프로젝트는 snowflake + dbt 실제 실습 프로젝트를 데이터엔지니어 관점에서 처음부터 끝까지 따라할수 있게 연습해보려고 합니다. snowflake와 dbt에 대한 자료가 그렇게 많지 않기때문에 직접해보고 연습해보는 과정을 해보기로 했습니다.
프로젝트 주제
이커머스 주문 데이터 파이프 라인 구축
Snowflake에 원천 데이터를 적재하고, dbt로 Staging -> marts 구조의 분석용 모델을 만드는 프로젝트입니다.
프로젝트로 인해 배우는것들
- Snowflake 기본 테이블 생성
- Raw / Staging / Mart 계층 분리
- dbt source() / ref() 사용
- dbt 모델 실행
- dbt test 적용
- incremental 모델 기초
- 스타 스키마 느낌의 분석 모델 설계
전체 아키텍처
raw schema
└ raw_orders
└ raw_customers
└ raw_products
dbt staging
└ stg_orders
└ stg_customers
└ stg_products
dbt marts
└ dim_customers
└ dim_products
└ fct_orders
원본적재 -> 정재 -> 분석용 팩트/차원테이블 흐름입니다.
Snowflake 사전준비
1. Warehouse 만들기
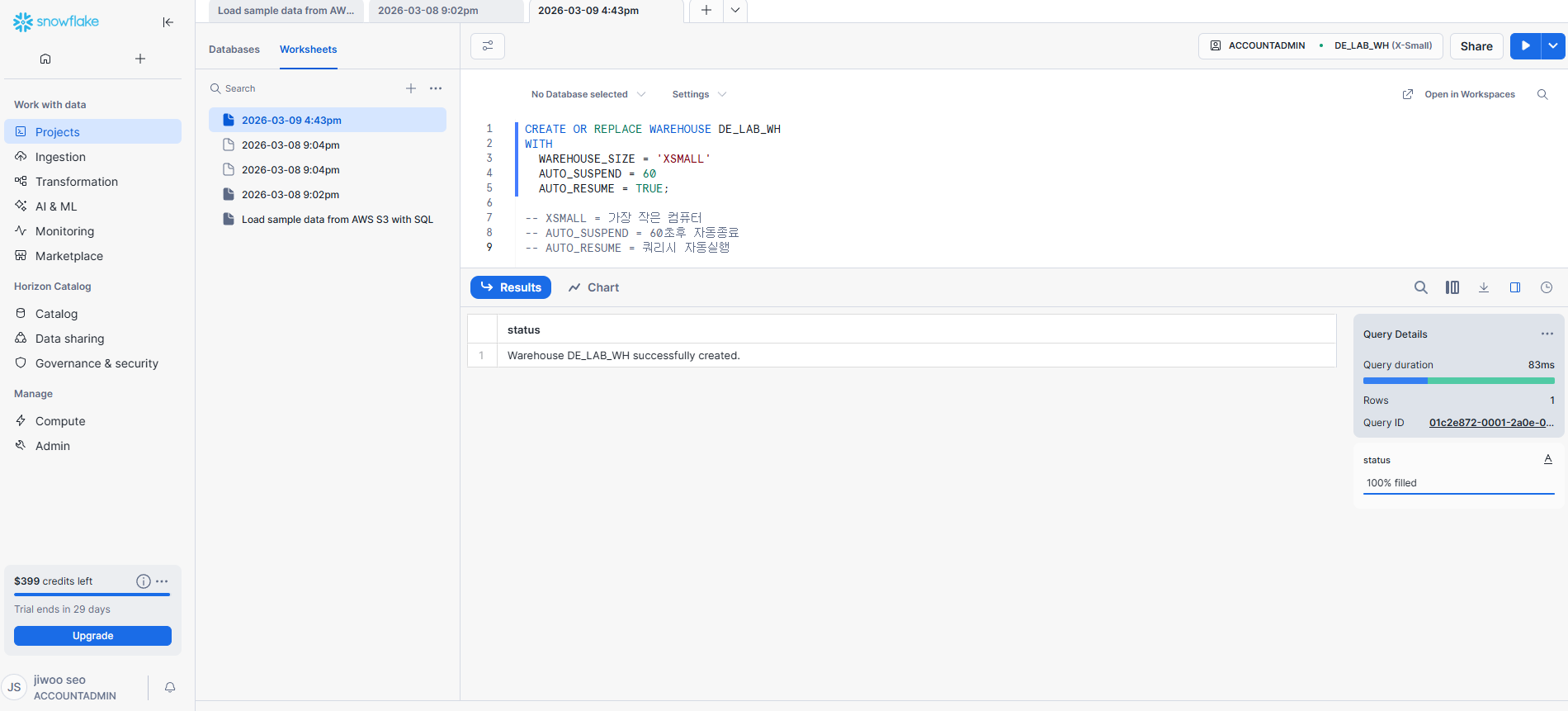
2. Database + Schema 생성

하나의 꿀팁을 주자면 드래그 이후 ctrl + enter 를 하면 해당 쿼리가 실행된다.
3. Raw Table
Raw layer의 목적은 원본데이터 보존을 위해 만들었습니다.
소스데이터를 가공없이 그대로 저장하고, 데이터 문제 발생시 원본 추적이 가능합니다.
그리고 schema 변경에 대응할수 있습니다.
예를들면 RAW_ORDERS
| order_id | customer_id | product_id | qty | price | created_at |
ETL 과정에서 Kafka 같은 ingestion 도구가 데이터를 그대로 넣습니다.
RAW = source of truth


Raw테이블을 만들고 Database에서 생성되었는지까지 확인!!
4. Sample Date 적재
RAW_ORDERS

RAW_CUSTOMERS

RAW_PRODUCTS

5. STAGING
스테이징의 목적은 분석을 위한 데이터 정리입니다.
여기서 하는것은 컬럼 이름 정리,데이터타입 변환,null처리,중복제거,정규화 작업입니다.
stg_orders
order_id : 주문 고유 식별자 (Primary Key) , 주문이벤트 식별 Fact 테이블 Join 기준
order_date : 주문발생 시간 : 분석에서 많이 쓰는 기준으로(일별 매출,월별 매출, 분기 매출)
customer_id : 고객 식별자 : DIM_customers와 Join이 가능합니다. ex:) 고객별 매출 분석, 고객 세그먼트 분석
product_id : 상품 식별자 : DIM_PRODUCTS와 Join이 가능합니다. ex:) 상품별 매출, 카테고리 매출
quantity : 구매 수량 대표적인 fact metric 입니다. (판매량 분석을 위한 컬럼입니다.)
unit_price : 상품 단가입니다 매출계산할때 사용할수 있습니다 매출 = quantity x price
order_amount : 주문 총 금액 : BI 분석에서 바로 사용할수 있습니다. ex:) 총매출, 평균 주문 금액
payment_method : 결제 수단 : 카드 vs 계좌이체나 간편결제 비율을 분석할수 있습니다.
region : 지역 정보 입니다. 지역별 매출을 분석할수 있습니다.
updated_at : 데이터 업데이트 시간입니다.
stg_Products
product_id : 상품 식별자입니다.
product_name : 상품 이름입니다.
category : 상품 카테고리입니다.
RAW
| order_id | cust_id | prod | qty | price |
STAGING
| order_id | customer_id | product_id | quantity | price |
또는
RAW=price"1000"
STAGING=price1000
RAW → STAGING = 데이터 정리 단계


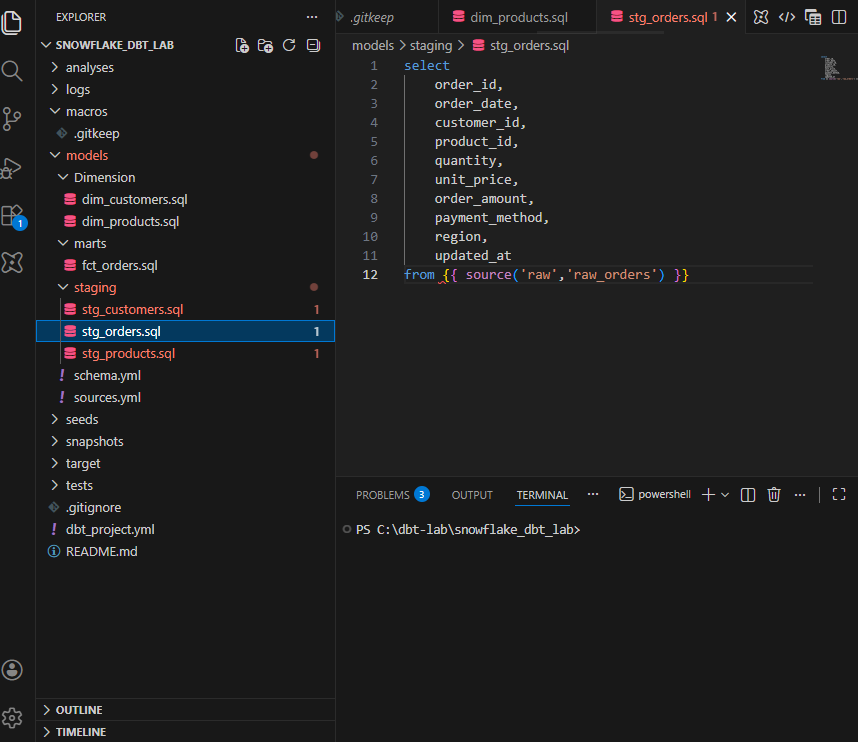
6. Mart table
Mart table은 분석용 데이터 모델입니다 여기서 디멘션과 fact 테이블 두개를 사용했습니다
fact 테이블
Fact Table = 비즈니스 이벤트 데이터를 저장하는 테이블입니다.
쉽게 설명하면 기업에서 실제로 발생하는 행동 / 사건 / 거래를 기록합니다.
예시가 있다면 주문,결제,클릭등등 fact 테이블을 중심으로 dimension 테이블을 join하여 매출 분석이나 고객 분석을 수행합니다.
| order_id : 주문 이벤트
| customer_id : 고객 dimension 연결
| product_id : 상품 dimension 연결
| quantity : 판매량 metric
| order_amount : 매출 metric
총 5개로 나누었습니다.
- 수치 데이터 포함
- 분석 중심 테이블
매출과 주문 클릭 로그데이터를 확인할수 있습니다.
7.Dimension
디멘션 테이블은 분석할 대상을 설명하는 정보 테이블입니다.
예를 들어 주문 데이터 분석을 한다고 생각해보면 101 고객이 누군지 P01상품이 무엇인지를 알수가 없습니다.
그래서 설명 정보 테이블을 따로두기 위해서 만들었습니다.
| customer_id | customer_name | region |
| 101 | Kim | Seoul |
| 102 | Lee | Busan |
디멘션은 설명정보 입니다.
| customer_id | name | city |
| product_id | product_name |
현재 파이프라인 구조
Snowflake RAW.RAW_ORDERS
↓
dbt staging model
↓
ANALYTICS.STG_ORDERS
↓
dbt mart model
↓
ANALYTICS.FCT_ORDERSRAW 레이어는 원본 데이터를 보존하는 역할을 하고, STAGING 레이어에서는 컬럼 정리나 데이터 타입 변환 같은 기본적인 정제를 수행합니다. 그 다음 MART 레이어에서는 분석을 위한 데이터 모델을 만들며, 여기서 fact와 dimension 테이블을 구성합니다. 이런 구조를 사용하는 이유는 데이터 추적, 재사용성, 데이터 품질 관리 측면에서 유리하기 때문입니다.
SNOWFLAKE에서 DATA 확인하기

지금까지 만든 데이터웨어하우스 구조
RAW
├ RAW_ORDERS
├ RAW_CUSTOMERS
└ RAW_PRODUCTS
STAGING
├ STG_ORDERS
├ STG_CUSTOMERS
└ STG_PRODUCTS
MART
├ DIM_CUSTOMERS
├ DIM_PRODUCTS
└ FCT_ORDERS지금까지 배운 핵심 개념
1. source() : 외부테이블 연결
{{ source('raw','raw_orders') }}
2. ref() : dbt 모델 연결
{{ ref('stg_orders') }}
3.Layered Modeling
STAGING = 데이터 정리
MART = 분석용 모델
DBT Lineage (데이터 흐름)
dbt docs generate
dbt docs serve
http://localhost:8080
'데이터 엔지니어링' 카테고리의 다른 글
| [데이터 엔지니어링] - Data Lineage (0) | 2026.03.09 |
|---|---|
| [데이터 엔지니어링] - Data Lake House (0) | 2026.03.09 |
| [데이터 엔지니어링] - BigQuery 해부하기 (0) | 2026.03.08 |
| [데이터 엔지니어링] - Cloud Data Warehouse(BigQuery&Snowflake) (1) | 2026.03.04 |
| [데이터 엔지니어링] - Cloudera (1) | 2026.03.01 |