Spark를 배우면서 정리를 위한 블로그를 작성해봤습니다. 제가 Spark를 배우면서 생각나는것들과 이해를 하기위해서 궁금했던것들을 종합적으로 찾아보고 정리하는 글입니다. 2편에서는 Spark Performance Tuning 관련된 긴 글을 작성해보려 합니다.하나하나의 피상적 정리를 벗어나 이론보다는 전체적인 그림과 연결점을 찾는 과정이라 생각해주시면 감사하겠습니다 :)
Spark란
Apache Spark는 대용량 데이터를 빠르게 처리하기 위한 분산처리 프레임워크
Spark의 핵심개념
- 분산처리 : 여러서버에서 동시에 처리하는방식
- 인메모리: 데이터를 디스크가 아니라 RAM에 올려서 처리
- RDD: 여러 노드(서버)에 분산된, 변경 불가능한 데이터 집합
분산처리의 장점
- 수평적 확장성(Scale-out) : 단일 머신은 CPU나 RAM 확장에 물리적 한계가 있지만, 분산 환경에서는 노드(서버)를 추가함으로써 메모리와 CPU 자원을 거의 무한하게 확장할 수 있습니다
- 병렬 처리를 통한 속도 향상 : 데이터를 파티션(Partition) 단위로 나누어 여러 노드에서 동시에 태스크(Task)를 실행합니다. 이로 인해 처리 속도가 선형적으로 증가하며 대규모 작업을 빠르게 완료할 수 있습니다.
- 고가용성 및 복구: 데이터가 여러 파티션으로 분산되어 관리되므로, 특정 노드에 장애가 발생하더라도 계보(Lineage)를 통해 유실된 파티션만 재계산하여 복구할 수 있는 안정성을 갖춥니다
인메모리(In-memory) 방식의 장점
- 획기적인 처리 속도: 데이터를 처리할 때마다 디스크 I/O가 발생하는 Hadoop MapReduce와 같은 디스크 기반 방식에 비해 매우 빠른 속도를 자랑합니다.
- 반복 연산 및 반복 알고리즘에 최적: 동일한 데이터를 여러 번 참조해야 하는 머신러닝(ML)이나 반복적인 데이터 가공 작업에서 효율이 극대화됩니다
- 데이터 캐싱(Caching): 반복적으로 사용하는 RDD나 DataFrame을 메모리에 캐싱(Cache/Persist)하여 저장해두면, 이후 작업에서 재계산 없이 즉시 데이터를 불러와 성능 병목을 방지할 수 있습니다
- 자원 최적화: 지연 평가(Lazy Evaluation) 방식을 채택하여 실제 연산이 필요한 시점(Action)까지 실행을 미루고 전체 실행 계획을 최적화함으로써, 불필요한 연산을 줄이고 메모리를 더 효율적으로 사용합니다.
Spark의 핵심 컴포넌트
| 컴포넌트 | 설명 |
| Spark Core | RDD 기반 기본 엔진 |
| Spark SQL | DataFrame, SQL 쿼리 |
| Spark Streaming | 실시간 데이터 처리 |
| MLlib | 머신러닝 라이브러리 |
| GraphX | 그래프 처리 |
Spark를 사용하는 이유는?
- 데이터를 한 서버 메모리
- CPU 병렬 처리 한계
- 분산 환경에서 처리 + 최적화
| 단일머신 | Spark | |
| 메모리 | 제한적 | 노드 합산 |
| CPU | 코어 수 제한 | 병렬 확장 |
| 처리 속도 | 선형 증가 | 병렬 증가 |
| 확장성 | 제한적 | 거의 무한 |
| 확장 방식 | Scale-up(CPU/RAM 증가) | 노드 x 코어 |
Spark vs 주요 데이터 처리 도구 비교
Spark vs Hadoop MapReduce
| 항목 | Spark | MapReduce |
| 처리 방식 | 메모리 기반 | 디스크 기반 |
| 속도 | 매우 빠름 | 느림 |
| 구조 | DAG | Map → Reduce |
| 반복 연산 | 강함 | 매우 비효율 |
| 사용성 | 높음 (SQL, DataFrame) | 낮음 |
- Mapreduce = 레거시
Map → (디스크 저장) → Reduce → (디스크 저장)- Spark = 대용량 ETL / 배치처리
Transformation → 메모리 → 계속 이어서 처리
Spark vs Apache Flink
| 항목 | Spark | Flink |
| 처리 방식 | Micro-batch | True streaming |
| 지연(latency) | 초~수초 | ms 수준 |
| 상태 관리 | 제한적 | 매우 강력 |
| 사용 난이도 | 비교적 쉬움 | 어려움 |
- Flink = 실시간 - 초저지연 실시간
- Spark = 대부분의 배치 + 준실시간 - 배치중심
Flink를 쓰는 경우
- 실시간 이벤트 처리
- 금융 / 로그 분석
- 사용자 행동 tracking
Spark → 데이터 가공 (ETL)
↓
저장 (Data Lake)
↓
Flink → 실시간 처리Spark vs Presto / Trino
| 항목 | Spark | Presto/Trino |
| 목적 | 데이터 처리 (ETL) | 쿼리 엔진 |
| 데이터 저장 | 결과 저장 가능 | 저장 안 함 |
| 처리 방식 | batch 처리 | interactive query |
| 속도 | 무거운 작업에 강함 | 빠른 조회에 강함 |
- Spark → 데이터를 만든다 - 데이터 가공
- Presto → 데이터를 조회한다 - 데이터 조회
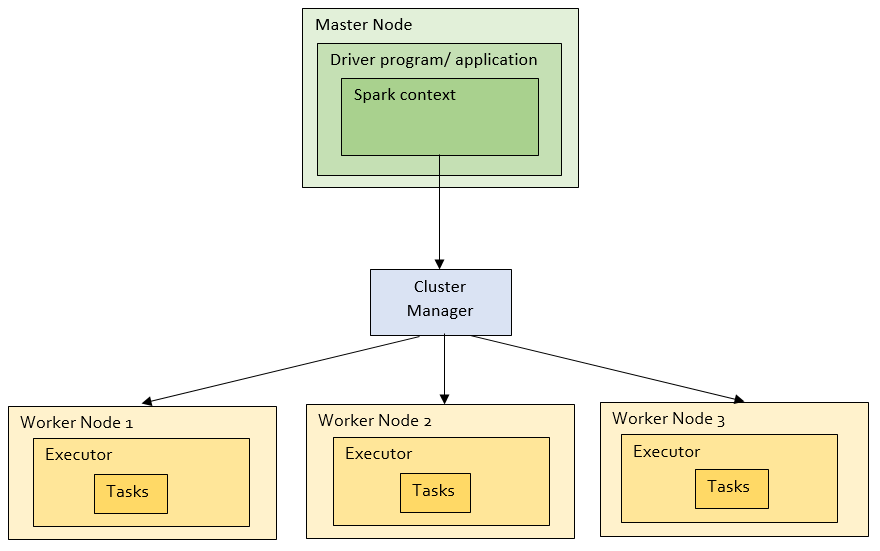
Spark 실행 구조
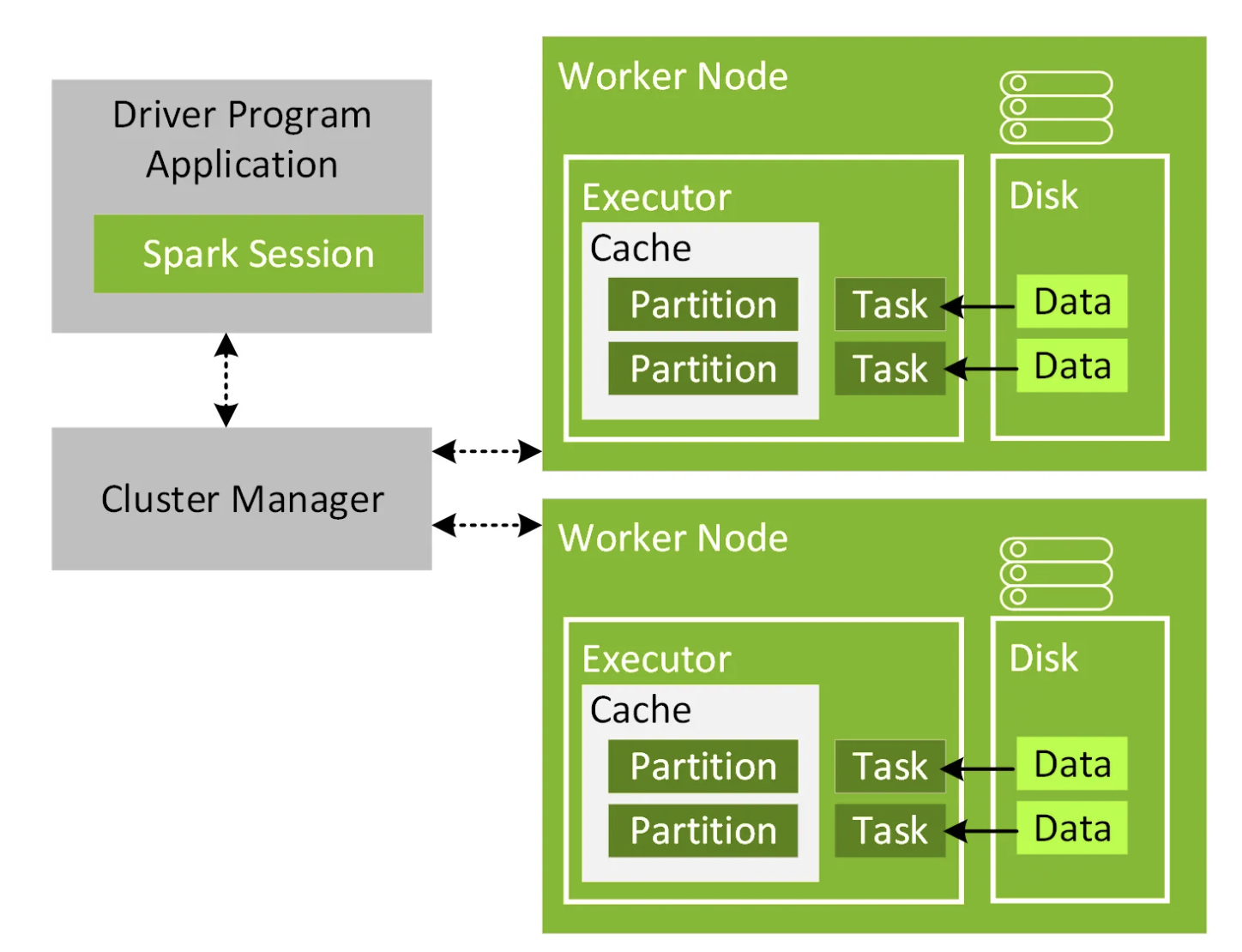
흐름방식
Driver Application → Cluster Manager → Worker Node → Executor → Task → Data
1. Driver에서 코드 실행
2. Action 발생 → Job 생성
3. DAG 생성
4. Stage 나눔
5. Task 생성
6. Cluster Manager에 요청
7. Executor 생성
8. Task를 Executor에 전달
9. Executor가 Partition 단위로 처리
10. 결과 반환
1. Driver Apllication (앱단위)
- 하나의 Driver 프로세스 포함
- 여러 Job을 포함할 수 있음
- Spark의 두뇌 (컨트롤 타워)
- SparkSession 생성
- Job 생성
- DAG 생성
- Task 분배
Driver의 역할(지휘관)
Job을 생성하고, 실행 계획을 만들고, Executor에게 일을 시키는 주체
Spark 작업을 계획하고 실행을 지휘하는 중앙 컨트롤러
- 스파크 세션(Spark Session): 스파크 기능에 접속하기 위한 통합 진입점입니다.
- 작업 스케줄링: 코드를 분석하여 실행 계획(DAG)을 세우고, 이를 작은 단위인 '태스크(Task)'로 쪼개어 워커 노드에 할당합니다.
- main() 함수 실행: 사용자 프로그램의 진입점
- SparkContext/SparkSession 생성: Spark 클러스터와 연결
- 작업 계획 수립: DAG(Directed Acyclic Graph) 생성
- Task 스케줄링: 작업을 Executor에 분배
- Spark UI 제공
2. Job (작업 단위)
Action 실행 시 생성되는 전체 Spark 작업 단위
사용자가 실행 요청한 작업을 실제로 실행 단위로 쪼개서 처리하는 시작점입니다
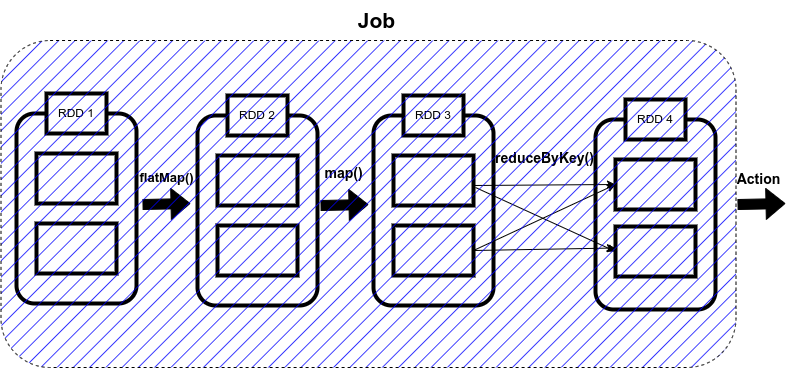
Spark는 collect(), count() 같은 액션 연산이 트리거되면, Spark 애플리케이션을 실행하는 책임자이자 모든 Spark 애플리케이션의 진입점으로 간주되는 드라이버 프로그램이 이 Spark 애플리케이션을 아래 그림에서 볼 수 있는 단일 작업으로 변환하는 것입니다.
flatMap(), map(): 데이터를 조각내거나 형태를 바꾸는 과정입니다. 화살표가 1:1로 깔끔하게 이어지는데, 이를 Narrow Dependency(좁은 의존성)라고 합니다.
스테이지 0 (셔플 전): 각자 자기 앞에 놓인 데이터만 처리하면 되는 단계입니다. (예: , ) 남의 도움이 필요 없으니 여러 컴퓨터가 동시에 병렬로 아주 빠르게 처리합니다.map,filter
셔플(Shuffle)의 등장: reduceByKey()
그림의 RDD 3에서 RDD 4로 넘어가는 구간은 화살표로 엉쳐있는걸 볼수있습니다.
- reduceByKey(): 같은 키(Key)를 가진 데이터끼리 합쳐야 할 때 발생합니다.
- 이때 데이터가 여러 워커 노드 사이를 이동하며 재배치되는데, 이것을 셔플(Shuffle)이라고 합니다.
- Spark 성능에서 가장 비용이 많이 들고 복잡한 구간입니다. (여러 요리사가 각자 썬 재료를 한곳에 모아 섞는 복잡한 과정이라 보시면 됩니다.)
여러 Job이 동시에 실행될 수 있음
- 특히 클러스터 환경에서 Spark는 병렬 Job 실행 가능
Job의 역할
실행 트리거 역할 (Action 기준) : Job = “실행을 시작시키는 단위”
DAG를 기반으로 실행 계획 생성 :Spark 내부에서는 Transformation들을 쭉 쌓아두고 있다가 Action이 나오면 DAG (Directed Acyclic Graph) 를 만든다
map → filter → join → groupBy
이걸 하나의 Job으로 묶어서 실행 계획 생성
Stage로 분리하는 기준 제공: Job이 만들어지면 Spark는 이 Job을 Stage 단위로 쪼갬 Shuffle 기준으로 Stage 나눔 Narrow / Wide dependency 기준
Job이 중요한 이유
- Job 수 많으면 성능 저하
- 불필요한 Action 줄여야 함
- Job 단위로 로그/모니터링
- Spark UI에서 Job 기준으로 분석
- 최적화 포인트 시작점
- 병목 찾을 때 Job → Stage → Task 순으로 분석
Job의 범위
DAG → Stage → Task3. DAG(Directed Acyclic Graph)
DAG는 연산의 흐름을 순서대로 표현한 구조 입니다. = 작업 순서도
DAG의 역할
- 실행 계획 생성 : 어떤 순서로 실행할지 결정
- 최적화 : 불필요한 연산 제거, 연산 합치기
- Stage 나누기 기준 제공
DAG 내부구조
Logical Plan & Physical Plan
Logical Plan = “무엇을 할지 (What)”
Physical Plan = “어떻게 할지 (How)”
Logical Plan : 연산의 의미(로직)를 표현한 추상 계획 (데이터를 어떻게 가져오고, 어떻게 변환할지에 대한 선언)
Physical Plan : 실제로 실행 가능한 구체적인 계획 (실제로 어떤 알고리즘과 리소스를 써서 실행할지 결정된 상태)
| 항목 | Logical Plan | Physical Plan |
| 수준 | 추상적 | 구체적 |
| 실행 가능 | ❌ | ✔ |
| 최적화 대상 | ✔ | 일부 |
| 포함 정보 | 연산 흐름 | 실행 방식 + 알고리즘 |
| 관점 | What | How |
4. Stage (실행 단계)
스테이지(Stage)를 나누는 기준
Shuffle(= Wide Dependency)”가 발생하는 지점에서 나뉜다.
groupBy → join → reduceByKey
- 스테이지 0 (셔플 전): 각자 자기 앞에 놓인 데이터만 처리하면 되는 단계입니다. (예: , ) 남의 도움이 필요 없으니 여러 컴퓨터가 동시에 병렬로 아주 빠르게 처리합니다.mapfilter
- 셔플(Shuffle): "같은 키를 가진 놈들 다 모여!" 라는 명령이 떨어지면 상황이 바뀝니다. 1번 컴퓨터에 있는 '사과' 데이터와 2번 컴퓨터에 있는 '사과' 데이터가 한곳으로 모여야 합계를 낼 수 있기 때문입니다.reduceByKey
- 스테이지 1 (셔플 후): 데이터가 다 모인 후에야 비로소 다음 계산을 시작할 수 있습니다.
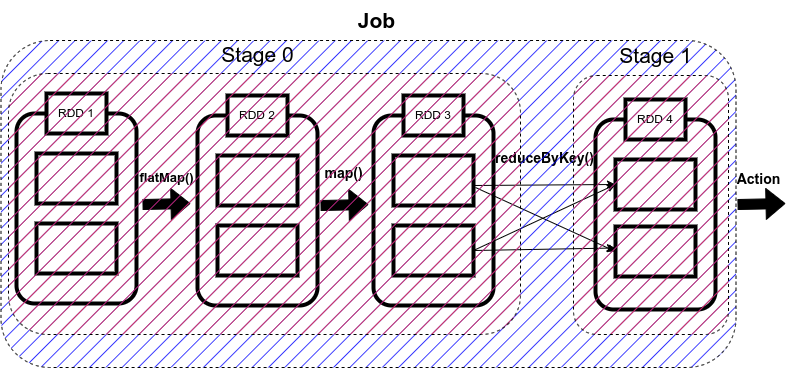
Spark에는 두 가지 유형의 Stage
1. Shuffle Map Stage
이름에서 알 수 있듯이, 이는 셔플 동작을 위한 데이터를 생성하는 스파크 내 한 단계입니다.
이 단계의 출력은 이후 단계들의 입력 역할을 합니다.
위 코드에서 Stage 0은 셔플 동작을 위한 데이터를 생성하여 Stage 1의 입력 역할을 하므로 ShuffleMapStage 역할을 합니다.

2. Spark에서의 결과 Stage
작업의 마지막 단계는 RDD에서 함수를 실행하여 행동 연산을 실행합니다(예시에서는 행동 연산이 collect입니다).
활성 연산 결과를 계산합니다.
예시에서 1단계는 RDD에 수행된 액션 결과를 제공하기 때문에 ResultStage 역할을 합니다. 우리 코드에서는 데이터 셔플 후에 reduceByKey() 함수를 사용해 유사한 키들이 그룹화되었고, 이 단계에서 collect(action operation) 함수를 사용해 코드의 최종 결과를 얻습니다.

왜 Stage를 나누냐
- Shuffle 발생하면
- 데이터를 네트워크로 재분배해야 함
👉 이 과정은 경계(boundary)가 필요함
👉 그래서 Stage 나눔
5. Task (실제 실행 단위)
하나의 Partition을 처리하는 최소 실행 단위
Spark에서 실제로 실행되는 가장 작은 작업 단위
- Partition 하나당 Task 하나
6.Cluster Manager
클러스터의 CPU/메모리를 관리하고 Executor를 띄워주는 관리자입니다.
Spark는 여러 클러스터 매니저와 함께 동작할 수 있다.
드라이버와 워커 노드 사이에서 자원을 관리합니다. (예: YARN, Kubernetes, Mesos 등)
드라이버가 필요한 자원(CPU, 메모리)을 요청하면, 클러스터 매니저가 유효한 워커 노드를 찾아 연결해 줍니다.
- 리소스 관리
- Executor 생성
- 작업 환경 제공
대표적인 Cluster Manager 종류
| 클러스터 매니저 | 설명 | 사용 시나리오 |
| local[*] | 로컬 JVM에서 실행 | 개발, 테스트 |
| Standalone | Spark 자체 클러스터 매니저 | 간단한 클러스터 |
| YARN | Hadoop의 리소스 매니저 | Hadoop 환경 |
| Mesos | Apache Mesos | 대규모 클러스터 |
| Kubernetes | K8s 기반 실행 | 클라우드 네이티브 |
Driver와 Cluster Manager 의 관계
“Executor 10개 주세요”
Cluster Manager가 판단: 가능한 노드 찾고, Executor 띄워줌
7.Executor
Worker 노드에서 실제 데이터를 처리하는 프로세스
Spark에서 Task를 실행하고 데이터를 처리하는 실제 작업 주체
- Worker 노드에서 실행되는 프로세스
- Task 실행 - Driver가 내려준 Task 수행 (map,filter,join,aggregation)
- 데이터 처리 - Partition 단위로 처리 (task1개 = partition 1개)
- 메모리 관리 - 내부에서 메모리 나눠서 사용 (cache / persist, shuffle buffer , sort)
Executor 내부구조
Executor
├── CPU (Core)
├── Memory
│ ├── Execution Memory (연산용)
│ └── Storage Memory (cache용)
├── Task 실행
├── Shuffle 처리
└── Spill (디스크 사용)Executor 병렬 처리 구조
Executor (core 4개)
├── Task 1
├── Task 2
├── Task 3
├── Task 4
Core수 = 동시 실행 task 수
Executor 개수 vs Core 수
- Executor 많음 → 분산 ↑
- Core 많음 → 병렬 처리 ↑
Executor 와 Driver의 차이점
|
항목
|
Driver
|
Executor
|
|
주요 역할
|
중앙 제어 및 스케줄링 (지휘)
|
실제 연산 및 데이터 처리 (실행)
|
|
위치
|
사용자 프로그램의 진입점 (main 함수 실행)
|
클러스터의 워커 노드(Worker Node)
|
|
주요 작업
|
DAG 생성, 작업 계획 수립, 태스크 배분
|
태스크 실행, 데이터 캐싱, 결과 저장
|
|
결과 처리
|
익스큐터들로부터 처리 결과를 수집
|
처리된 결과를 드라이버로 전송
|
|
진입점
|
SparkContext / SparkSession 생성
|
드라이버가 전달한 태스크 수신 및 실행
|
Partition
Partition은 Spark에서 데이터를 나누는 최소 단위로, 각 Partition이 하나의 Task로 실행되어 병렬 처리를 가능하게 하며, Partition 수는 성능에 직접적인 영향을 줍니다.
데이터를 나눈 물리적/논리적 처리 단위
RDD의 데이터는 여러 파티션으로 나뉘어 분산 저장된다.
파티션 = 병렬 처리의 단위
- Partition 수 = Task 수 = 병렬 처리 수
왜 Partition이 중요하냐?
- 병렬 처리의 기준
- 성능을 좌우함
- suffle과 직결됨
Partition의 결정되는 기준
- 데이터를 읽을때(HDFS / S3 block 기준) , 파일크기 기반
- Shuffle시
- 수동 조정
repartition vs Coalesce
| 구분 | repartition | coalesce |
| Partition 증가 | 가능 | ❌ 불가능 |
| Partition 감소 | 가능 | 가능 |
| Shuffle | 항상 발생 | 거의 없음 |
| 성능 | 느릴 수 있음 | 빠름 |
HashPartitioner
Key의 해시값을 이용해 데이터를 파티션에 할당합니다.
- 무작위성: Key가 무엇이든 상관없이 해시 함수를 통해 파티션에 골고루 뿌려줍니다.
- 속도: 계산이 매우 빠릅니다.
partition = hash(key) % numPartitionsRange Partitioner
데이터의 값의 범위(Range)를 기준으로 파티션을 나눕니다.
정렬된 RDD의 데이터를 거의 같은 범위 간격으로 분할할수 있습니다.
- 정렬 유지: 각 파티션 내의 데이터뿐만 아니라, 파티션 간의 순서도 유지됩니다. (1번 파티션의 모든 값 < 2번 파티션의 모든 값)
- 샘플링 필요: 범위를 나누기 위해 데이터를 미리 한 번 훑어보는 과정(Sampling)이 추가로 필요하여 Hash보다 약간의 오버헤드가 있습니다.
HashPartitioner VS RangePartitioner
| 항목 | HashPartitioner | RangePartitioner |
| 핵심 목표 | 데이터를 균등하게 분산 | 데이터의 순서(정렬) 유지 |
| 결정 방식 | 해시 함수 결과값 | 키 값의 범위 (Boundaries) |
| 정렬 상태 | 정렬되지 않음 | 파티션 간/내 정렬됨 |
| 주요 연산 | groupByKey, reduceByKey | sortByKey |
| 추가 비용 | 거의 없음 | 범위 산정을 위한 데이터 샘플링 비용 |
Spark Partition의 종류
- Input Partition
- Output Partition
- Shuffle Partition
이 중, Spark의 주요 연산이 Shuffle인 만큼, Shuffle Partition이 가장 중요합니다.
Input Partition
관련 설정 : spark.sql.files.maxpartitionBytes
Input Partition은 처음 파일을 읽을 때 생성하는 Partition입니다. 관련 설정값은 spark.sql.files.maxPartitionBytes으로, Input Partition의 크기를 설정할 수 있고, 기본값은 134217728(128MB)입니다.
파일 (HDFS 상의 마지막 경로에 존재하는 파일)의 크기가 128MB보다 크다면, Spark에서 128MB만큼 쪼개면서 파일을 읽습니다. 파일의 크기가 128MB보다 작다면 그대로 읽어 들여, 파일 하나당 Partition 하나가 됩니다.
대부분의 경우, 필요한 칼럼만 골라서 뽑아 쓰기 때문에 파일이 128MB보다 작습니다. 가끔씩 큰 파일을 다룰 경우에는 이 설정값을 조절해야 합니다.

Use Case
- 파일 하나의 크기가 매우 크고 수도 많다면, 설정값 크기를 늘리고 자원도 늘려야 하지만, 제 경험상 이런 경우는 없었습니다.
- 또한, 필요한 칼럼(column)만 쓰기 때문에 데이터의 크기는 더 작아집니다.
Output Partition
관련 설정 : df.repartition(cnt), df.coalesce(cnt)
Output Partition은 파일을 저장할 때 생성하는 Partition입니다. 이 Partition의 수가 HDFS 상의 마지막 경로의 파일 수를 지정합니다.
기본적으로, HDFS는 큰 파일을 다루도록 설계되어 있어, 크기가 큰 파일로 저장하는 것이 좋습니다.
보통 HDFS Blocksize에 맞게 설정하면 되는데, 카카오 Hadoop 클러스터의 HDFS Blocksize는 268435456 (256MB)로 설정되어 있어서, 통상적으로 파일 하나의 크기를 256MB에 맞도록 Partition의 수를 설정하면 됩니다.
Partition의 수는 df.repartition(cnt), df.coalesce(cnt)를 통해 설정합니다. 이 repartition와 coalesce를 이용해 Partition 수를 줄일 수 있습니다.
아래의 예시는, 파일 수를 줄여서 50개로 저장하는 모습입니다.
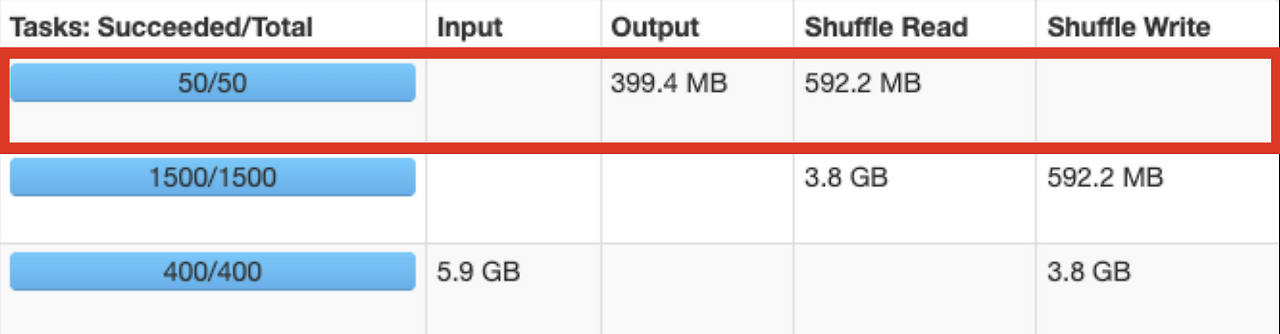
- Use Case
- 보통 groupBy 집계 후 저장할 때 데이터의 크기가 작아집니다. 그런 다음 spark.sql.shuffle.partitions 설정에 따라 파일 수가 지정되는데, 이때 파일의 크기를 늘리기 위해 repartition와 coalesce을 사용해 Partition 수를 줄일 수 있습니다.
- df.where()를 통해 필터링을 하고 나서 그대로 저장한다면 파편화가 생깁니다. 그래서 repartition(cnt)을 한 후 저장합니다.
Shuffle Partition
관련 설정 : spark.sql.shuffle.partitions
Spark 성능에 가장 크게 영향을 미치는 Partition으로, Join, groupBy 등의 연산을 수행할 때 Shuffle Partition이 쓰입니다.
설정값은 spark.sql.shuffle.partitions이고, 이 설정값에 따라 Join, groupBy 수행 시 Partition의 수(또는 Task의 수)가 결정됩니다.

이 설정값은 Core 수에 맞게 설정하라고 하지만, Partition의 크기에 맞추어서 설정해야 합니다.
이 Partition의 크기가 크고 연산에 쓰이는 메모리가 부족하다면 Shuffle Spill(데이터를 직렬화하고 스토리지에 저장, 처리 이후에는 역 직렬 화하고 연산 재개함)이 일어나기 때문입니다.
Shuffle Spill이 일어나면, Task가 지연되고 에러가 발생할 수 있습니다. 또한, Hadoop 클러스터의 사용률이 높다면, 연달아 에러가 발생하고 Spark가 강제 종료될 수 있습니다.
Memory Limit Over와 같이, Shuffle Spill도 메모리 부족으로 나타나는데, 보통 이에 대한 대응을 Core 당 메모리를 늘리는 것으로 해결합니다. 하지만, 모든 사람이 메모리가 부족하다고 메모리 할당량을 늘린다면, 클러스터가 사용성이 더 떨어지고 작업이 더욱더 실패하게 될 것입니다. 그래서 제 개인적인 생각이기도 하지만, Partition의 크기를 결정하는 옵션인 spark.sql.shuffle.partitions를 우선적으로 고려해 설정해야 한다고 생각합니다.
또한, 일반적으로, 하나의 Shuffle Partition 크기가 100~200MB 정도 나올 수 있도록 spark.sql.shuffle.partitions 수를 조절하는 것이 최적입니다.
Use Case
- Memory Limit Over, Memory Spill 등 자원 문제가 생길 경우, Shuffle Partition 크기를 우선적으로 고려해야 합니다.
최적화 실험
Shuffle Partition 크기가 100~200MB 정도 나올 수 있도록 설정하는 것이 얼마나 중요한지 다음의 최적화 실험을 통해 살펴보겠습니다.
Task & Partition
파티션: 거대한 데이터를 여러 개로 쪼갠 조각입니다. 그림에서 박스가 여러 개인 이유는 데이터를 나누어 처리하기 때문입니다.Partition
태스크: 각 파티션에 대해 수행할 실제 작업(예: 필터링, 합계 구하기)입니다. 그림에서 보듯 태스크는 **디스크(Disk)**나 캐시에 있는 데이터 조각을 가져와 작업을 수행합니다.
SparkContext
클러스터와 연결하고 Spark 작업을 시작하는 진입점(Entry Point)
Spark를 실행하기 위한 시작점이자 클러스터와의 연결 객체
SparkContext 역할
- 클러스터 연결 Driver ↔ Worker 연결
- Job 실행 시작
- RDD 생성
- 리소스 관리
User Code
↓
SparkContext ← 여기
↓
Cluster Manager (YARN / Kubernetes / Standalone)
↓
ExecutorsSparkSession
Spark 애플리케이션의 통합 진입점(Entry Point)
DataFrame, SQL, Streaming 등 모든 기능을 하나로 묶은 인터페이스
SparkSession 역할
1.Python <-> JVM 간의 Gateway역할(통역사) - 연결통로
2. 내부적으로 분산 처리 구조를 구현하는 역할(Local Mode)
3. 자원 및 실행 관리 (Lazy Evalution)
- DataFrame 생성
- SQL 실행
- 데이터 소스 연결 (Parquet,ORC,JSON,JDBC)
- Streaming 지원
SparkSession 정의 코드
from pyspark.sql import SparkSession
# SparkSession은 PySpark 앱의 시작점(Entry Point)
# DataFrame API, SQL, 환경 설정 등을 모두 SparkSession을 통해 수행한다.
spark = (
SparkSession
.builder # SparkSession 빌더 시작
.appName("MySparkApp") # Spark UI에서 보일 앱 이름 설정
# .master("local[*]") # (선택) 로컬 실행 시 CPU 모든 코어 사용
# .config("key", "value")# (선택) 추가적인 Spark 설정
# .enableHiveSupport() # (선택) Hive 기능 필요할 때 활성화
.getOrCreate() # 기존 세션이 있으면 가져오고 없으면 새로 생성
)
# Spark 버전, 환경 확인용
print("Spark Version:", spark.version)
# 예시: 간단하게 DataFrame 생성해보기
data = [("Alice", 29), ("Bob", 35)]
df = spark.createDataFrame(data, ["name", "age"])
df.show()
# 작업이 끝나면 세션 종료
spark.stop()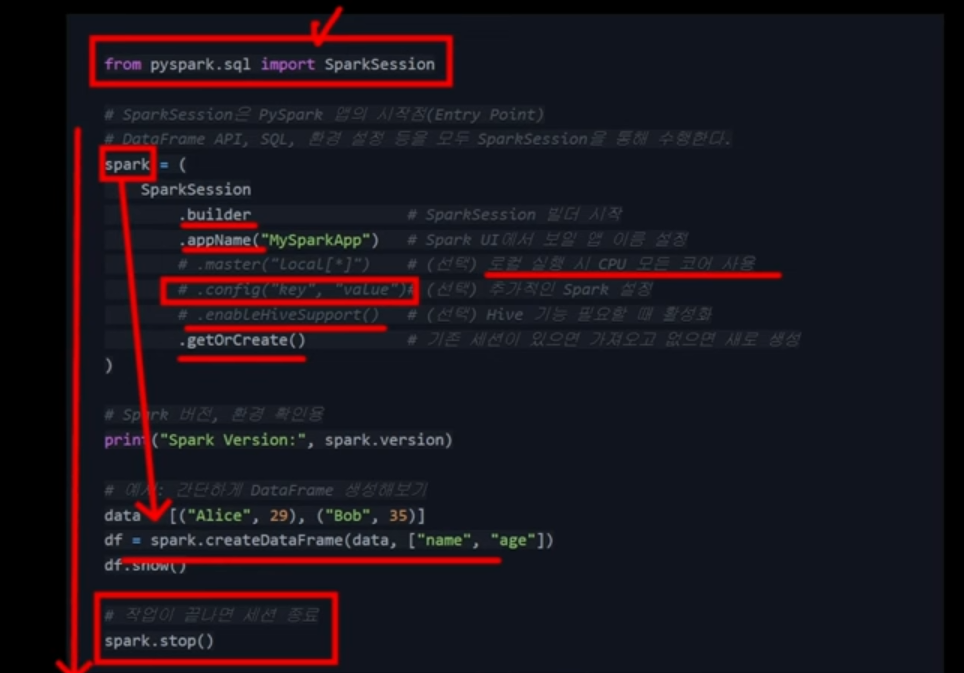
Pandas vs Spark
| 특징 | Pandas | PySpark |
| 정체 | Python 라이브러리 | JVM 엔진을 제어하는 Python 인터페이스 |
| 실행 위치 | Python 프로세스 내부 | 별도의 Java 프로세스(JVM) |
| 메모리 사용 | OS가 허용하는 범위 | Session 설정에 따라 관리됨 |
| 시작 방식 | import만 하면 실행 | SparkSession.builder.getOrCreate() 필요 |
SparkContext VS Spark Session
SparkContext = 저수준 실행 엔진 진입점 (RDD 중심)
SparkSession = 통합된 고수준 API (DataFrame/SQL 중심)
SparkContext (과거/저수준)
- RDD 생성
- 클러스터 연결
- 기본 실행 관리
sc.parallelize([1,2,3])
SparkSession (현재/표준)
- DataFrame / SQL
- Catalog / UDF / Streaming 포함
- 내부적으로 SparkContext 포함
spark.read.parquet("file")| 항목 | SparkContext | SparkSession |
| 도입 | Spark.1.x | Spark 2.0+ |
| 수준 | Low-level | High-level |
| 역할 | RDD 생성,저수준API | 통합 진입점 (RDD+DataFrame+SQL) |
| 사용성 | 어렵다 | 쉽다 |
| 기능 통합 | 없음 | 있음 |
| 현재 사용 | 거의 안 씀 | 표준 |
"SparkContext는 RDD 기반의 저수준 실행 인터페이스이고, SparkSession은 이를 포함하여 DataFrame과 SQL 기능을 통합한 고수준 API로 현재 표준이다"
분산 처리 구조의 가상 구현 (Local Mode)
Spark는 기본적으로 여러 대의 컴퓨터를 지휘하는 분산 처리 엔진입니다.
Colab처럼 단일 서버에서 실행하더라도 Spark는 내부적으로 다음 구조를 유지합니다.
클러스터 내부에서 실행되는 방식 (Cluster Mode)
Cluster Mode = Driver가 클러스터 내부에서 실행되는 방식
[사용자 PC]
↓ (submit)
[Cluster Manager]
↓
[Driver (Cluster 내부)]
↓
[Executor들]Local Mode vs Cluster Mode
Local Mode vs Cluster Mode = “혼자 실행 vs 분산 실행 + Driver 위치 차이”
| 구분 | Local Mode | Cluster Mode |
| 실행 환경 | 단일 머신 | 여러 머신 |
| Driver 위치 | 로컬 | 클러스터 |
| Executor | 없음(같이 실행) | 여러 노드 |
| 분산 처리 | ❌ | ✅ |
| 용도 | 개발/테스트 | 운영/대규모 |
Worker Node (실제 서버)
실제로 계산이 수행되는 물리적 또는 가상 서버입니다. 하나의 클러스터에는 수많은 워커 노드가 존재할 수 있습니다.
RDD
RDD (Resilient Distributed Dataset)는 Spark의 가장 기본적인 데이터 추상화
여러 서버에 나눠 저장되고, 변경 불가능하며, 장애 발생 시 복구 가능한 데이터
RDD를 제대로 이해하는 4가지 축
- Distributed (분산 데이터)
- 데이터가 여러 Partition으로 나뉨
- 여러 Executor에서 병렬 처리
- RDD = Partition들의 집합
- Immutable (불변성)
- 기존 RDD 변경 ❌
- 새로운 RDD 생성 ✔
- Lazy Evaluation (지연 실행)
- Transformation은 즉시 실행되지 않는다.
- Action이 호출될 때 비로소 실제 연산이 수행된다.
왜 지연평가인가?
- 실행 계획 최적화 가능
- 불필요한 연산 제거
- 메모리 효율적 사용
- Lineage (복구 메커니즘)
- RDD는 데이터 자체를 복제하지 않음 대신 어떻게 만들어졌는지 기록
rdd.map().filter()
-- 실행 안됨
rdd.collect()
-- 여기서 실행됨┌─────────────────────────────────────────────────────────────────┐
│ RDD │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │Partition │ │Partition │ │Partition │ │Partition │ │
│ │ 1 │ │ 2 │ │ 3 │ │ 4 │ │
│ │ [A,B,C] │ │ [D,E,F] │ │ [G,H,I] │ │ [J,K,L] │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ ↓ ↓ ↓ ↓ │
│ Executor 1 Executor 2 Executor 1 Executor 2 │
└─────────────────────────────────────────────────────────────────┘DataFrame
스키마가 있는 RDD 관계형 데이터베이스 테이블처럼 각 컬럼(column)별로 이름과 타입을 가진다.
컬럼(스키마)을 가진 분산 데이터 테이블 (SQL처럼 다룸)
👉 RDD = 원시 데이터 덩어리
👉 DataFrame = 엑셀/테이블 형태 데이터
| name | age | city |
|------|-----|------|
| Kim | 30 | Seoul |
| Lee | 25 | Busan |
DataFrame 의 장점
- Schema : 컬럼 + 데이터 타입 존재
- 최적화 엔진 : 쿼리 자동 최적화, 실행 계획 자동 개선(Catalyst Optimizer)
- Tungsten 엔진 : 메모리효율 증가, CPU 최적화 증가 , Serialization 최소화
- Lazy Evaluation : Action 전까지 실행 안 함
DataFrame은 Logical Plan → Catalyst 최적화 → Physical Plan → Tungsten 실행 과정을 거쳐 분산 처리된다”
Dataset
DataFrame + 타입 안정성(Java/Scala)을 결합한 구조
“RDD의 안전성 + DataFrame의 편의성”을 합친 것
- 컴파일 시 타입 체크
- DataFrame보다 안전
Dataset의 내부구조
- 분산 데이터 (Partition 기반)
- Schema (컬럼 구조)
- Encoder (객체 ↔ 바이너리 변환)
Dataset과 DataFrame의 차이
DataFrame = 엑셀 SQL테이블 느낌이고 컬럼이름으로 기반접근
DataSet = 객체(클래스)기반 코드에서 타입으로 접근
타입안정성이란 DataFrmae은 런타임오류 , DataSet은 컴파일 단계에서 오류가 납니다.
| 항목 | DataFrame | Dataset |
| 타입 안정성 | ❌ 없음 | ✅ 있음 |
| 구조 | 있음 | 있음 |
| 최적화 | 있음 | 있음 |
| 사용성 | 쉬움 | 중간 |
| 언어 지원 | Python 가능 | Python 불가 |
Encoder란?
Encoder는 Dataset에서 객체와 Spark의 내부 바이너리 포맷 간 변환을 담당하여 성능과 타입 안정성을 동시에 지원하는 핵심 컴포넌트입니다
JVM 객체 ↔ Spark 내부 포맷 변환 역할
case class User(name: String, age: Int)
val ds = spark.createDataset(Seq(User("kim", 28)))- User 객체 → Encoder → Spark 내부 데이터
Serialization란?
객체(Object)를 네트워크 전송이나 저장을 위해 바이트 형태로 변환하는 과정
Driver → Worker Node (데이터/코드 전달)✔ 객체 → 바이트 변환 (Serialization)
✔ 바이트 → 객체 복원 (Deserialization)
Encoder vs Serialization 차이
| 구분 | Serialization | Encoder |
| 대상 | RDD | Dataset |
| 목적 | 객체 전송 | 내부 최적화 |
| 구조 | 전체 객체 | 컬럼 기반 |
| 성능 | 상대적으로 느림 | 빠름 |
Lazy Evaluation
Lazy Evaluation은 연산을 즉시 실행하지 않고 Action 시점까지 미루어, 전체 실행 계획을 최적화한 뒤 수행하는 방식이다.
이 실행계획을 저장하고 관리하는 공간이 SparkSession이다.
왜 Lazy Evaluation을 쓰냐
실행 전에 전체 계획을 본다
filter → select → groupBy
- filter 먼저 실행
- 불필요한 컬럼 제거
- 연산 순서 변경
Catalyst
DataFrame / SQL 쿼리를 실행 계획으로 변환하는 쿼리 처리 프레임워크
쿼리를 분석하고, 최적화하고, 실행 계획으로 바꾸는 엔진
- Catalyst = 전체 엔진
- Catalyst Optimizer = 그 안의 일부(최적화 담당)
| 항목 | Catalyst | Catalyst Optimizer |
| 범위 | 전체 엔진 | 일부 모듈 |
| 역할 | 쿼리 처리 전체 | 최적화 |
| 포함 관계 | Optimizer 포함 | Catalyst에 포함됨 |
Catalyst 전체구조
User Code (DataFrame / SQL)
↓
Catalyst
├─ Parser
├─ Analyzer
├─ Optimizer
└─ Planner
↓
Execution (Task 실행)카탈리스트의 확장 가능한 설계의 목적
- Spark SQL에 새로운 최적화 요소나 기술 추가를 쉽게 할 수 있게 하기
- 외부 개발자들이 Optimizer를 확장시키는 것을 가능하게 하기
Catalyst에서는 4개 부분으로 나누어 Tree에 Transformation을 수행한다
- Analysis
- Logical Plan Optimization
- Physical Planning
- Code Generation
Catalyst Optimizer
사용자가 작성한 연산을 더 빠르게 실행되도록 재구성하는 최적화 엔진
User Code (DataFrame / SQL)
↓
Logical Plan 추상적인 연산 계획 생성
↓
Analysis 컬럼 존재 여부 확인 / 타입체크
↓
Logical Optimization ← Catalyst 성능이 결정됨
↓
Physical Plan 선택 “어떻게 실행할지” 결정
↓
Execution 실제 Task 실행

Tungsten
Tungsten은 Spark의 실행엔진으로, 바이너리 기반 데이터 처리와 off-heap 메모리 관리, whole-stage code generation을 통해
Cpu와 메모리를 직접 제어하여 Spark 연산을 최대한 빠르게 실행하는 저수준 실행 엔진 으로 스파크 성능을 실제로 만들어 내는 실행엔진 입니다.
Tungsten이 왜 나왔냐
기존문제
- JVM object 사용
- GC (Garbage Collection) 비용 큼
- 메모리 비효율
- CPU 활용 낮음
해결목표
- 메모리 직접 관리
- CPU cache 활용
- object 제거
Tungsten 핵심 기능
- Off-Heap Memory (메모리 직접관리) : JMV heap 밖에서 메모리 사용, Gc부담 감소, 메모리 효율 증가
- Binary Processing (객체 제거) : 객체(Object)가 아닌 “바이너리 형태”로 데이터를 처리하는 방식([kim][30], 연속된 메모리 배열)
- Whole-Stage Code Generation : 여러 연산을 하나의 Java 코드로 합쳐서 실행하는 최적화 기법
Catalyst vs Tungsten
| 항목 | Catalyst | Tungsten |
| 역할 | 계획 최적화 | 실행 최적화 |
| 단계 | Logical / Physical Plan | 실제 실행 |
| 대상 | 쿼리 구조 | CPU / 메모리 |
| 예 | filter pushdown | codegen |
RDD VS DataFrame VS Dataset
| 항목 | RDD | DataFrame | Dataset |
| 수준 | Low-level | High-level | High-level |
| 구조 | ❌ 없음 | ✅ 있음 | ✅ 있음 |
| 타입 안정성 | ❌ 없음 | ❌ 없음 | ✅ 있음 |
| 최적화 | ❌ 없음 | ✅ Catalyst | ✅ Catalyst |
| 실행 엔진 | 기본 | Tungsten | Tungsten |
| 사용성 | 어려움 | 쉬움 | 중간 |
| 언어 | 모두 | 모두 | Scala/Java |
“RDD는 Spark의 기본 데이터 구조로 불변성과 분산 처리를 제공하지만 최적화가 없어 성능 관리가 어렵습니다. 반면 DataFrame은 스키마 기반 구조를 가지며 Catalyst Optimizer와 Tungsten 엔진을 통해 자동으로 실행 계획이 최적화됩니다. Dataset은 DataFrame에 타입 안정성을 추가하여 컴파일 단계에서 오류를 잡을 수 있습니다. 따라서 실무에서는 생산성과 성능을 고려해 대부분 DataFrame을 사용하고, Scala 환경에서 타입 안정성이 필요할 때 Dataset을 선택합니다.”
Transformation
- 새로운 RDD를 반환
- 지연평가 (Lazy)
- 실제 연산은 Action 시점에 수행
| 연산 | 설명 |
| map(f) | 각 요소에 함수 f 적용 |
| filter(f) | 조건 f를 만족하는 요소만 선택 |
| flatMap(f) | 각 요소를 0개 이상의 요소로 변환 |
| distinct() | 중복 제거 |
| union(rdd) | 두 RDD 합치기 |
| groupByKey() | 키별로 그룹화 |
| reduceByKey(f) | 키별로 값 집계 |
| sortByKey() | 키로 정렬 |
Action
- 결과를 반환하거나 저장
- 즉시 실행 (Eager)
- Job을 생성하고 실행
| 연산 | 설명 |
| collect() | 모든 요소를 Driver로 가져옴 |
| count() | 요소 개수 반환 |
| first() | 첫 번째 요소 반환 |
| take(n) | 처음 n개 요소 반환 |
| reduce(f) | 모든 요소를 함수 f로 집계 |
| foreach(f) | 각 요소에 함수 f 실행 |
| saveAsTextFile(path) | 텍스트 파일로 저장 |
Transformation VS Action
| Transformation(Lazy) | Action(실행 트리거) |
| map | show |
| filter | collect |
| select | count |
Cache / Persist
Cache와 Persist는 Spark에서 중간 연산 결과를 메모리 또는 디스크에 저장하여 재사용함으로써 반복 연산을 방지하고 성능을 향상시키는 기능이며, Cache는 연산 결과를 메모리에 저장해서 재사용하는 기능 을하며 Persist는 다양한 저장 옵션을 제공하는 확장된 개념입니다
val rdd = sc.textFile("data/large_file.txt")
.flatMap(_.split(" "))
.map(w => (w, 1))
.reduceByKey(_ + _)
// 캐싱: 이후 Action에서 재계산 없이 메모리에서 읽음
rdd.cache() // = persist(StorageLevel.MEMORY_ONLY)
rdd.count() // 첫 번째 Action: 계산 후 메모리에 저장
rdd.take(10) // 두 번째 Action: 메모리에서 바로 읽음 (빠름!)
// 캐시 해제
rdd.unpersist()저장 수준
| Storage Level | 설명 |
| MEMORY_ONLY | 메모리에만 저장 (기본값, cache()) |
| MEMORY_AND_DISK | 메모리 부족 시 디스크에 저장 |
| DISK_ONLY | 디스크에만 저장 |
| MEMORY_ONLY_SER | 직렬화하여 메모리 절약 |
언제 캐싱하는가?: 같은 RDD에 여러 Action을 호출하거나 반복 알고리즘(ML 등)에서 사용할 때.
Lineage (계보)
RDD는 자신이 어떤 RDD에서 어떤 Transformation을 거쳐 만들어졌는지 기록한다.
textFile("file.txt") → flatMap(split) → map((_,1)) → reduceByKey(+)
RDD_0 RDD_1 RDD_2 RDD_3
Lineage의 역할
- 장애 복구: 노드 장애로 파티션이 유실되면 Lineage를 따라 해당 파티션만 재계산
- 재계산: 디스크에 저장하지 않으므로 체크포인트 없이도 복구 가능
- rdd.toDebugString 으로 Lineage 확인 가능
Data Skew = Partition에 데이터가 과도하게 몰리는 현상
특정 Partition에 데이터가 집중되어 일부 Task만 오래 실행되는 현상으로, 병렬 처리 효율을 떨어뜨립니다.
- 병렬 처리 붕괴 1개 Task만 오래 걸림 → 전체 성능 = 가장 느린 Task
- OOM (Out Of Memory)특정 Partition이 너무 큼 ,메모리 초과 ,executor 죽음
- Shuffle 병목
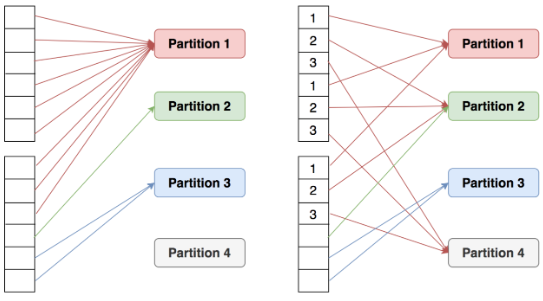
Data Skew 발생시점
- join
- groupby/ aggregation
- 데이터 불균형
Data Skew를 언제 의심해야하나?
- 특정 Task만 오래 걸림
- Stage에서 일부 Task만 남음
- executor 하나만 계속 일함
Shuffle
Shuffle은 Spark에서 데이터를 key 기준으로 재분배하기 위해 Partition 간에 네트워크로 이동시키는 과정으로, 디스크 I/O와 네트워크 비용이 발생하여 성능에 큰 영향을 미치는 연산입니다
- 기존 Partition에 데이터 있음
- key 기준으로 다시 나눠야 함
- 다른 노드로 데이터 이동
Stage 1 → Shuffle → Stage 2Shuffle 발생시점
데이터 기준(key)이 바뀔 때
- 같은 key끼리 모아야 함
- 데이터 이동 필요
- Shuffle 발생
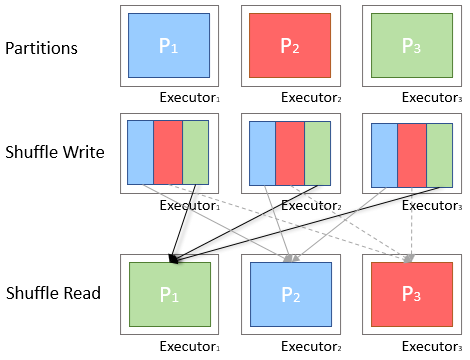
Shuffle 상세
Shuffle은 Wide Transformation에서 발생하는 데이터 재분배 과정이다.
Map Side Reduce Side
┌──────────────────┐ ┌──────────────────┐
│ Executor 1 │ │ Executor 1 │
│ Partition 0 │──── key A ──▶│ Partition 0 │
│ [A:1, B:2, A:3] │──── key B ──▶│ [A:1, A:3, A:2] │
└──────────────────┘ └──────────────────┘
┌──────────────────┐ ┌──────────────────┐
│ Executor 2 │ │ Executor 2 │
│ Partition 1 │──── key A ──▶│ Partition 1 │
│ [A:2, C:1, B:1] │──── key C ──▶│ [B:2, B:1, C:1] │
└──────────────────┘ └──────────────────┘
Shuffle이 비용이 큰 이유:
- 데이터를 로컬 디스크에 기록 (Map Side)
- 네트워크를 통해 다른 Executor로 전송
- 수신 측에서 다시 정렬/병합 (Reduce Side)
Narrow Transformation
데이터 이동 없이 같은 Partition 안에서 끝나는 연산
- Shuffle 없음
- 하나의 부모 파티션 → 하나의 자식 파티션
- 메모리 내 처리
Parent RDD Child RDD
┌──────────┐ ┌──────────┐
│Partition1│ ─────→ │Partition1│
└──────────┘ └──────────┘
┌──────────┐ ┌──────────┐
│Partition2│ ─────→ │Partition2│
└──────────┘ └──────────┘
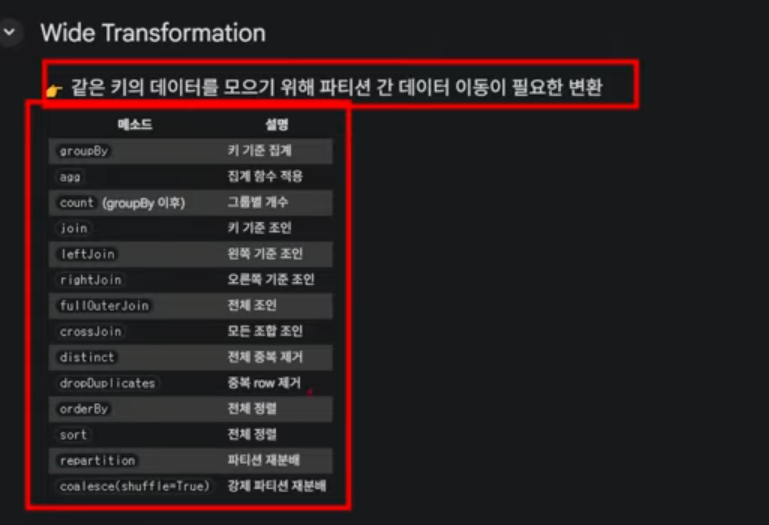
Wide Transformation
데이터를 재분배(Shuffle)해야 수행되는 연산
- Shuffle 발생
- 여러 부모 파티션 → 하나의 자식 파티션
- 성능 병목 발생
Parent RDD Child RDD
┌──────────┐ ╲ ┌──────────┐
│Partition1│ ───╲──→│Partition1│
└──────────┘ ╳ └──────────┘
┌──────────┐ ╱ ┌──────────┐
│Partition2│ ───╱──→│Partition2│
└──────────┘ └──────────┘- 네트워크 I/O 발생
- 디스크 I/O 발생 (중간 결과 저장)
- 성능 병목의 주요 원인
Narrow vs Wide
| 항목 | Nerrow | Wide |
| 데이터 이동 | 없음 | 있음 |
| Shuffle | 없음 | 있음 |
| Partition | 유지 | 재구성 |
| 성능 | 빠름 | 느림 |
| Stage | 유지 | 분리됨 |
Wide Transformation은 데이터를 Partition 간 재분배(Shuffle)하여 수행되는 연산으로, Spark에서 가장 큰 성능 비용을 유발한다
Shuffle의 내부동작
[Map Stage]
↓
Sort (메모리 정렬)
↓
Spill (디스크로 떨어짐)
↓
Shuffle 파일 생성
↓
[Reduce Stage]
↓
Merge (여러 파일 합침)
↓
최종 처리Sort (정렬)
👉 Map Task에서 발생
- 데이터를 Key 기준으로 정렬
- 같은 key끼리 모으기 위한 준비
(key1, value)
(key2, value)
(key1, value)
↓
정렬됨
(key1, value)
(key1, value)
(key2, value)
이유 : Reduce 단계에서 빠르게 처리하기 위해서이다.
Spill (디스크로 내림)
메모리가 부족하면 발생
- 정렬된 데이터를 디스크에 임시 저장
메모리 초과
↓
spill file 1 생성
spill file 2 생성
...Shuffle Write
Map Stage 끝날 때
- Partition별로 데이터 나눠서 저장
Partition 1 → Node A
Partition 2 → Node B네트워크로 전송 준비
Shuffle Read (네트워크)
Reduce Stage 시작
- 다른 노드에서 데이터 가져옴
여기서 병목 많이 발생:
- 네트워크 비용
- 데이터 크기
Merge (병합)
여러 Spill 파일을 하나로 합침
spill file 1
spill file 2
spill file 3
↓
merge
↓
하나의 정렬된 데이터
특징:
- 다시 정렬 유지
- CPU + 디스크 사용
Reduce 처리
- groupBy
- join
- aggregation
Spark SQL vs DataFrame vs RDD
| 구분 | RDD | DataFrame | Spark SQL |
| 추상화 수준 | 낮음 (로우 레벨) | 중간 | 높음 |
| 데이터 구조 | 객체 (Java/Scala/Python) | 테이블 형태 (Row + Schema) | SQL 테이블 |
| 타입 안정성 | O (컴파일 타임) | △ (언어에 따라 다름) | X |
| 최적화 | 없음 (수동 최적화) | Catalyst 최적화 | Catalyst 최적화 |
| 사용 난이도 | 어려움 | 보통 | 쉬움 |
| 성능 | 느림 | 빠름 | 빠름 |
Spark SQL이 편리한 이유
- 사용하는 데이터 포맷이 parquet이고, SQL만으로 처리할 수 있는 경우 schema에 매핑되는 클래스를 정의할 필요가 없다.
- Spark SQL에서는 Catalyst Optimizer가 최적화를 대신해준다.
- DataFrame은 Untyped Data인 Row를 사용하기 때문에 연산에 제한이 있었지만, Dataset은 Typed Data로 변환하여 처리하기 때문에 DataFrame보다 좀 더 복잡한 연산이 가능하다.
DataFrame이란?
DataFrame은 스키마(컬럼 이름과 타입)가 있는 분산 데이터 컬렉션이다.
관계형 데이터베이스의 테이블이나 Pandas DataFrame과 유사하다.
┌─────────────────────────────────────────────────────────────────┐
│ DataFrame │
│ │
│ ┌──────────┬──────────┬──────────┐ │
│ │ name │ age │ city │ ← 스키마 (컬럼 정의) │
│ │ (String) │ (Int) │ (String) │ │
│ ├──────────┼──────────┼──────────┤ │
│ │ Alice │ 30 │ Seoul │ ← Row 1 │
│ │ Bob │ 25 │ Busan │ ← Row 2 │
│ │ Charlie │ 35 │ Seoul │ ← Row 3 │
│ └──────────┴──────────┴──────────┘ │
│ │
│ 파티션 1: [Alice, Bob] 파티션 2: [Charlie]
└─────────────────────────────────────────────────────────────────┘Spark SQL vs Trino
Apache Spark SQL = 데이터 “처리(가공)” 엔진
Trino = 데이터 “조회(질의)” 엔진
| 항목 | Spark SQL | Trino |
| 역할 | ETL / 데이터 처리 | 쿼리 엔진 |
| 실행 방식 | Batch 중심 | Interactive (빠른 조회) |
| 결과 저장 | 가능 | 없음 |
| 목적 | 데이터 생성 | 데이터 조회 |
실무 사용 예시
| 상황 | 엔진 |
| "어제 들어온 샘플 전부 재처리해줘" | Spark |
| "breast 조직 샘플 몇 개야?" | Trino |
| "대시보드에 샘플 통계 연결해줘" | Trino |
| "expression matrix Parquet로 변환해줘" | Spark |
| "지난달 데이터로 클러스터링 돌려줘" | Spark |
RDD vs DataFrame
| 특성 | RDD | DataFrame |
| 스키마 | 없음 (타입만 있음) | 있음 (컬럼 이름 + 타입) |
| 최적화 | 없음 | Catalyst Optimizer |
| API | 저수준 (map, reduce) | 고수준 (select, filter, join) |
| 성능 | 직접 최적화 필요 | 자동 최적화 |
| 언어 간 성능 | Java/Scala만 빠름 | Python도 빠름 (JVM에서 실행) |
| 사용 용도 | 비정형 데이터, 세밀한 제어 | 구조화된 데이터, 일반적인 분석 |
왜 DataFrame이 더 빠른가?
DataFrame은 Catalyst Optimizer를 통해
- 논리적 실행 계획 생성
- 규칙 기반 최적화 (불필요한 연산 제거, 조건 푸시다운)
- 비용 기반 최적화 (최적의 조인 전략 선택)
- 코드 생성 (Java 바이트코드 동적 생성)
데이터 포맷 읽기/쓰기
| 포맷 | 특징 | 용도 |
| Parquet | 컬럼 기반, 압축, 스키마 포함 | 분석용 저장 (권장) |
| CSV | 텍스트, 호환성 높음 | 데이터 교환 |
| JSON | 중첩 구조 지원 | API 데이터 |
| ORC | Hive 최적화 컬럼 포맷 | Hive 환경 |
'Spark' 카테고리의 다른 글
| [Spark] - Spark Performance Tuning (0) | 2026.03.28 |
|---|---|
| [Spark] - 파티션 최적화 (0) | 2026.03.25 |
| [Spark] - Json 데이터 다루기(with_Explode) (0) | 2026.03.24 |
| [Spark] - Null값 처리 (0) | 2026.03.24 |
| [Spark] - 정규식을 통한 문자열 처리 (0) | 2026.03.23 |