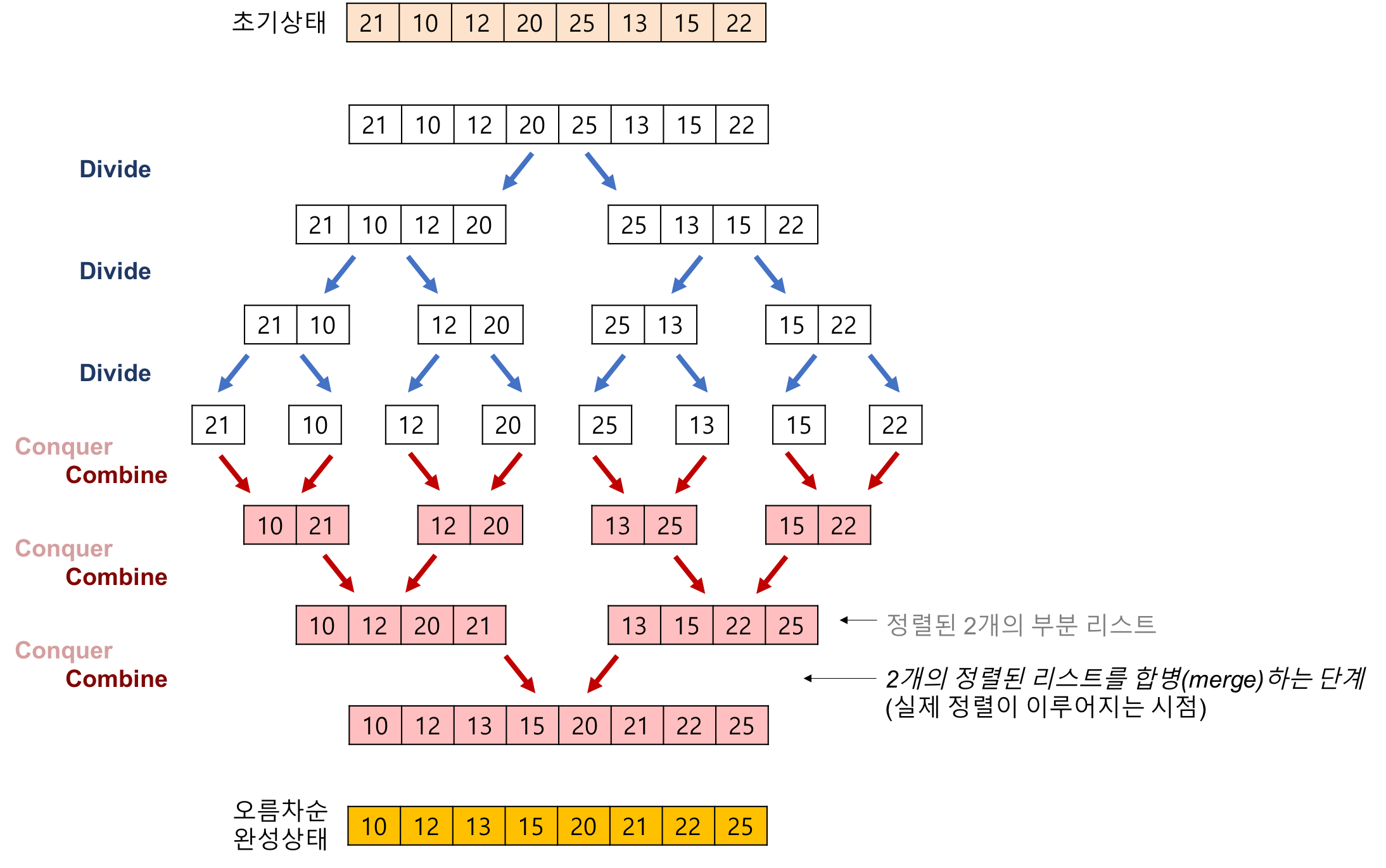
병합 정렬 - (merge Sort)
병합 정렬은 배열의 앞부분과 뒷부분의 두 그룹으로 나누어 각각 정렬한 후 병합하는 작업을 반복하는 알고리즘입니다.
일반적인 방법으로 구현했을 때 이 정렬은 안정 정렬 에 속하며, 분할 정복 알고리즘의 하나 중
분할 정복(divide and conquer) 방법
문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략입니다
분할 정복 방법은 대개 순환 호출을 이용하여 구현합니다.
합병 정렬(merge sort) 알고리즘의 구체적인 개념
하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음,
두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법입니다
합병 정렬은 다음의 단계들로 이루어 집니다.
분할(Divide): 입력 배열을 같은 크기의 2개의 부분 배열로 분할합니다.
정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출 을 이용하여
다시 분할 정복 방법을 적용합니다
결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.
합병 정렬의 과정
추가적인 리스트가 필요하다.
각 부분 배열을 정렬할 때도 합병 정렬을 순환적으로 호출하여 적용한다.
합병 정렬에서 실제로 정렬이 이루어지는 시점은 2개의 리스트를 합병(merge)하는 단계 이다.


'알고리즘' 카테고리의 다른 글
| 07 - 버블 정렬,선택정렬,삽입정렬 (0) | 2026.01.01 |
|---|---|
| 06 - Stack & Queue (1) | 2025.12.26 |
| 04 - 재귀함수 (0) | 2025.12.25 |
| 03 - 이진탐색 (0) | 2025.12.16 |
| 02 - Array & Linked List (0) | 2025.12.16 |