Null
Null값을 다루는 방법론에 대해서 여러가지 준비를 해봤습니다. 실제로 데이터를 불러오다 보면 데이터를 불러오는 과정에서 특정값에 어떤 오류가 있어서 Null값으로 처리되는 경우가 있거나 원래부터 데이터 값이 존재하지 않을 경우가 있습니다.
이 Null값을 어떻게 처리하냐에 따라서 특정 쿼리를 날릴때 어떤 Null값이 존재하는것을 지울것인지 채워 넣을것인지 아니면 그대로 둘것인지 의사결정을 할 필요가 있다.
Null로 다루는 주제입니다.
- window를 사용하여 데이터의 일정부분 null 생성
- null 값을 가진 row 단순 제거
- null 값을 가진 row 제거의 다양한 방법론
- null 값 단순 채우기
- fill forward 방식으로 null 값 채우기
- fill backward 방식으로 null 값 채우기

window를 사용하여 데이터의 일정부분 null 생성
spark session을 만들어주고 rand를 사용해서 난수 0과 1사이에 다양한 난수를 발생하는 rand를 명령어로 작성해서 추가 행 컬럼을 만들어 주었습니다.
rand를 준이유는 윈도우를 줘서 행번호를 입력해서 특정한 비율만큼 Null값을 줄것이기 때문에 만들었습니다.
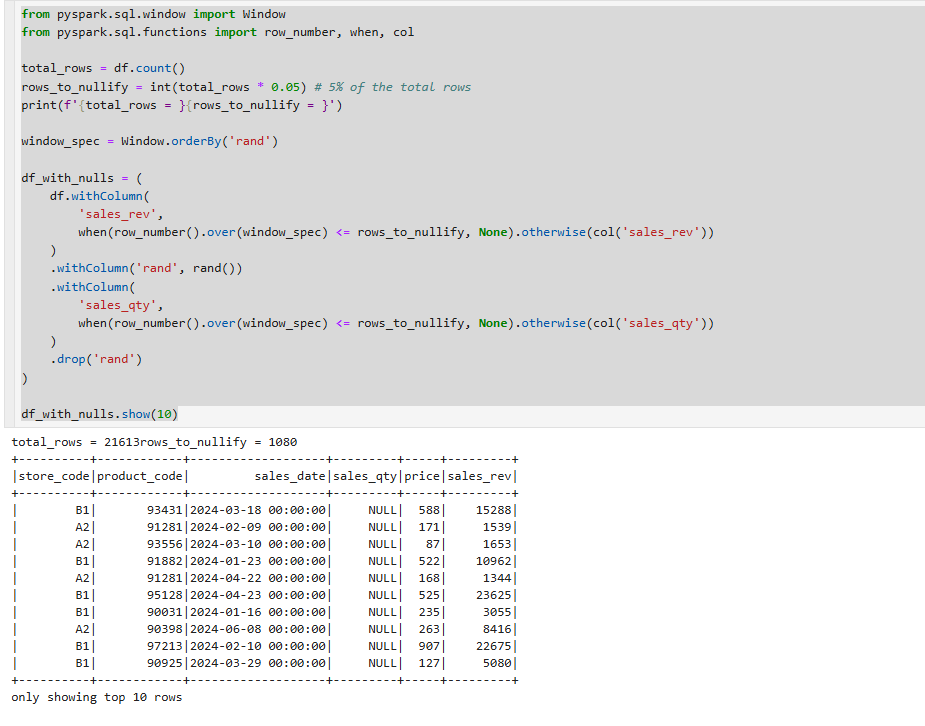
window방식을 통해서 균등하게 Null값이 존재할수 있도록 만들어봤습니다.
데이터에 5%만 주입을 하고, sales_rev 에서 rows_to_nullify, 1080보다 작은 숫자는 null값을 주겠다라는 명령입니다.
.otherwise를 사용해서 1080보다 크면 원래 매출 데이터를 그대로 쓴다는 뜻입니다.
새롭게 난수를 주기위해서 withColumn('rand',rand())를 주고
sales_qty에 같은 명령을 주었습니다. 그리고 마지막에 rand를 버려줍니다.

sales_rev와 sales_qty의 null값을 filter를 통해서 확인해볼수 있습니다.
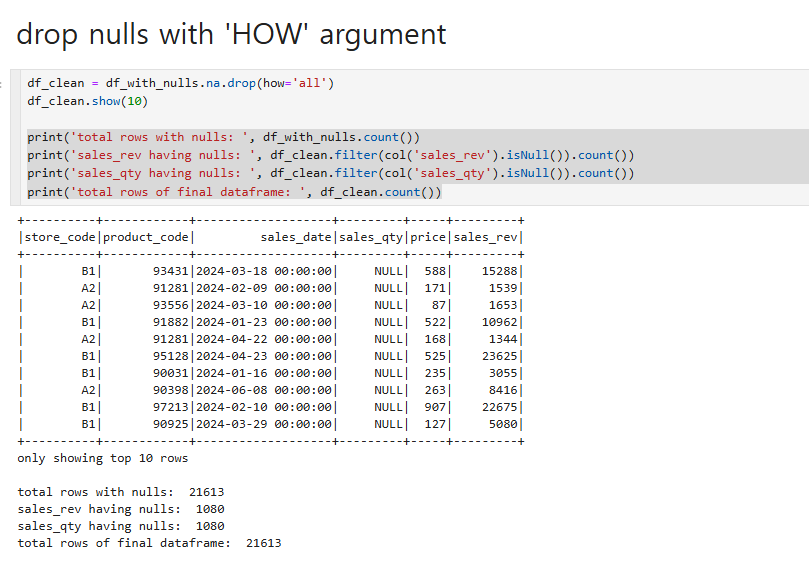
null 값을 가진 row 단순 제거

단순 제거는 간단합니다. Null값을 가진 데이터프레임에 대하여 Null값을 찾아서 na drop을
na = null 을 찾아서 제거시킵니다.
위에있는 값을가지고 df_clean에 대해서 null값이 지워졌는지 확인해봤습니다.
확인 결과 21613개의 total data가 19500개로 null값이 지워진걸 확인이 됩니다.
How argument
이번에는 how방식을 사용해봤는데 how방식에는 any와 all방식이 있습니다.
any는 어느하나라도 행기준으로 봤을때 null이 존재하게되면 탈락시키는 구조입니다.
all은 데이터가 모두 다 null값으로 존재하는 경우 탈락시키는 구조입니다.
all이라는 명령어를 사용하게되면 너무 과한 방식이기때문에 그렇다면 어떤 방식이 또 있을까?
drop nulls on the basis of column

특정 컬럼에 조건에 걸어두는 방식입니다 subset을 이용해서 특정 컬럼을 지정해서 탈락시켜주는 과정입니다
결과를 확인해보면 sales_rev와 sales_qty가 null이 0이 되어있는걸 확인해볼수 있습니다.
그렇다면 null값을 어떻게 채우냐?
fill nulls
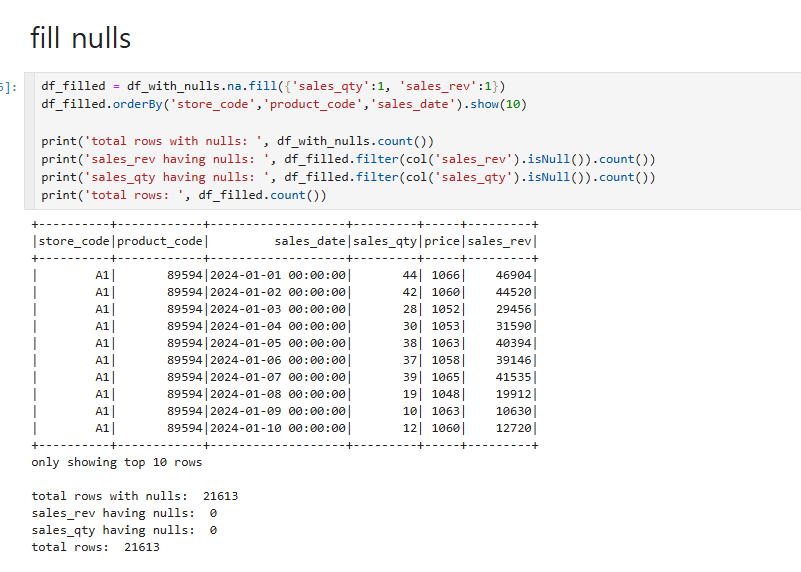
이번에는 drop이 아니라 fill을 사용해서 sales_qty 와 sales_rev에 1씩 추가해주었다.
그렇게 되면 null값에 가진 컬럼에 대해서 1씩 변경되었습니다.
그렇다면 이렇게 null값을 채우는게 맞나?라는 생각이 들것입니다.
이번에는 fill forward와 fill backward에 대해서 알아보겠습니다.
- fill forward : 이전 행의 데이터로 다음 행을 값을 채우는 방법
- fill backward : 다음 행의 데이터로 이전 행을 값을 채우는 방법
fill forward
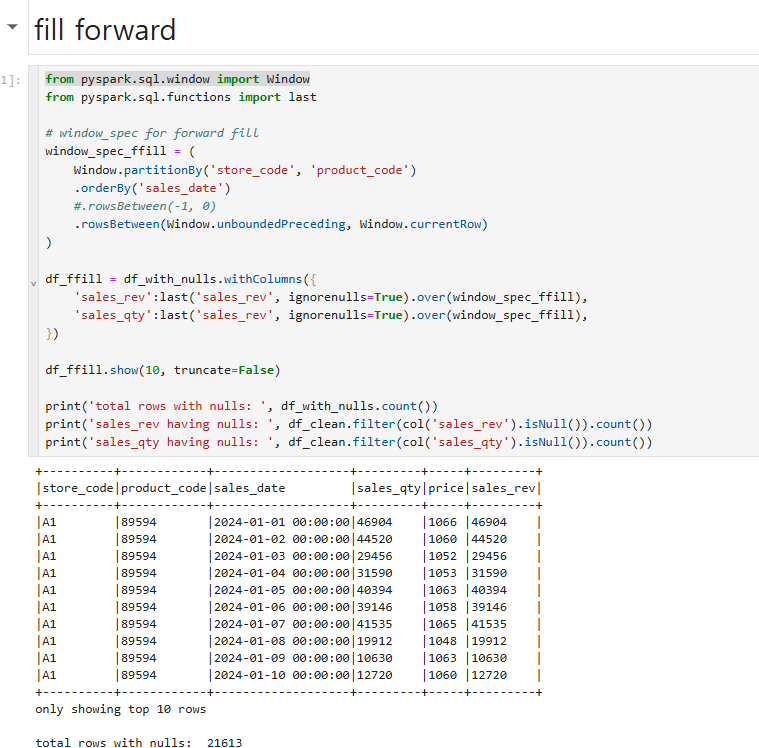
pandas에서도 forward fill하고 backward fill의 방식이 제공됩니다
같은 방식으로 spark에서도 어떤방식으로 존재하는지 작성해봤습니다.
window와 last(마지막 값)을 불러와서 rowsBetween으로 unboundedpreceding, currentRow를 사용해서
이전 행의 데이터로 다음 행을 값을 채우는 방법을 사용했습니다.
'즉,윈도우 스팩을 통해서 스토어코드,프로덕트 코드에 따라서 시간 순서대로 시계율로 데이터가 정리된것을 가지고서 이와같이
직전의 값을 가지고 현재행을 바라보는 이와같은 rowsbetween 값을 한다음 마지막값에 ignore nulls로 해서 true값을 집어넣고 그다음에 직전의 값으로 채워넣는 형식입니다.'
backward fill
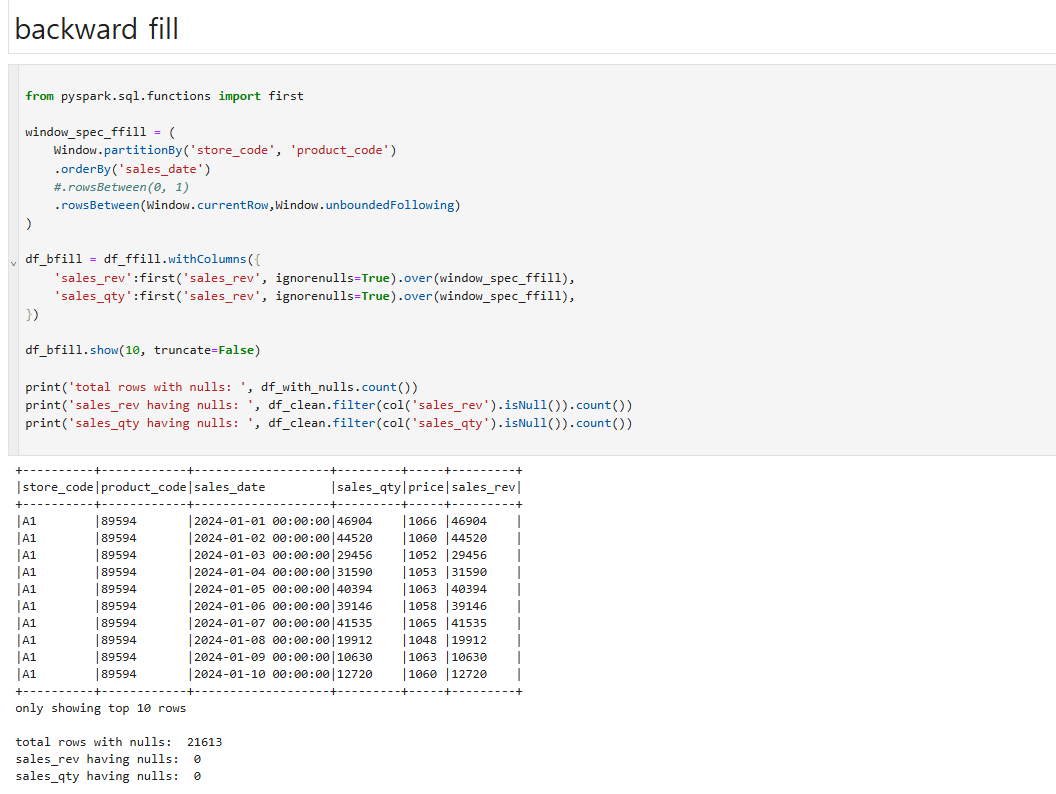
backward fill은 rowsBetween은 위와 반대로 작성해서 코드작성 방식은 같습니다.
imputation by mean
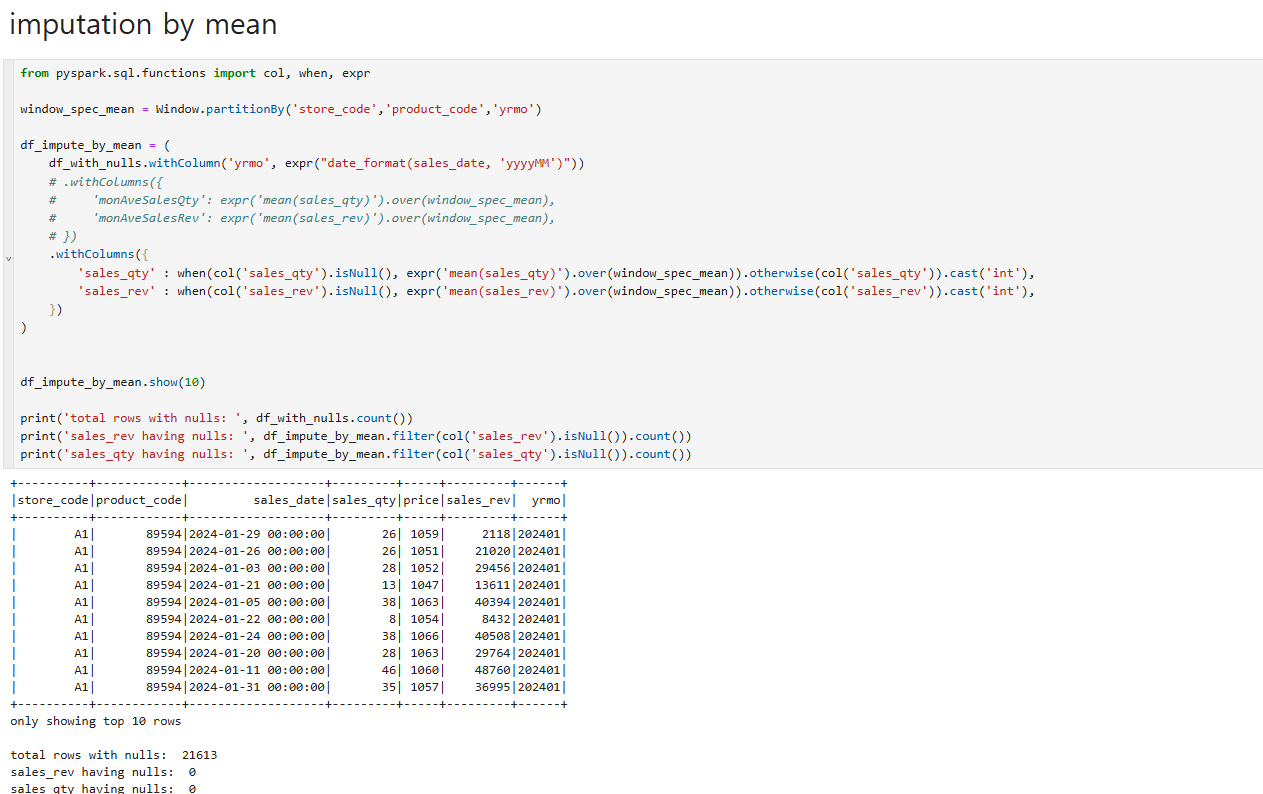
null값을 채워넣는 과정중에서 평균값으로 null값을 채워넣는 방법중 하나인 imputation by mean입니다.
null값을 채워넣는 것을 전문용어로 imputation 이라고 한다.
'Spark' 카테고리의 다른 글
| [Spark] - 파티션 최적화 (0) | 2026.03.25 |
|---|---|
| [Spark] - Json 데이터 다루기(with_Explode) (0) | 2026.03.24 |
| [Spark] - 정규식을 통한 문자열 처리 (0) | 2026.03.23 |
| [Spark] - Spark 기본 동작 (0) | 2026.03.23 |
| [Spark] - Catalyst & Tungsten (0) | 2026.03.23 |