데이터 레이크하우스
데이터레이크하우스는 데이터레이크의 유연한 데이터 스토리지와 데이터웨어하우스의 고성능 분석기능을 결합한 데이터 플랫폼 입니다. 데이터 레이크와 데이터 웨어하우스는 일반적으로 함께 사용됩니다. 데이터레이크는 새로운 데이터를 포괄하는 시스템의 역할을 하며, 데이터웨어하우스는 데이터에 다운스트림 구조를 적용합니다.데이터 레이크 계층 위에 데이터 웨어하우스 역할을 하는 계층을 통합하는 것입니다. 데이터 웨어하우스가 가진 고품질의 데이터 관리와 구조화 기능을 구현하지만,이를 별도의 바로 값비싼 데이터 웨어하우스 스토리지에서가 아닌 데이터레이크의 유연하고 저렴한 스토리지 위에서 데이터 웨어하우스를 실현한다는 점이 특징입니다.
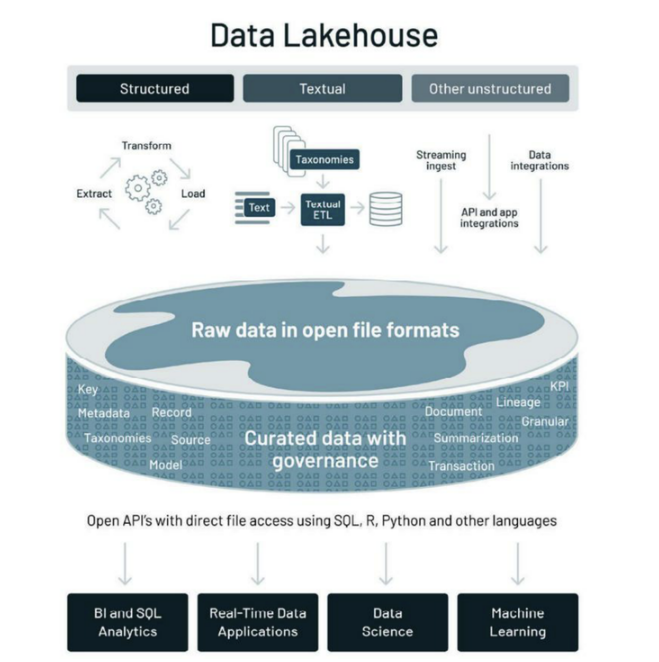
보통 AWS,AZURE,GCP와 같은 클라우드의 데이터 레이크 계층에서 새로운 데이터 레이크 계층으로 데이터를 가져옵니다.
그대로 데이터 레이크에 저장되기 때문에 저장과정에서 용이함이나 저렴한 비용의 장점은 그대로 가져올수 있습니다.
또 다른곳에 데이터를 복제하지 않고도 원천 데이터를 BI 도구와 연결하거나 활용할 수 있기에, 데이터 웨어하우스의 단점이었던 데이터 중복 저장이나 최신화가 어렵다는 문제를 해결할 수 있습니다. 데이터의 정합성과 일관성이 유지되는 데이터 웨어하우스의 장점과 관련된 ACID트랜잭션 지원 및 주요 스키마의 지원도 가능하게 됩니다.
심지어 정형 데이터에만 적용되던 ACID 트랜잭션이나 별도의 제품으로 구현되던 데이터 계보관리 기능을 비정형 데이터에도 모두 적용할 수 있게 됩니다. 데이터 레이크에 파일 수준으로 저장되던 비정형 데이터들을 아파치 아이스버그(Apache Iceberg)나 델타레이크(Delta lake)등을 이용해 논리적 테이블 수준으로 변환해 관리할 수 있으므로, 비정형 데이터를 활용하는 머신러닝 프로젝트도 손쉽게 진행할수 있습니다.
오늘날 많은 빅데이터 프로젝트에서는 컬럼 기반 개방형 데이터 포맷인 아파치파케이(Apache Parquet)를 사용하고 있는데,
특정 언어에 종속되지 않고 대부분의 분산형 쿼리 엔진이나 ETL 도구들이 파케이 포맷을 지원하기 때문에 손쉽게 데이터를 내보내고 공유할 수 있다.데이터 레이크하우스는 데이터 포맷이나 API 등에서 오픈소스 기반의 개방형 아키텍처로 구축됩니다. 따라서 상대적으로 단일 기업에 친화적이고 일견 폐쇄적으로 구성되는 데이터 웨어하우스에 비해 보다 다양한 기능들을 효과적으로 사용하고 있습니다.
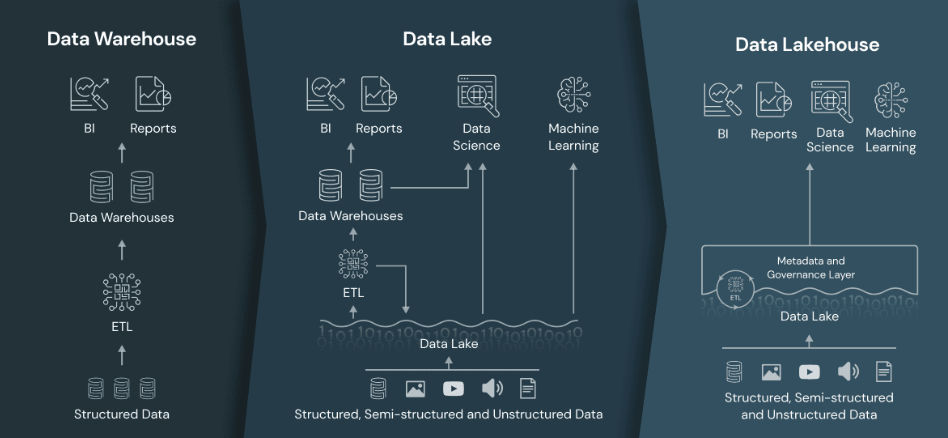
데이터 레이크하우스의 이점
데이터하우스는 사용자에게 다음과 같은 몇가지 주요 이점을 제공합니다.
- 데이터 중복성 감소
- 비용 절감
- 다양한 워크로드 지원
- 데이터 거버넌스 개선
- 확장성 향상
- 실시간 스트리밍 지원
데이터 레이크하우스 아키텍처의 계층
데이터 레이크하우스의 아키텍처는 일반적으로 다음과 같은 다섯 계층으로 구성됩니다.
- 수집 계층
- 스토리지 계층
- 메타데이터 계층
- API 계층
- 소비 계층
'데이터 엔지니어링' 카테고리의 다른 글
| [데이터 엔지니어링] - 이커머스 주문 데이터 파이프라인 구축(Snowflake + dbt) (0) | 2026.03.09 |
|---|---|
| [데이터 엔지니어링] - Data Lineage (0) | 2026.03.09 |
| [데이터 엔지니어링] - BigQuery 해부하기 (0) | 2026.03.08 |
| [데이터 엔지니어링] - Cloud Data Warehouse(BigQuery&Snowflake) (1) | 2026.03.04 |
| [데이터 엔지니어링] - Cloudera (1) | 2026.03.01 |