Spark를 사용하다 보면 단순한 코드 작성보다 더 중요한 것이 있습니다.
바로 데이터를 어떻게 나누고, 어떻게 이동시키고, 어떻게 실행하느냐입니다.
같은 코드라도 Partition, Shuffle, Join 전략에 따라 성능은 몇 배 이상 차이가 납니다.
이 글에서는 Spark의 내부 실행 구조를 기반으로
Compute, Data, Execution, Skew, AQE까지 이어지는 실무 성능 튜닝 프레임워크를 정리합니다.
단순 개념이 아니라, “왜 느려지는지 → 어디를 봐야 하는지 → 어떻게 해결하는지” 흐름 중심으로 정리해보려 합니다.
Spark Performance Tuning
데이터 분배, 이동, 실행 방식을 최적화하여 처리 속도와 자원 효율을 개선하는 것
Spark 튜닝 프레임워크
Spark Performance Tuning
1. Compute Layer (연산 구조 최적화)
- Partition
- Shuffle
- Join Strategy
- Broadcast Hash Join
- Sort Merge Join
- Repartition / Coalesce 전략
- Narrow vs Wide 구분
- DAG / Stage 구조 이해
2. Data Layer (I/O 최적화)
- Format (Parquet)
- Partitioning
- File Size
- Column Pruning
- Predicate Pushdown
- Partition Pruning
- Small file 문제
3. Execution Layer (실행 효율)
- cache() / persist()
- unpersist()
- StorageLevel 선택
- Memory tuning
- Execution vs Storage memory
- spill 방지
- off-heap memory
4. Skew Handling (병목 제거)
- Salting
- Broadcast
- AQE Skew
- skew detection (Spark UI)
- heavy key 분리 처리
5. Runtime Optimization (자동 최적화)
- AQE
- Skew join handling
- Join strategy 변경
- Partition coalescing
Spark Performance Tuning 전체구조
1. Compute Layer → 연산 구조
2. Data Layer → I/O 최적화
3. Execution Layer → 메모리 & 재사용
4. Skew Handling → 병목 제거
5. Runtime Optimization → AQE 자동 최적화
1.Compute Layer
Compute Layer는 Spark에서 데이터 처리 방식과 연산 전략을 결정하는 계층으로, Partitioning, Shuffle, Join Strategy, DAG 구조 등을 통해 병렬 처리와 성능에 직접적인 영향을 줍니다
Spark의 Compute Layer 최적화는 결국 데이터 이동(Shuffle)을 최소화하고 병렬성을 극대화하는 것에 집중됩니다. 실무에서 가장 자주 쓰이는 최적화 기법들을 PySpark 코드 예시와 함께 보도록 하겠습니다.
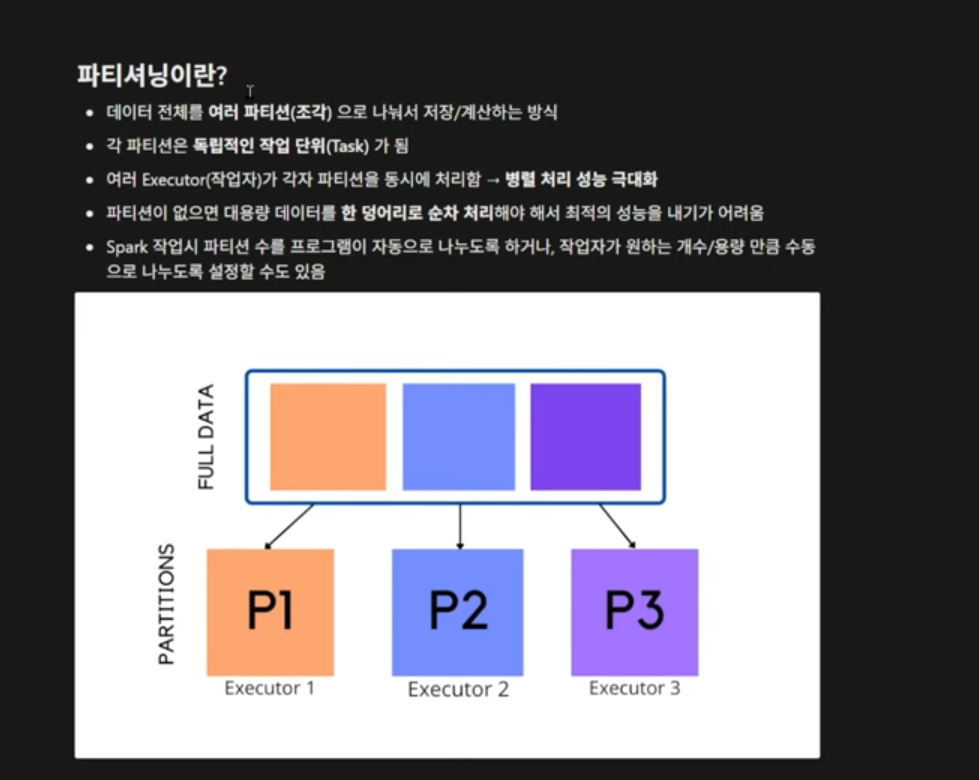
Partition (데이터 분할 단위)
파티션을 쪼개는 명령어
# 1. 현재 파티션 개수 확인
print(f"Current Partitions: {df.rdd.getNumPartitions()}")
# 2. 파티션 강제 재분배 (Repartition) - 전체 데이터를 셔플하여 균등하게 나눔
# CPU 코어 수의 2~3배 정도로 설정하는 것이 일반적입니다.
df_repartitioned = df.repartition(10)
# 3. 파티션 축소 (Coalesce) - 셔플을 최소화하며 파티션 수를 줄임 (저장 직전 권장)
df_coalesced = df.coalesce(2)
# 4. 특정 컬럼 기준으로 파티션 나누기 (데이터 스큐 방지 및 조인 최적화)
df_by_key = df.repartition(10, "user_id")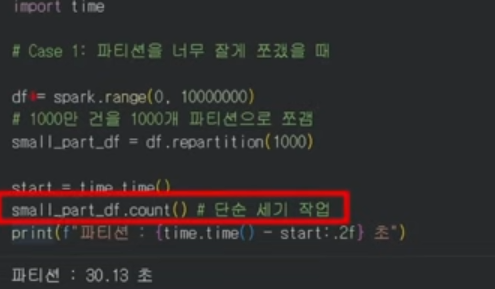


파티션은 Spark가 병렬로 처리하는 최소 작업 단위입니다. 파티션 하나당 CPU 코어(Task) 하나가 할당됩니다.
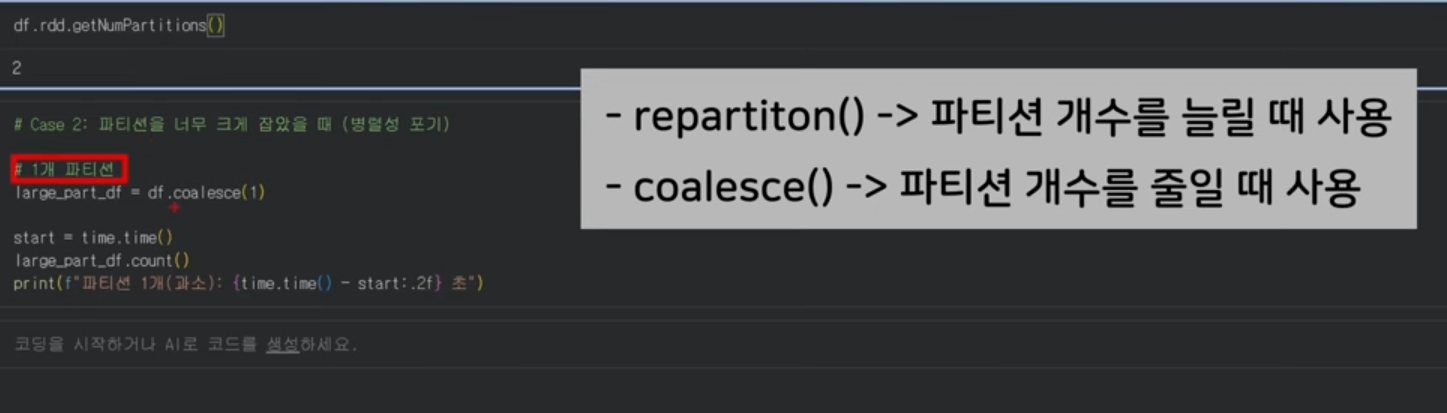
Repartition vs Coalesce (파티션 제어)
데이터의 병렬 처리 단위인 파티션을 어떻게 관리하느냐에 따라 리소스 효율이 달라집니다.
- repartition(n): 데이터를 전체적으로 다시 섞어(Full Shuffle) 파티션을 균등하게 나눕니다. 병렬성을 높여야 할 때 사용합니다.
- coalesce(n): 셔플을 최소화하며 파티션 수를 줄입니다. 주로 필터링 후 데이터가 작아졌을 때 파일을 저장하기 직전 사용합니다.
# 1. 병렬성이 부족하여 태스크를 늘려야 할 때 (Wide Transformation 전)
df = df.repartition(200)
# 2. 데이터 필터링 후 파티션이 너무 많아져서 파일 개수를 줄여야 할 때 (저장 직전)
df.filter("region = 'KR'") \
.coalesce(10) \
.write.parquet("output_path")최적의 파티션 수 공식
보통 Spark UI의 Stage 탭에서 Task의 실행 시간을 보고 판단합니다.
- Task가 너무 빨리 끝남 (100ms 이하): 파티션이 너무 많음 (스케줄링 오버헤드 발생).
- Task가 너무 오래 걸림 (수 분 이상): 파티션이 너무 적음 (메모리 부족 위험).
- 가이드라인: 파티션당 데이터 크기를 128MB ~ 256MB 정도로 유지하는 것이 가장 이상적입니다.
파티션의 기본용량

Shuffle (데이터 재배치)
셔플은 조인(Join),그룹화(GroupBy),재분배(Repartition) 등 데이터의 위치를 옮겨야 할 때 발생합니다. Spark에서 가장 비용이 많이 드는(가장 느린) 작업입니다.
셔플을 유발하는 연산 (Wide Transformation)
# 1. GroupBy: 동일한 키를 가진 데이터를 한곳으로 모아야 함 (Shuffle 발생)
df_grouped = df.groupBy("department").avg("salary")
# 2. Join: 서로 다른 테이블의 같은 키를 매칭하기 위해 데이터를 이동 (Shuffle 발생)
df_joined = df1.join(df2, "employee_id")
# 3. Distinct: 중복 제거를 위해 데이터를 비교해야 함 (Shuffle 발생)
df_unique = df.select("user_id").distinct()
셔플 최적화 핵심 팁
1.Shuffle Write/Read 줄이기: Spark UI에서 Shuffle Write 값이 큰 스테이지를 찾으세요. 데이터 필터링(filter)이나 컬럼 선택(select)을 셔플 연산 이전에 수행하여 이동하는 데이터 양 자체를 줄여야 합니다.
2.spark.sql.shuffle.partitions 설정:
- 기본값은 200입니다.
- 데이터가 아주 작으면 이 값을 줄여야 하고(예: 10~50), 데이터가 수 TB 단위라면 늘려야 합니다(예: 1000~2000).
- AQE(Adaptive Query Execution)를 켜면 Spark가 런타임에 이 값을 자동으로 조절해 줍니다.
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
Partition과 Shuffle의 관계
| 개념 | 설명 | 성능 영향 |
| Partition | 데이터의 조각 | 너무 적으면 OOM(메모리 부족), 너무 많으면 관리 부하 증가 |
| Shuffle | 파티션 간 데이터 이동 | 성능 저하의 주범. 네트워크/디스크 I/O 발생 |

Join Strategy: Broadcast Hash Join (BHJ)

굉장히 큰 데이터와 진짜 작은 데이터의 join일 경우 효율적인 join방식 입니다.
대용량 데이터 같은 경우에는 여러노드에 걸처서 데이터가 분산 저장되어있습니다.
join하고자 하는 작은데이터도 굳이 쪼개서 저장하게 될경우 또 셔플이 일어나게되고 정렬과정이 일어나면서 리소스를 많이 잡아먹게 된다. 작은 용량의 데이터 같은경우 모든 워커로 복사를 하게됩니다.

셔플이 일어나지 않고 join이 될수있도록 만드는 방법입니다.


기본적으로는 10MB이하로 디폴트로 고정이 되어있습니다. 이 기본값은 Spark설정에서 바꿀수있지만 10MB이하일경우에는 기본적으로 Broadcast join이 되도록 설정이 되어있습니다
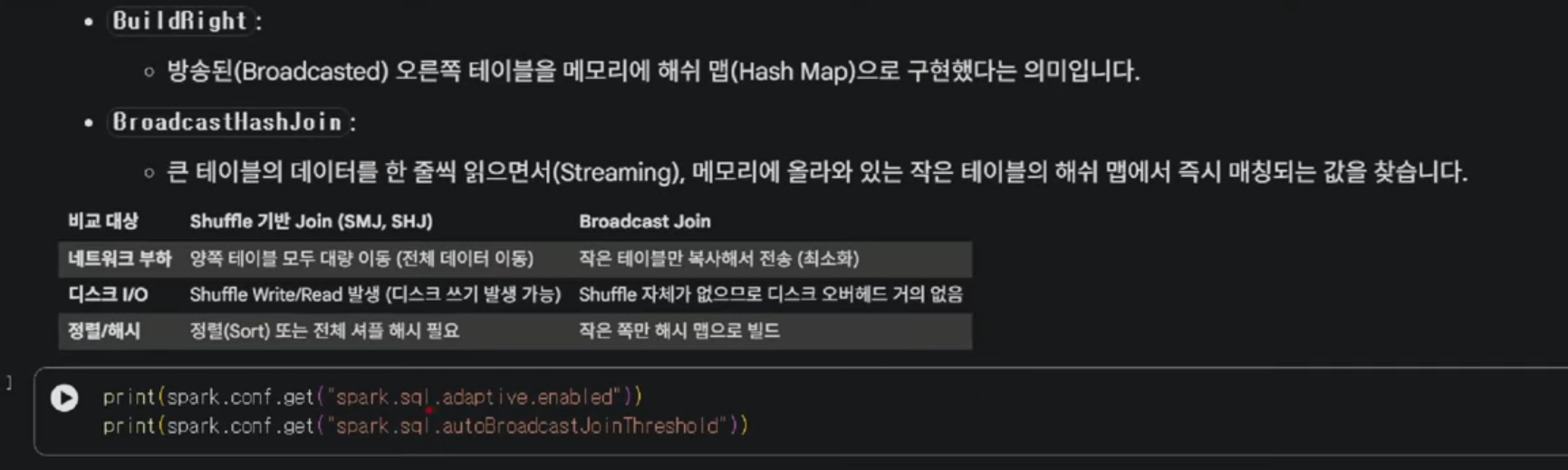
print를 해보게되면 10MB가 true로 찍혀있는모습을 확인할수있습니다.

broadcast 튜닝기법
from pyspark.sql.functions import broadcast
# 큰 테이블 (Sales)과 아주 작은 테이블 (Code_Master) 조인
large_df = spark.table("sales_data")
small_df = spark.table("item_codes")
# broadcast() 힌트를 사용하여 BHJ 유도
optimized_join = large_df.join(broadcast(small_df), "item_id")
가장 효과적인 최적화입니다. 작은 테이블을 모든 Executor에 복제하여 셔플(Shuffle) 없이 조인을 수행합니다.
내부동작은 small_df를 Drive가 수집을하게되고 Executor들로 모든 워커노드에 small_df를 복사하게됩니다
각 Executort에서 localjoin을 수행하게 됩니다. 그렇게 되면 large_df는 분산 상태 그대로 유지가 되고 small_df는 각 노드에 있게됩니다 Network가 최소화되고 속도가 매우 빠릅니다.
- 적용 대상: 한쪽 테이블이 메모리에 올릴 만큼 충분히 작을 때 (기본값 10MB, 설정으로 조정 가능).
- 효과: 네트워크를 통한 데이터 재배치 과정이 생략되어 속도가 획기적으로 빨라집니다.
Sort Merge Join(SMJ)
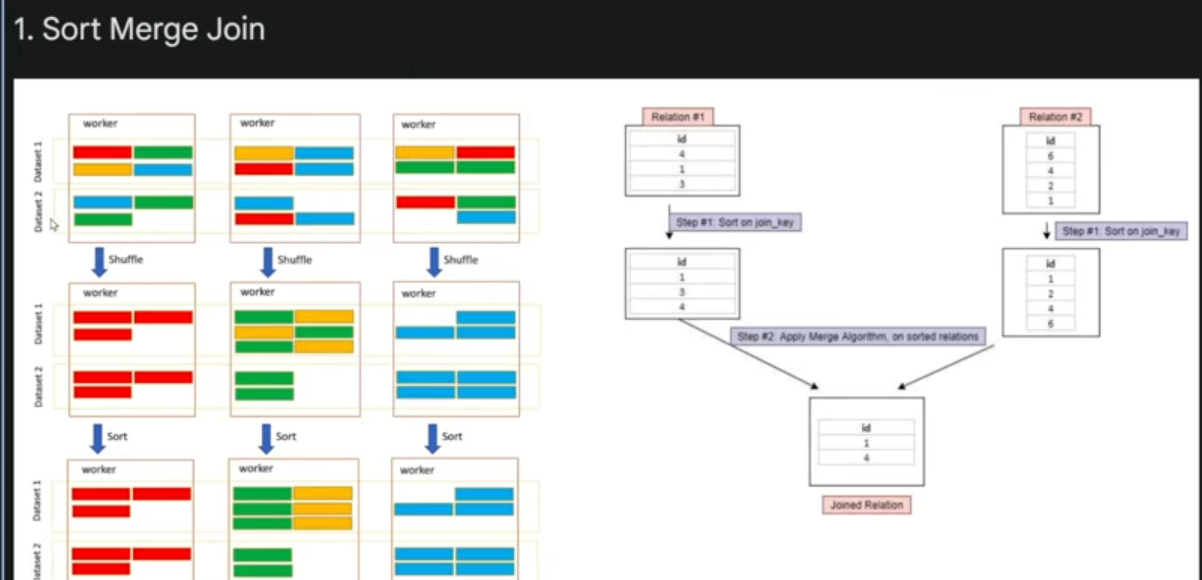
join은 shuffle을 하여 리소스를 많이 잡아 먹는 연산입니다.
워커가 3개가있는 클러스터에 데이터가 분산되어있으면 join을 하기위해선 두테이블의 키가 같아야 됩니다.
두키를 하나의 워커노드로 몰아주는 셔플이 일어나게 됩니다.
결론적으로는 셔플이 일어나고 정렬까지 일어난다음에 join이 발생하는 연산입니다.
위에 그림처럼 각 색깔별로 모아지는 과정이 먼저 발생을하게됩니다. 그다음 모아졌다면 sorting하는 과정이 생깁니다.


실습으로 만들었던 fact테이블과 디멘션 테이블을 가지고 join을 하였고 id기반으로 inner join을 했습니다
이 작업에 대해서 explain을 던져서 실행계획을 보는거를 찍어 보도록 하겠습니다.

# 1. 환경 설정 (명시적으로 SMJ를 선호하도록 설정)
spark.conf.set("spark.sql.join.preferSortMergeJoin", "true")
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1") # 브로드캐스트 방지 (테스트용)
# 2. 대용량 데이터프레임 생성 (예시)
large_df_1 = spark.table("huge_sales_data")
large_df_2 = spark.table("huge_customer_data")
# 3. Join 실행
# 별도의 힌트 없이도 대용량 vs 대용량이면 SMJ가 발생함
smj_result = large_df_1.join(large_df_2, "customer_id", "inner")
# 4. 실행 계획 확인 (Physical Plan에서 SortMergeJoin 확인)
smj_result.explain()explain() 출력 예시
== Physical Plan ==
*(3) SortMergeJoin [customer_id#10], [customer_id#50], Inner
:- *(1) Sort [customer_id#10 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(customer_id#10, 200)
+- *(2) Sort [customer_id#50 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(customer_id#50, 200)- Exchange: Shuffle 단계를 의미합니다.
- Sort: Merge 전 정렬 단계를 의미합니다.
Sort Merge Join 최적화 포인트 (Bucketing)
SMJ의 가장 큰 비용은 Shuffle과 Sort입니다. 만약 동일한 키로 조인을 자주 한다면, 데이터를 저장할 때 미리 Bucketing을 해두어 이 비용을 제거할 수 있습니다.
Bucketing = Shuffle 없이 같은 키 데이터를 같은 파티션에 미리 정렬해서 저장
아래 코드와 같이 같은 bucket key일때만 최적화 조건이 적용됩니다. 조건이 충족되면 바로 merge처리가 됩니다.
# 데이터를 저장할 때 미리 조인 키로 버켓팅하여 저장
large_df_1.write \
.bucketBy(100, "customer_id") \
.sortBy("customer_id") \
.saveAsTable("bucketed_sales")
large_df_2.write \
.bucketBy(100, "customer_id") \
.sortBy("customer_id") \
.saveAsTable("bucketed_customers")
# 이후 조인 시 Shuffle과 Sort가 생략됨 (성능 극대화)
df1 = spark.table("bucketed_sales")
df2 = spark.table("bucketed_customers")
optimized_smj = df1.join(df2, "customer_id")Sort Merge Join 주요단계 분석

BHJ VS SMJ
| 특징 | Broadcast Hash Join (BHJ) | Sort Merge Join (SMJ) |
| 데이터 크기 | 한쪽이 매우 작음 (기본 < 10MB) | 둘 다 매우 큼 |
| 셔플 여부 | 없음 (네트워크 부하 적음) | 있음 (네트워크 부하 높음) |
| 정렬 여부 | 필요 없음 | 필수 |
| 안정성 | 메모리 초과(OOM) 위험 있음 | 매우 안정적 (Disk 사용 가능) |
Narrow vs Wide Transformation 구분
# Narrow Transformation (셔플 없음 - 빠름)
# 각 파티션 내에서 독립적으로 실행됨
df_narrow = df.filter(df.age > 20).select("name", "age")
# Wide Transformation (셔플 발생 - 비용 높음)
# 데이터를 네트워크로 주고받아야 함
df_wide = df.groupBy("age").count()
코드를 짤 때 내가 쓰는 함수가 셔플을 유발하는지 아는 것이 중요합니다.
Window Function 최적화 (PartitionBy)
윈도우 함수(row_number, rank 등)사용 시 특정 키에 데이터가 몰리면 성능이 급격히 저하됩니다. 이때 윈도우 범위를 적절히 설정하는 것이 중요합니다.
from pyspark.sql.window import Window
from pyspark.sql.functions import row_number
# 잘못된 예: 모든 데이터를 하나의 파티션으로 모으는 행위 (OOM 위험)
# window_spec = Window.orderBy("timestamp")
# 권장 예: 반드시 partitionBy를 함께 사용하여 분산 처리 유도
window_spec = Window.partitionBy("user_id").orderBy("timestamp")
df.withColumn("rank", row_number().over(window_spec))
user_id 기준으로 그룹 나눔
→ 각 그룹 안에서만 정렬 + row_number 수행
User Defined Functions (UDF) 지양
Python UDF는 JVM과 Python 프로세스 간의 데이터 직렬화/역직렬화 비용이 매우 큽니다. 가급적 Built-in Functions(Spark SQL)를 사용하세요.
# 비효율적인 방식 (Python UDF)
from pyspark.sql.functions import udf
@udf("string")
def upper_udf(s):
return s.upper() if s else None
# 효율적인 방식 (Spark Native Function) - 내부적으로 최적화됨
from pyspark.sql.functions import upper
df.withColumn("name_upper", upper(df["name"]))
UDF를 가급적으로 피해야하는 이유는 Native가 왜빠른지에 대한코드입니다.
Python 코드를 사용하였을때는
1️⃣ JVM → Python 데이터 전달
2️⃣ Python에서 실행
3️⃣ 다시 JVM으로 반환
이과정에서
- Serialization 비용 발생
- CPU 컨텍스트 스위칭
- 병렬 처리 효율 ↓
“동일한 로직이라도 Python UDF는 JVM과 Python 간 데이터 직렬화 비용과 Catalyst 최적화 비활성화로 인해 성능 저하가 발생하므로, 가능한 경우 Spark의 built-in 함수를 사용하는 것이 바람직합니다.”
수십만 건 → 차이 적음
수억 건 → 몇 배 이상 차이
DAG 및 Stage 구조 확인을 위한 Spark UI 활용
코드를 짠 후에는 반드시 Spark UI의 SQL 탭에서 DAG(Directed Acyclic Graph)를 확인해야 합니다.
# 실행 계획(Physical Plan) 출력
df.explain()- Exchange: 셔플이 발생하고 있음을 의미합니다. 이 부분이 너무 많다면 Join이나 GroupBy 전략을 다시 점검해야 합니다.
- WholeStageCodegen: 여러 연산이 하나의 단계로 합쳐져 최적화되었는지 확인합니다.
2. Data Layer (I/O 최적화)
Spark 성능 튜닝의 두 번째 단계인 Data Layer (I/O 최적화)는 데이터를 읽고 쓰는 과정에서 발생하는 병목을 제거하는 것이 핵심입니다. "필요한 데이터만, 가장 효율적인 크기로 읽는다"는 원칙을 실현하는 구체적인 코드입니다.
Format (Parquet) & Column Pruning (동적 파티션 프루닝)
이 프루닝이 한글로 번역을 하면 가지치기라는 뜻이다.

풀스캔 하라고 명령을 던져도 내부적으로 이것들은 스캔할 필요가 없다고 판단이 되어지면 그런것들은 따로 스캔하지 않고 진짜 필요한것들만 스캔을해서 그만큼 작업의 효율을 높이는 최적화 방식입니다. 이것도 이해가안되면 정말 쉽게 설명하자면
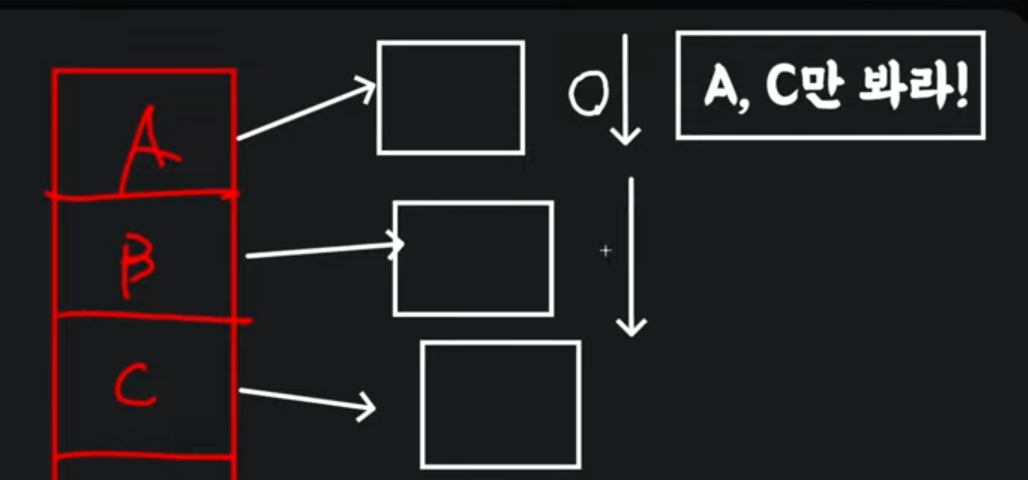
활성전에는 풀스캔때리면서 A부터 C까지 전체스캔을 통하지만 활성화가 되어있으면 A랑 C만 체크하게 됩니다.
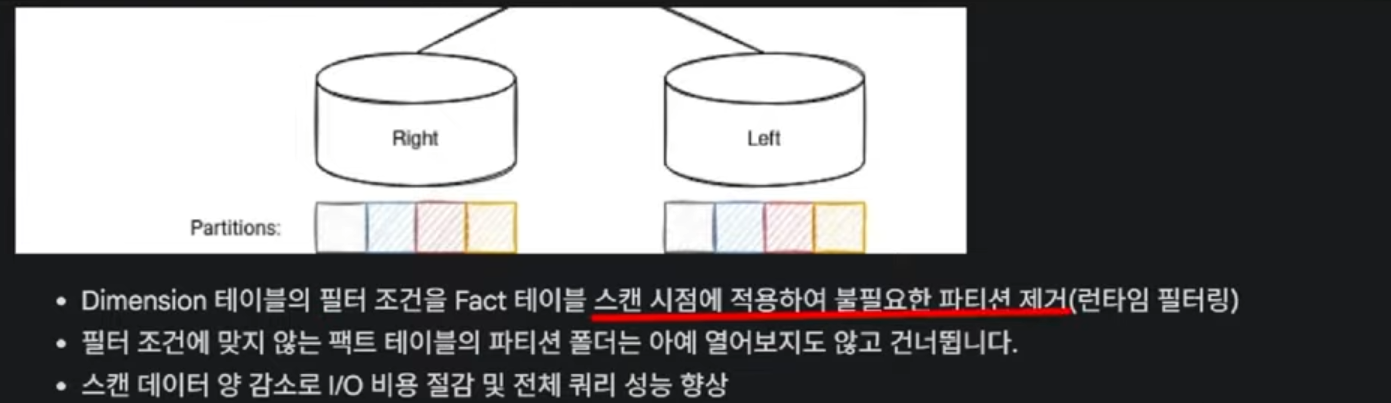
작업이 진행되는동안 자동적으로 제거를 해주게됩니다(런타임 필터링!)
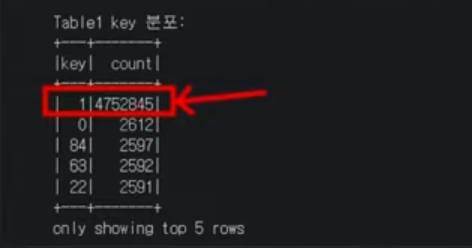
제가 만약쿼리를 던져서 1번인 Electronics를 filter를 찾는 쿼리를 던졌다고 가정해보고 AQE 전과 후의 차이를 보여드리도록 하겠습니다.


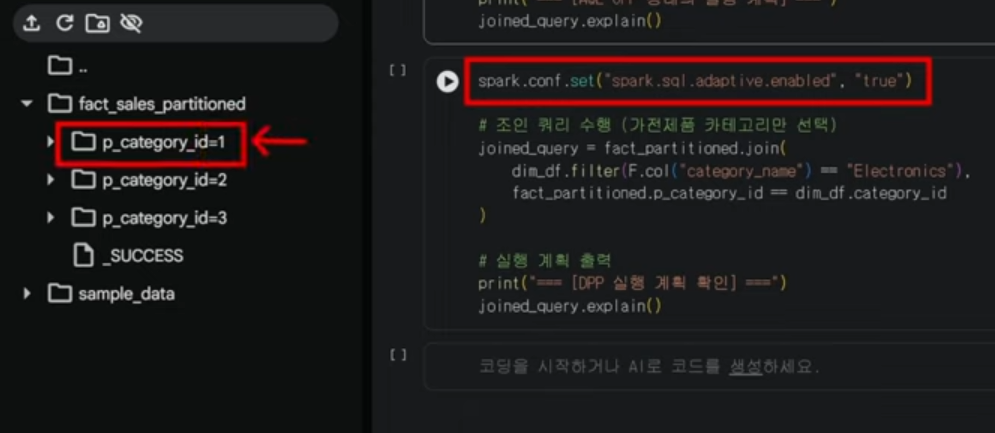

CSV나 JSON 같은 텍스트 포맷 대신 Parquet(열 지향 저장소)을 사용하면, 필요한 컬럼만 선택해서 읽는 Column Pruning이 엔진 수준에서 자동으로 이루어집니다.
# 1. Parquet 형식으로 저장 (압축률과 I/O 효율이 가장 좋음)
df.write.mode("overwrite").parquet("data/sales_parquet")
# 2. Column Pruning 실습
# 전체 100개 컬럼 중 2개만 선택하면, Spark는 디스크에서 해당 컬럼의 블록만 읽어옵니다.
optimized_df = spark.read.parquet("data/sales_parquet") \
.select("user_id", "amount")
optimized_df.explain() # 계획서에 'ReadSchema' 부분에 선택한 컬럼만 나타남
Column Pruning: 필요한 컬럼만 읽고, 나머지는 아예 읽지 않는 최적화

Partitioning & Partition Pruning
데이터를 물리적으로 디렉토리 구조(예: year=2023/month=10)로 나누어 저장하면, 조건에 맞는 디렉토리만 스캔하는 Partition Pruning이 작동합니다.
# 1. 특정 컬럼 기준으로 파티셔닝하여 저장
df.write.partitionBy("event_date", "region").parquet("data/events")
# 2. Partition Pruning 실습
# 이 쿼리는 전체 데이터를 뒤지는 것이 아니라 'event_date=2023-10-01' 폴더만 스캔합니다.
filtered_df = spark.read.parquet("data/events") \
.filter("event_date = '2023-10-01' AND region = 'KR'")
filtered_df.explain() # 'PartitionFilters' 항목에 조건이 포함된 것을 확인 가능
Partition Pruning : 필요한 파티션(파일/디렉토리)만 읽고, 나머지는 아예 스킵하는 최적화

Predicate Pushdown
필터 조건(filter, where)을 데이터 소스(저장소) 레벨로 내려보내, 메모리로 올리기 전에 데이터를 걸러내는 기술입니다. Parquet/ORC 포맷에서 가장 잘 작동합니다.
# Spark은 filter 조건을 분석하여 최대한 저장소 단에서 걸러내도록 명령합니다.
# 아래 코드 실행 시 실제 'amount > 1000' 조건은 스캔 단계에서 적용됩니다.
df = spark.read.parquet("data/sales") \
.filter(df.amount > 1000)
df.explain() # 'PushedFilters' 항목에 [GreaterThan(amount, 1000)] 확인
필터 조건을 최대한 데이터 소스까지 내려보내서, 읽을 데이터 자체를 줄이는 것
PushedFilters에 뜨면 → 실제로 데이터 읽기 전에 필터 적용된 것입니다.
parquet은 컬럼기반저장 + 통계 존재하기때문에 이파일에서 amount > 1000이 있는지 메타데이터로 판단 가능합니다.
“Parquet 데이터 소스를 사용할 경우 Spark는 filter 조건을 분석하여 PushedFilters 형태로 데이터 스캔 단계에 적용하며, 이를 통해 불필요한 데이터를 읽지 않아 I/O 비용을 크게 줄일 수 있습니다
Small File 문제 해결 (File Size 최적화)
파일 크기가 너무 작으면(수 KB 단위 등) 메타데이터 관리 부하가 커지고 스캔 속도가 느려집니다. 이를 방지하기 위해 저장 시 적절한 크기로 합쳐줘야 합니다.
# 1. 저장 시 Coalesce를 사용하여 파일 개수 줄이기
# 파티션당 약 128MB ~ 256MB가 되도록 설정하는 것이 이상적입니다.
df.coalesce(5).write.parquet("data/optimized_files")
# 2. Spark 3.x AQE를 이용한 읽기 시 자동 병합
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
# 3. 이미 작은 파일이 많은 경우 (Compaction 작업)
# 작은 파일들이 가득한 경로를 읽어서 다시 적절한 수의 파티션으로 덮어쓰기
spark.read.parquet("data/small_files_dir") \
.repartition(10) \
.write.mode("overwrite").parquet("data/compacted_files")
데이터 이미 균등하게 분산되어 있음 + 파일 개수만 줄이고 싶을 때 사용
Small File 문제 = "파일이 너무 많아서 처리 오버헤드가 폭발하는 문제"
Small File 해결 = "쓰기 때 줄이고 + 읽을 때 자동 최적화 + 이미 쌓인 건 재정리"
“Small File 문제는 과도한 파일 수로 인해 I/O와 Task 스케줄링 오버헤드가 증가하는 문제이며, 이를 해결하기 위해 쓰기 시 repartition 또는 coalesce로 파일 수를 줄이고, AQE를 활용해 실행 시 파티션을 최적화하며, 이미 생성된 작은 파일은 compaction을 통해 재정리합니다.”
I/O 관련 주요 설정 (Tips)
데이터 레이어 최적화를 위해 코드 외에 설정값으로 조절할 수 있는 부분들입니다.
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
spark.conf.set("spark.sql.shuffle.partitions", 200)
spark.conf.set("spark.sql.files.maxPartitionBytes", 134217728)
spark.conf.set("spark.sql.files.openCostInBytes", 4194304)
spark.conf.set("spark.sql.parquet.filterPushdown", "true")핵심 설정 요약
| 설정 | 역할 |
| maxPartitionBytes | 읽기 단위 크기 |
| shuffle.partitions | 병렬 처리 개수 |
| openCostInBytes | 파일 open 비용 |
| AQE | 실행 중 최적화 |
| coalescePartitions | 파티션 자동 병합 |
| maxRecordsPerFile | 파일 크기 제어 |
| filterPushdown | 읽기 데이터 최소화 |
3. Execution Layer
Spark 성능 튜닝의 세 번째 단계인 Execution Layer는 데이터가 메모리에 적재된 후의 실행 효율을 다룹니다. 연산 결과를 어떻게 재사용하고, 한정된 메모리를 어떻게 나누어 쓰며, 디스크 스필(Spill)을 어떻게 방지할지가 핵심입니다.
Cache & Persist (데이터 재사용)
동일한 DataFrame을 여러 액션(Action)에서 반복 사용할 때 메모리에 올려두는 전략입니다
from pyspark import StorageLevel
# 1. cache(): 메모리에만 저장 (MEMORY_AND_DISK가 기본인 경우도 있음)
df = spark.read.parquet("large_data").filter("amount > 1000")
df.cache()
# 2. persist(): 저장 수준을 세밀하게 제어
# MEMORY_AND_DISK_SER: 메모리가 부족하면 디스크에 쓰고, 직렬화하여 용량 아낌
df_persisted = df.persist(StorageLevel.MEMORY_AND_DISK_SER)
# 3. 사용 후 반드시 해제 (메모리 확보)
df.unpersist()
cache()는 만능이 아닙니다. 단 한 번만 사용하는 DataFrame에 사용하면 오히려 캐싱을 위한 오버헤드(직렬화, 메모리 점유) 때문에 더 느려집니다.
Memory Tuning (메모리 구조 이해)
Executor 메모리는 크게 두 영역으로 나뉩니다. 이 비율을 조정하여 성능을 최적화할 수 있습니다.
- Execution Memory: Join, Shuffle, Sort 연산 시 사용
- Storage Memory: cache(), persist() 시 사용
# 전체 메모리 중 Spark이 사용할 비율 (기본 0.6)
spark.conf.set("spark.memory.fraction", "0.8")
# Spark 메모리 중 Storage가 차지할 비율 (기본 0.5)
# 캐시를 많이 안 쓴다면 이 값을 낮춰서 Execution 영역을 확보하세요.
spark.conf.set("spark.memory.storageFraction", "0.3")
# Off-heap 메모리 사용 (JVM 밖의 메모리 사용으로 GC 부하 감소)
spark.conf.set("spark.memory.offHeap.enabled", "true")
spark.conf.set("spark.memory.offHeap.size", "2g")Spill 방지 (Disk Spill 제거)
Spill = "한 파티션 데이터가 너무 큼"
Spill은 Execution 메모리가 부족하여 데이터를 디스크에 임시로 쓰는 현상입니다. 셔플이나 조인이 급격히 느려지는 주범입니다.
spark.conf.set("spark.sql.shuffle.partitions", "400")
Spill 확인 및 해결 방법
1. Partition 충분한가?
2. Skew 있는가?
3. Broadcast 가능?
4. Memory 부족?
- Spark UI 확인: Stage 상세 페이지에서 "Shuffle Spill (Disk)" 항목이 0보다 크다면 문제가 있는 것입니다.
- 해결 코드:
- 파티션 수를 늘려 개별 태스크가 처리하는 데이터양을 줄입니다.
- spark.executor.memory 값을 높입니다.
- 메모리 내 연산 효율을 높이기 위해 spark.sql.shuffle.partitions를 조절합니다.
Spill 방지 = "데이터를 잘게 나누고, 메모리를 충분히 확보"
GC(Garbage Collection) 최적화
GC란 = "더 이상 사용하지 않는 메모리를 자동으로 정리하는 것"
Spark은 JVM 위에서 돌아가므로 객체가 많아지면 GC 오버헤드가 발생합니다.
“보이지 않지만 성능을 크게 깎아먹는 영역” = GC 최적화
# Kryo Serializer 설정 (기본보다 빠르고 작음)
spark.conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
# 런타임 시 G1GC 사용 설정 (spark-submit 시 적용)
# --conf "spark.executor.extraJavaOptions=-XX:+UseG1GC"
- 해결책: * 직렬화(Serialization): Kryo Serializer를 사용하여 객체 크기를 줄입니다.
- G1GC 사용: 최신 JVM에서는 G1GC가 대용량 메모리 처리에 유리합니다.
GC 종류 비교
| GC | 특징 |
| ParallelGC | 빠르지만 pause 큼 |
| CMS | deprecated |
| G1GC | 균형형 (추천) |
핵심 요약 테이블
| 최적화 항목 | 권장 전략 | 비고 |
| Caching | MEMORY_AND_DISK_SER 추천 | 직렬화로 메모리 효율 증대 |
| Spill 제거 | 파티션 개수 증가 | Spark UI 모니터링 필수 |
| Off-heap | 대용량 Join 시 활성화 | GC 부하 감소 효과 |
| Memory Ratio | 캐시 적으면 storageFraction 하향 | 연산 메모리(Execution) 확보 |
4.Skew Handling(데이터 불균형 제거)
Data Skew란 특정 키에 데이터가 몰려, 100개의 태스크 중 99개는 1초 만에 끝나는데 단 1개의 태스크만 30분 동안 돌아가는 현상을 말합니다. 이를 해결하는 구체적인 전략과 코드입니다.
Skew Detection (현상 파악)
코드를 짜기 전, Spark UI를 통해 Skew를 확인하는 것이 우선입니다.
- Stage 탭: Tasks 목록에서 Max 실행 시간이 Median 실행 시간보다 압도적으로 길고, 특정 Executor의 Shuffle Read Size가 유독 크다면 100% Skew입니다.
Salting 기법
Salting = "쏠린 데이터를 인위적으로 쪼개서 여러 노드로 분산시키는 기술"
Salting은 Data Skew를 해결하기 위해 특정 key에 랜덤 값을 추가하여
여러 Partition으로 분산시키는 기법으로, 특히 Join 연산에서 성능 개선에 효과적입니다
- user_id = A → 90%
user_id = B,C,D → 10%
아래 코드는 조인 키에 임의의 숫자(Salt)를 붙여 데이터를 강제로 분산시킨 뒤 조인하는 방식입니다.
from pyspark.sql import functions as F
import random
# 1. Skew가 발생한 테이블 (예: 대용량 로그)에 Salt 추가
# 0~9 사이의 랜덤 숫자를 키 뒤에 붙임
skewed_df = spark.table("large_log_data")
salted_df = skewed_df.withColumn("salt", (F.rand() * 10).cast("int")) \
.withColumn("salted_key", F.concat(F.col("user_id"), F.lit("_"), F.col("salt")))
# 2. 상대적으로 작은 테이블 (예: 유저 마스터)을 10배로 복제 (Explode)
# Salt 값 0~9에 모두 대응할 수 있도록 행을 늘림
small_df = spark.table("user_master")
salt_values = spark.range(10).withColumnRenamed("id", "salt")
expanded_small_df = small_df.crossJoin(salt_values) \
.withColumn("salted_key", F.concat(F.col("user_id"), F.lit("_"), F.col("salt")))
# 3. Salted Key로 Join 실행 (데이터가 분산되어 병목 제거)
result = salted_df.join(expanded_small_df, "salted_key")AQE Skew Join Optimization (자동화)
Spark 3.0 이상이라면 복잡한 Salting 코드 대신 AQE(Adaptive Query Execution) 기능을 켜서 해결할 수 있습니다.
- 동작 원리: 실행 중에 Skew를 감지하면 Spark가 알아서 해당 파티션을 더 작은 단위로 쪼개어 처리합니다.
# AQE 활성화 및 Skew Join 최적화 옵션 켜기
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true")
# Skew라고 판단할 기준 설정 (기본값보다 낮게 잡으면 더 공격적으로 최적화)
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "5")
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes", "256mb")Heavy Key 분리 처리 (Filtering)
특정 키(예: 'Guest' 유저나 'NULL' 값)가 전체의 80%를 차지하는 경우, 이들만 따로 떼어내서 처리하는 전략입니다.
# 1. Null이나 특정 Heavy Key 분리
heavy_key_df = df.filter("user_id IS NULL OR user_id = 'GUEST'")
normal_df = df.filter("user_id IS NOT NULL AND user_id != 'GUEST'")
# 2. Heavy Key는 별도 로직으로 처리 (예: Join 대신 단순 필터링 등)
# 3. 정상 데이터만 Join 수행 후 나중에 Union
result = normal_df.join(other_df, "user_id").union(heavy_key_df_processed)핵심 요약 및 전략 선택
| 상황 | 추천 전략 | 특징 |
| 일반적인 대용량 조인 | AQE Skew Join | 설정만으로 자동 해결되므로 1순위 고려 |
| AQE로 해결 안 되는 극심한 Skew | Salting | 코드는 복잡하나 가장 확실하게 데이터를 분산함 |
| 특정 키(NULL 등)가 원인일 때 | Filter & Union | 불필요한 연산을 원천 차단 |
| 작은 테이블과의 조인 시 | Broadcast Join | 셔플 자체가 발생 안 하므로 Skew 영향 없음 |
5. Runtime Optimization (AQE: Adaptive Query Execution)

기존의 Spark은 실행 전(Compile Time)에 수립한 실행 계획을 끝까지 밀고 나갔습니다. 하지만 AQE는 실행 중(Runtime)에 수집된 통계 정보를 바탕으로 실행 계획을 동적으로 변경합니다. "일단 해보고, 데이터가 생각보다 작으면 전략을 바꾸자!"는 똑똑한 방식입니다

AQE 활성화 (기본 설정)
AQE를 사용하려면 먼저 기능을 켜야 합니다. (Spark 3.2+ 부터는 기본값이 true이지만, 명시적으로 관리하는 것이 좋습니다.)
# AQE 전체 활성화
spark.conf.set("spark.sql.adaptive.enabled", "true")
# Runtime 최적화를 위한 최소/최대 파티션 크기 설정
spark.conf.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "128mb")
Coalescing Post-shuffle Partitions
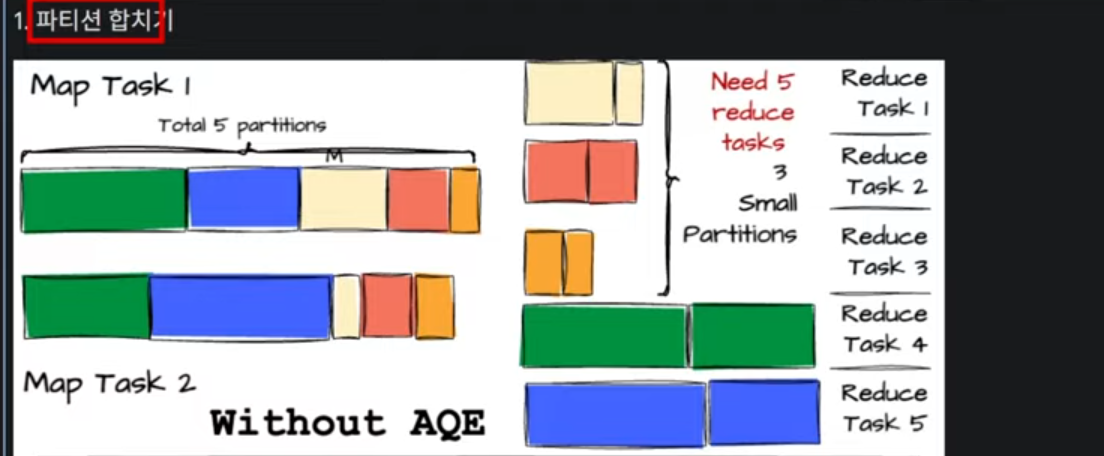
작업 대상이 되는 데이터를 파티션으로 쪼개게 됩니다. 특정컬럼에 있는 기반으로 보통은 파티션을 쪼갤수가 있는데,
컬럼에 들어있는 고유한 데이터의 종류에 따라서 파티션이 쪼개지다 보면 모두가 동일한 크기로 쪼개지진 않습니다.
하지만 자잘한 파티션들이 많이 생기게되면 스파크의 성능이 떨어지게 됩니다.
왜냐면 파티션 하나당 Task가 하나씩 할당이 되게 되는데, 자잘한 파티션들이 많아지면 Task가 많아져서 Spark작업에 부하가 걸릴수도 있기 때문입니다. 그래서 AQE는 자잘하게 나눠진 파티션들을 하나의 파티션으로 합쳐주는것입니다.
셔플 이후에 데이터가 급격히 작아진 파티션들을 자동으로 병합하여 태스크 개수를 줄여줍니다. (작은 파일 문제와 스케줄링 오버헤드 해결)
# 셔플 후 파티션 자동 병합 활성화
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
# 병합 후 최소 파티션 개수 지정
spark.conf.set("spark.sql.adaptive.coalescePartitions.minPartitionNum", "1")
- 상황: filter 연산 후 데이터가 90% 사라졌는데, 파티션은 여전히 200개일 때.
- 효과: 불필요한 I/O와 태스크 생성 비용을 아낍니다.

Switching Join Strategies(효율적인 join방식 채택)

실행 전에는 데이터 크기를 몰라 Sort Merge Join을 계획했더라도, 막상 데이터를 읽어보니 한쪽이 작다면 즉석에서 Broadcast Hash Join으로 변경합니다. 이게 무슨말이냐면 Sort Merge Join 셔플과 정렬이 일어나기 때문에 비용이 많이 드는 조인 방법이지만 그만큼 안전한 방법입니다 브로드 케스트 조인은 엄청큰데이터와 작은데이터간의 조인입니다.
AQE를 활성화를 시키면 Join되려는 두테이블의 사이즈를 보고 Apache Spark가 판단해서 둘중하나로 변경해 효율적으로 바꿔주는 방법입니다


# 조인 전략 동적 변경 활성화
spark.conf.set("spark.sql.adaptive.localShuffleReader.enabled", "true")
# 실행 계획 확인 시 'AQE' 문구가 포함된 것을 볼 수 있음
df_joined.explain()
- 상황: 복잡한 필터링 결과 테이블이 10MB 이하로 줄어든 경우.
- 효과: 무거운 셔플 과정을 통째로 생략합니다.
Skew Join Optimization(편향데이터 분산)
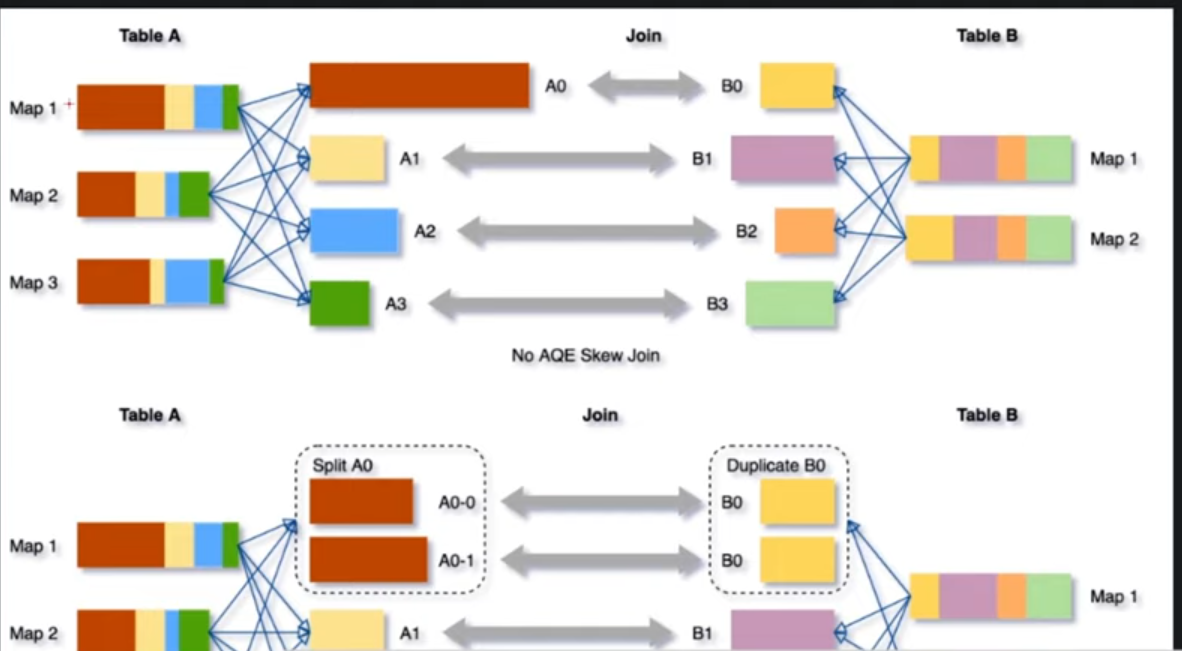
1번의 key에 90%정도 몰려있다고 쳐보겠습니다 (A0 그림) 나머지는 이제 자잘하게 되어있는데, 1번파티션 하나만 너무 크게 되어있을때입니다. 그렇게 되면 파티션에 Task가 하나씩 할당이 되게 되는데 그렇게되면 혼자 과도한 작업을 처리하게 되기 때문에
그걸 나눠서 작업하는 과정입니다. 최초에는 하나의 파티션으로 존재를했지만 Spark 자체적으로 최적화를 시키면서 봤을때
너무 과도하게 큰 용량의 데이터다라고 판단이 들어서 쪼개어가지고 병렬로 작업이 될수 있도록 만들어주는것입니다.


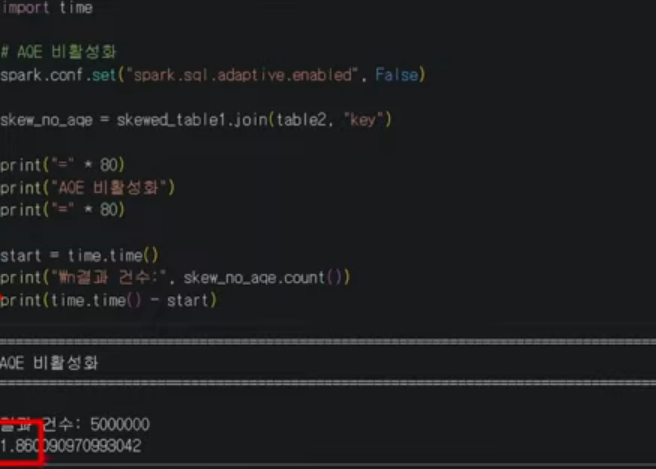
AQE 활성화와 비활성화의 차이
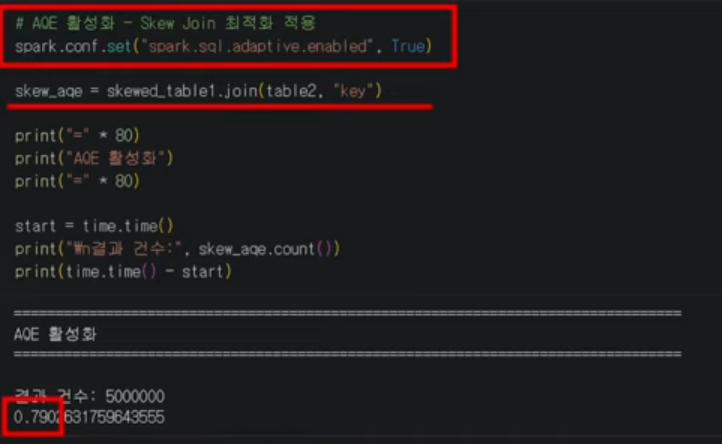
4단계에서 다뤘던 데이터 불균형(Skew)을 런타임에 감지하고, 비정상적으로 큰 파티션을 자동으로 쪼개어 병렬 처리합니다.
# Skew Join 자동 최적화 활성화
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true")
# 어느 정도를 Skew로 볼 것인가? (평균의 n배 이상일 때)
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "5")
- 상황: 특정 키에 데이터가 몰려 특정 태스크만 종료되지 않을 때.
- 효과: Salting 코드를 직접 짜지 않아도 엔진이 알아서 병목을 제거합니다.
전체 구조 요약 및 체크리스트
Spark Performance Tuning 5단계를 하나의 체크리스트로 묶으면 다음과 같습니다.
| 단계 | 핵심 키워드 | 주요 액션 |
| 1. Compute | Shuffle & Join | Broadcast 활용, 셔플 최소화 |
| 2. Data | I/O & Format | Parquet, Partition Pruning, 파일 크기 최적화 |
| 3. Execution | Memory | cache() 적재적소 사용, Spill 방지 |
| 4. Skew | Bottleneck | Salting 기법, AQE Skew Join 활용 |
| 5. Runtime | AQE | adaptive.enabled=true 및 동적 파티션 병합 |
Spark UI 읽는 법
성능 튜닝의 완성은 Spark UI입니다.
- SQL Tab: AQE가 실제로 실행 계획을 어떻게 변경했는지(Adaptive Plan) 확인하세요.
- Executors Tab: 각 Executor의 메모리 사용량과 GC 타임을 확인하세요.
정리
Spark 애플리케이션의 성능은 단순히 메모리를 늘리는 것으로 해결되지 않습니다. 연산 구조, 데이터 입출력, 메모리 관리, 데이터 불균형, 그리고 런타임 자동 최적화라는 5가지 레이어를 체계적으로 관리해야 합니다.
1. Compute Layer (연산 구조 최적화)
성능 최적화의 첫걸음은 셔플(Shuffle) 최소화입니다.
- Join 전략: 데이터 크기에 따라 Broadcast Hash Join을 유도하거나, 대용량 간의 조인에서는 Sort Merge Join이 원활하게 돌아가도록 설계합니다.
- 파티션 제어: Repartition과 Coalesce를 적재적소에 사용하여 병렬성을 확보하고 셔플 오버헤드를 줄입니다.
- 구조 이해: DAG와 Stage를 분석하여 Narrow vs Wide Transformation을 구분하고 연산 병목 지점을 파악합니다.
2. Data Layer (I/O 최적화)
데이터를 읽고 쓰는 시점의 효율이 전체 속도의 70%를 결정합니다.
- 저장 포맷: 열 지향 저장소인 Parquet를 사용하여 Column Pruning을 활성화합니다.
- 필터링 최적화: Predicate Pushdown과 Partition Pruning을 통해 필요한 데이터만 골라 읽어 메모리 낭비를 방지합니다.
- 파일 관리: Small File 문제를 해결하여 네임노드 부하를 줄이고 스캔 속도를 극대화합니다.
3. Execution Layer (메모리 및 실행 효율)
적재된 데이터를 어떻게 효율적으로 재사용하고 관리하느냐가 핵심입니다.
- 캐시 전략: cache()와 persist()의 차이를 이해하고, 반복 사용되는 데이터의 StorageLevel을 최적화합니다.
- 메모리 분배: Execution vs Storage Memory 비율을 조정하여 연산 중 발생하는 Disk Spill을 원천 차단합니다.
- Off-heap: JVM 밖의 메모리를 활용해 GC(Garbage Collection) 부하를 줄입니다.
4. Skew Handling (병목 제거)
가장 늦게 끝나는 태스크가 전체 종료 시간을 결정한다는 원칙에 따라 데이터 불균형을 잡습니다.
- 데이터 분산: Salting 기법을 통해 특정 키에 몰린 데이터를 강제로 분산시킵니다.
- 탐지 및 격리: Spark UI를 통해 Skew를 감지하고, Heavy Key(NULL 등)를 분리하여 별도로 처리합니다.
- AQE 활용: 엔진 레벨에서 지원하는 자동 Skew 최적화 옵션을 활성화합니다.
5. Runtime Optimization (AQE 자동 최적화)
Spark 3.x의 정수인 Adaptive Query Execution(AQE)을 통해 실행 중에 스스로 최적화합니다.
- 동적 병합: 셔플 후 작아진 파티션들을 자동으로 합쳐(Coalescing) 태스크 낭비를 막습니다.
- 전략 변경: 런타임 통계에 따라 조인 방식을 동적으로 변경하여 최적의 경로를 찾습니다.
- 지능적 대응: 실행 중 발생하는 다양한 변수에 유연하게 대응하여 수동 튜닝의 한계를 극복합니다.
Spark 튜닝은 I/O를 줄이고(Data), 셔플을 방지하며(Compute), 메모리 부족을 해결하고(Execution), 불균형을 해소하여(Skew), 자동화 도구(AQE)를 적극 활용합니다.
'Spark' 카테고리의 다른 글
| [Spark] - Spark (0) | 2026.03.27 |
|---|---|
| [Spark] - 파티션 최적화 (0) | 2026.03.25 |
| [Spark] - Json 데이터 다루기(with_Explode) (0) | 2026.03.24 |
| [Spark] - Null값 처리 (0) | 2026.03.24 |
| [Spark] - 정규식을 통한 문자열 처리 (0) | 2026.03.23 |