이번 블로그에서는 파티셔닝을 최적화 하는 방법에 대해서 작성해보려 합니다.
파티셔닝을 최적화 한다는게 어떤 뜻이냐면, Spark에서 데이터를 분산해서 파티션 단위로 저장하고 그것을 메모리 상이든 파일 단위에서 쓰고 있기를 할때 파티션 단위로 모든것을 처리합니다.
하지만 파티션을 어떻게 만드냐에 따라서 Spark는 파티션된 모든 파일을 읽어오거나 처리할 필요없이 특정 파티션만 다루면서 빠르게 효율적으로 Spark 연산을 극대화 시킬수있습니다.

실습을 위해서 단일 파티션말고 다중파티션을 만들기위해 여러개의 csv를 만들고, withColumn으로 각각의 어떤 행이 파티션 파일에 존재했는지 추적해나가는 과정입니다. 이걸 추적해나가는 과정을 사용하기위해 input_file_name을 import 하고,
split을 통해서 정리해나가는과정입니다. python이랑 동일하고 part 뒤에 인식해야될 것들만 정리하였습니다.

df.group을 불러오고 partition단위로 보고싶어서 part와 store_code를 가져오고, orderBy를 통해서 정렬해주는 모습입니다.

databricks를 사용하지 않기 때문에 지금 로컬환경에서 시각화 하기위해서 pandas 라이브러리를 불러오고,
pivot_table을 통해서 차트를 만들고 index 단위로 partition을 했습니다. columns는 store_code 기준으로 하고 value 값은 count를 설정해주었습니다 groupby를 해가지고 나온 값이니까 aggregate function 같은경우는 sum을 해주었습니다.
plot을 사용해서 가로형 막대차트를 만들어 주었습니다. stacked로 위치를 확인해본 결과입니다.
확인해본 결과 partition에 점포의 데이터가 전체 데이터가 골고루 잘 섞여있는 모습을 확인할 수 있습니다.
그리고나서 이제 저장을 할건데요 file_path에 이름을 줘서 저장해보도록 하겠습니다.

df_sorted.write모드로 해주고 overwite로 해서 혹시나 있으면 무시하고 덮어쓰는거고,format.csv로 파일을 저장하고 옵션을 통해서 header값을 명시하는것으로 저장하였습니다.
이번에는 dataframe view를 불러오는걸로해서 방금전에 저장했던 파일을 불러보도록 하겠습니다.

위에 보면 new_file_path로 데이터를 불러왔습니다. 이번에는 분포도를 한번 살펴보도록 하겠습니다.
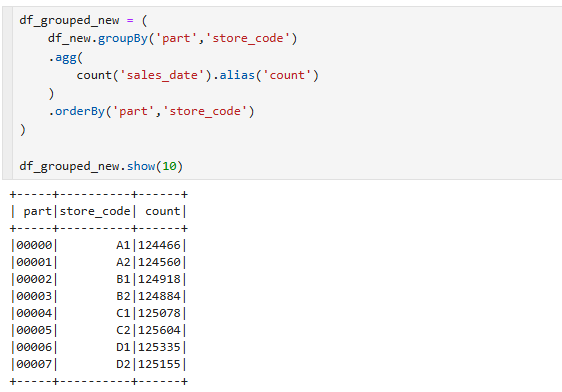
새로 가져온거기때문에 위에 코드를 그대로 가져와서 df_new_ group으로 확인해본 결과입니다.

만약에 store_code에 A1 점포에 대한 데이터만 가져오고싶다 라고하면 어떻게 해볼수 있을까요?
그럴때 파티션화 되어있는 데이터에서 A1 특정 점포에 대하여 불러오는 경우와 골고루 섞여있는 파티션 데이터 안에 A1~D2까지 점포들이 골고루 섞여있는경우에 데이터를 불러오는 경우 Spark내부에서 어떻게 동작하는지 고민할 필요가 있습니다.
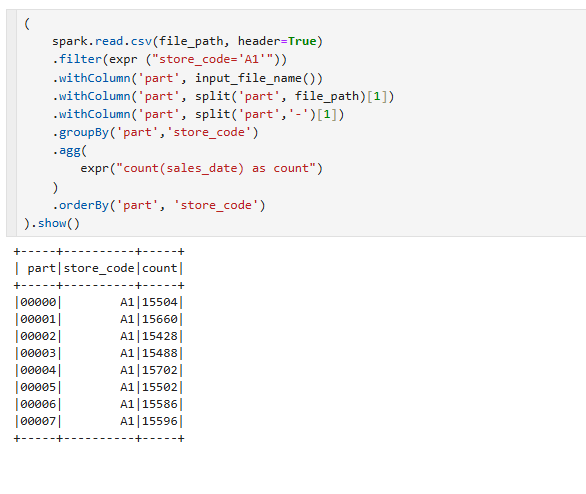
A1 점포에 대해서 한번 불러와 보도록 하겠습니다.

groupby를 해주고 agg에 expr을 해서 count해준 결과입니다. 실제로 partition 0에 대해서만 A1으로 해서 Count가 집계가 된걸 알수가 있습니다. 그러면 똑같이 명령을 복사해서 이번에는 원래의 file_path와 비교해보도록 하겠습니다.
이와같이 A1에서만 필터링한다고 하면 전문용어로 predicate pushdown이라고 합니다.
아래같은경우에는 연산이 조금더 복잡하고 shuffle이 많이 발생하는 구조가 되기때문에 지금 데이터가 그렇게 많치않은 데이터이지만 데이터량이 방대하다고 가정했을때는 파티션이 잘되어있지 않게 되면 Spark의 연산의 퍼포먼스가 많이 떨어지게 됩니다.
databrick에서는 z-ordering이라고하는 이름을 줘서 해당 partitioning을 하는 기법이 있습니다.
실제 델타 테이블에 적용되는 개념이고 이와같이 csv파일을 저장하는 개념에서는 z-ordering이라고 부르진 않습니다.
z-ordering과 같은 파티션 최적화의 개념이 무엇인지 이해하기위해서 한번 만들어 봤습니다
'Spark' 카테고리의 다른 글
| [Spark] - Spark Performance Tuning (0) | 2026.03.28 |
|---|---|
| [Spark] - Spark (0) | 2026.03.27 |
| [Spark] - Json 데이터 다루기(with_Explode) (0) | 2026.03.24 |
| [Spark] - Null값 처리 (0) | 2026.03.24 |
| [Spark] - 정규식을 통한 문자열 처리 (0) | 2026.03.23 |