
데이터 모델은 우리가 어떤 문제를 어떻게 해결해야 하는지, 생각에도 영향을 미친다.
데이터 모델은 그 위에서 소프트웨어가 할수 있는 일과 할수 없는 일에 영향을 준다.
ex) 어떤 연산은 빠르고, 어떤 연산은 느리다.
데이터 모델의 큰 범주
- 관계형 모델
- 문서 모델
- 그래프 모델
1. 관계형 모델과 문서 모델
- 관계형 모델
- 데이터는 관계(relation)로 구성
- 각 관계는 순서없는 튜플(tuple)의 모음
- SQL은 정규화된 구조로 데이터를 저장하고 질의할 필요가 있을때, 대부분 사용
- NoSQL의 탄생: Not Only SQL
- 대규모 데이터셋이나 높은 쓰기 처리량을 달성
- 무료, 오픈소스 소프트웨어 선호
- 관계형 모델에서 지원하지 않는 특수 질의
- 관계형의 스키마 제한에 대한 불만, 동적이고 표현력 풍부한 데이터 모델을 선호
1-1 데이터 모델들이 관계를 표현하는 방법
- 객체 관계형 불일치
- OOP의 객체를 SQL 데이터 모델로 바꾸려면 거추장스러운 전환 계층이 필요: Impedance 불일치
- Impedance : 방해,저지 라는 의미
- ActiveRecord 나 Hibernate 같은 ORM 으로 boilerplate code를 줄이지만, 여전히 두 모델의 차이가 완벽히 숨겨지진 않는다.
- ex:) 1:N 관계를 관계형 모델로 표현하려면
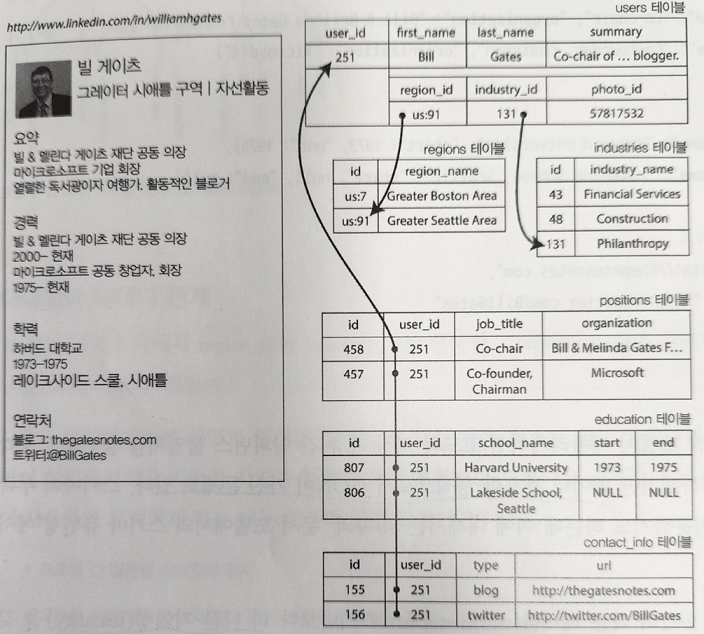
1. multi table 스키마로 정규화하고 JOIN
2. 구조화된 데이터 타입 사용(xml,json)하여 저장. 최신 표준 RDMS는 이런 타입도 질의,색인 가능
3. 자체적으로 부호화해서 저장하여 응용단에서 활용,질의,색인 불가능
- 문서 지향(document oriented) DB를 사용하면 JSON 데이터 모델을 지원하는데, 위와 같은 문제를 쉽게 해결
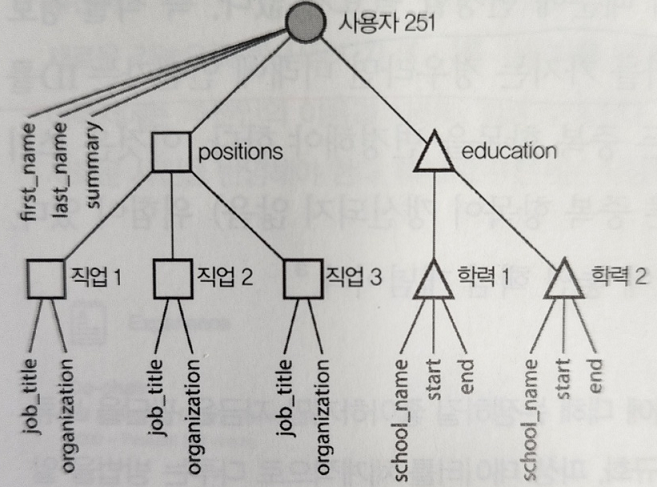
- 1:N 관계는 의미상 트리구조와 같다.
- JSON 데이터 모델 표현은 multi table 스키마보다 더 나은 지역성(locality)을 갖는다.
- NoSQL 들이 분산 환경을 지원하는 관점에서, 물리적인 지역성(seek)보다는 스키마의 집약성을 이야기하는듯하다.
N대 1관계
- ex:) N명이 하나의 학교를 가르킴
- 지역명이나 학교명을 평문으로 저장하게 되면, 나중에 이름이 바뀌었을 때 갱신하기 어려워진다.
- unique id 로 저장하게 된다면, id 자체는 아무런 의미가 없기 때문에 변경할 필요가 없어진다.
- id가 의미를 갖게되면, 미래에 언젠가 id를 변경해야 할 수도 있다.
- 이러한 중복된 데이터(N대 1)를 정규화 하는것은 관계형 모델에선 쉽지만, 문서 지향에선 어렵다.
- DBMS가 JOIN을 지원해주지 않으면, 어플리케이션에서 다중 질의를 해서 join을 흉내내야 한다.
- 지금은 join이 필요없게 만들더라도, 비즈니스가 확장되가며, 데이터는 점차 상호 연결되는 경향이 있다.
N대 M관계
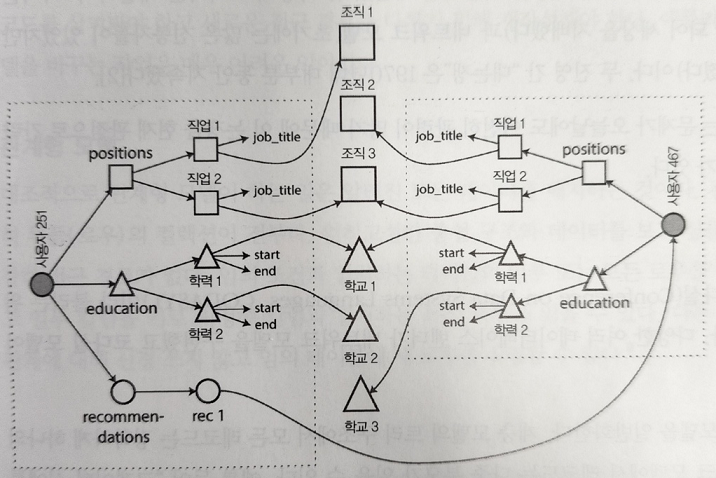
- ex:) 프로필에 추천해준 사람들의 프로필이 뜬다. 이때, 추천인이 사진을 바꾸면, 이사람이 추천해준 모든 사람 내 프로필의 추천인 사진이 바뀌어야 한다. 즉 엔터티를 참조해야 한다.
- N대 1과 N대 M처럼 다대다 관계에서 데이터를 중복할지, 아니면 분리하고 수동으로 참조해야 할 지에 대한 논쟁은,NoSQL 이전부터 있었다.
- 1970년대 계층모델(JSON 데이터 모델과 유사)에서 이 문제를 해결하기 위한 관계형 모델의 join vs 네트워크 모델
- 계층 모델: 트리 구조에서 모든 레코드는 하나의 부모만 있다. 1대N에선 쉽게 동작한다.
- 오늘 날의 JSON 모델과 비슷하다
- N대 M관계를 표현하려면,데이터를 중복하거나 다른 레코드 참조를 수동으로 해결해야만 했다.
- 네트워크 모델: 레코드는 다중 부모가 있을수 있다. 따라서, N대 1,N대M 문제를 해결
- 레코드 간 연결은 외래 키보다는 포인터와 유사
- 레코드에 접근하는 방법은 root에서 연속된 연결 경로를 따라가는것
- N대 M에서는 다양한 경로가 있을수 있어서, 개발자가 경로 선택, 탐색을 해줘야 했다.
- 외래 데이터를 삽입하는것 자체가 join이 이미 수행된 것
- 관계형 모델: 관계는 단순히 튜플의 컬랙션일 뿐
- 외래 관계에서도 새로운 레코드를 쉽게 생성가능하다.
- 개발자는 접근 경로를 신경쓸 필요가 없다. 질의 최적화로 자동으로 만든다.
- 문서 지향 DB
- N대1, N대M 관계를 표현할 때는 RDB와 다르지 않다. 외래키와 같이 문서를 참조한다.
- 네트워크 모델은 이것을 복잡하게 지원해서 망했지만, 오늘 날의 문서지향 DB들은 이 부분을 수용했다.
1-2 문서 모델
- 문서 모델에 적합한 어플리케이션은?
- 문서와 비슷한 구조(1대 N, 트리구조로 한번에 전체 트리를 적제)라면 문서 모델
- 문서 모델의 제약
- embed된 field를 직접 참조할수 없음: root.education.list[1] 와 같이 접근 경로로 해야함
- N대M 관계를 사용해야하면 매력이 떨어짐
- 비정규화로 JOIN을 줄일수 있으나,일관성을 맞추기 위한 추가 작업이 소요
- cf) mongo db 4.0부터 updateMany로 multi document transaction을 지원하면서 좀 더 쉬워지긴 함
- 어플리케이션 단 JOIN으로 풀수도 있으나, DBMS에서 지원해주는 것보다 느림
- cf) mongo db 3.2부터aggregate 에서 $lookup으로 join을 지원하나, 샤딩된 컬렉션에서 사용할수 없음.
- 상호 연결이 많은 데이터일 수록 문서모델은 곤란, 관계형 모델은 무난, 그래프 모델은 매우 자연스럽다.
- 문서 모델의 스키마 유연성(schemaless)
- 사실 스키마가 완전히 없다고 볼수는 없다.
- 쓰기 스키마는 없지만, 읽기 스키마가 암묵적으로 존재하기 때문이다.
- 쓰기 스키마: 정적 타입 확인, RDB의 방식. 이게 없다면 임의의 키와 값을 자유롭게 추가
- 읽기 스키마: 동적 타입 확인, 문서DB의 방식. 이게 없다면 필드의 존재여부가 보장되지 않음
- 즉, 어플리케이션은 데이터를 읽는 코드가 있으므로 읽기 스키마를 어느정도 가정하고 사용한다.
- 예를들어, fullname을 저장하고 있다가, 성과 이름을 분리하는 작업이 있다고 가정하면,
- 문서 모델: firstName,lastName을 그냥 추가해서 저장하면 된다. 대신, 작업날짜를 기점으로 과거 데이터는 fullname을 split 쳐서 읽어야 한다.
- 관계 모델: ALTER TABLE users ADD COLUMN firstName VARCHAR(20)으로 쓰기 스키마를 변경하고 마이그레이션을 해줘야 한다. 중단시간이 발생할 수도 있다.
- 읽기 스키마 방식은 컬랙션 내 문서들이 모종의 이유로 동일한 구조가 아닐때 유리하다.
- 하위에 여러 유형의 Object들이 있을 때, 각 유형마다 table을 만드는 것은 실용적이지 않으므로..
- 개발자가 정적으로 제어하는게 아니라, 언제나 변경 가능한 외부 시스템에 의해 데이터 구조가 결정될 수 있다.
- 저장소 지역성(storage locality)
- 관련 데이터를 함께 그룹화하는 개념
- 문서는 json,xml로 부호화된 문자열이나 BSON 같은 바이너리로 저장된다.
- 문서 중 일부만을 접근경로로 꺼내서 사용하지 않고, 전체를 잘 사용한다면 지역성의 이점을 누렸다고 볼 수 있다.
- 전체를 찾아야 한다면 RDB는 multi table을 Join해야 하므로 이런 지역성 관점에선 좋치 않다.
- 부호화된 문서의 크기를 바꾸지 않는 수정이라면 문서 DB는 수정을 쉽게 수행한다.
- 문서의 구조, 크기가 증가하는 쓰기를 피하려고 하는 이유 : 색인같은걸 다시쓰는거같다.
- 필드수준의 업데이트를 권고
- 이성능 제한때문에 유용한 상황이 줄어든다.
- $inc 같은걸 지원하는 이유다.
- https://www.mongodb.com/blog/post/schema-design-for-time-series-data-in-mongodb
스키마 설계 - 데이터베이스 매뉴얼 - MongoDB Docs
스키마 설계 프로세스 애플리케이션 에 필요한 데이터를 식별하고 구성하여 성능을 최적화하는 데 도움이 됩니다.개발 프로세스 초기에 스키마 계획하고 설계합니다. 이렇게 하면 애플리케이
www.mongodb.com
- 문서 모델에만 있는것은 아니다.
- 오라클의 multi-table index cluster table
- column-family 개념(카산드라, HBase)의 지역성
2. 데이터를 위한 질의 언어
- 명령형 언어는 특정 순서로 특정 연산을 수행하라고 일일히 모두 정의하고 지시한다.
- 결과를 결정하기 위한 알고리즘을 모두 지정
- 멀티 코어 병렬 처리가 어려움
- cf) 네트워크 모델류의 DB와 IMS가 이런 형태를 사용함
- ex:) 특정 html 태그를 javascript로 DOM API를 사용해서 스타일링 하는 것. 더 좋은 api를 사용하려면 코드 바꿔야한다.
- SQL, 관계대수(relational algebra)같은 선언형 언어는 결과를 충족해야 하는 조건과 변환을 지정해주기만 하면 된다.
- 내부적으로 어떤 순서로 어떤 연산을 수행할지는 쿼리 최적화기가 알아서 한다.
- 멀티 코어 병렬 처리도 알아서 활용
- ex:) 특정 html 태그를 css(선언형)로 꾸미는것, 브라우저 벤더가 알아서 최적화 함.
2-1 맵 리듀스(MapReduce) 질의
- 클러스터 환경에서 분산실행을 위한 프로그래밍 모델
- 많은 컴퓨터에서 대량의 데이터를 처리
- 일부 NoSQL DBMS가 지원
- 선언형 언어도 아니고 명령형 언어도 아닌 중간지점에 있다. pure한 javascript 함수 2개를 정의
db.collection.mapReduce({
function map() {
var year = this.timestamp.getFullYear();
var month = this.timestamp.getMonth() + 1;
emit(year + "-" + month, this.number);
},
function reduce(key, values) { reutrn Array.sum(values); },
{
query: { type: "A" },
out: "monthlyCount"
}
})
- 이것은 저수준의 모델이다. js함수를 어떻게 작성하느냐에 따라 선응이 달라질 수도 있고 어렵다.
- mongodb 2.2부터 aggregation pipline을 통해 선언형 질의를 지원한다.
db.collection.aggregate([
{ $match: { type: "A" } },
{ $group: {
_id: {
year: { $year: "$timestamp" },
month: { $month: "$timestamp" },
},
monthlyCount: { $sum: "$number" }
}}
])
MongoDB showdown: Aggregate vs map-reduce. | Sysdig
We compared the performance of Map-Reduce & Aggregate in MongoDB by using Sysdig Cloud's deep visibility into MongoDB metrics. See the results today!
www.sysdig.com


맵-집계 파이프라인으로의 맵 리듀스 - 데이터베이스 매뉴얼 - MongoDB Docs
집계 파이프라인은 맵 리듀스 작업보다 더 나은 성능과 사용성을 제공합니다.맵 리듀스 작업은 $group 및 $merge 등 집계 파이프라인 단계를 사용해 다시 작성할 수 있습니다.사용자 지정 기능이 필
www.mongodb.com
3.그래프형 데이터 모델
- N대M 관계가 일반적일 때 사용
- 그래프 = 정점(=노드,엔터티,vertex) + 간선(관계,호,edge)
- 단일 노드에서 사용 예제
- 소셜 그래프: vertex = 사람, edge = 사람들이 서로 알고 있음
- 웹 그래프: vertex = 웹페이지, edge = 다른 페이지로의 링크
- ex:) pagerank: 웹페이지의 인기와 검색 결과에서 순위 결정
- 교통 네트워크 : vertex = 교차로, edge = 교차로 간 도로, 철도
- ex:) 네비게이션 : 최단 경로 탐색
- 복합 노드에서 사용 예제
- 페이스북 : vertex = 사람,장소, 이벤트, 댓글 등, edge = 친구여부, 체크인 위치, 이벤트 참석, 포스트 댓글 등
- 그래프 모델
- 속성 그래프 모델 : Neo4j, titan, InfiniteGraph
- 트리플 저장소 모델: Datomic,AllegroGraph
- 그래프 질의 언어
- 선언형 질의 언어: 사이퍼(Cypher), 스파클(Sparql), Datalog
- 명령형 질의 언어: 그램린(Gremlin)
- 그래프 처리 프레임 워크 : 프리글(Pregel)
3-1. 속성 그래프 모델
- vertex의 요소
- 고유한 식별자
- outgoing edge 집합: 이 vertex 에서 나가는 간선들
- incoming edge 집합: 이 vertex로 들어오는 간선들
- 속성(attribute) 컬랙션(key-value 쌍)
- edge의 요소
- 고유한 식별자
- edge가 시작하는 vertex: tail vertex = 꼬리 노드
- dege가 끝나는 vertex: head vertex = 머리노드
- 두 vertex 간 관계 유형을 설명하는 레이블
- 속성(attribute) 컬랙션(key-value 쌍)
3-1-1. 싸이퍼 (Cypher)질의 언어
- 속성 그래프를 위한 선언형 질의 언어
- neo4j 용으로 만들어 졌다.
- CREATE (USA:Location {name:'USA', type:'country}), (Idaho:Location {name:'Idaho', type:'state'}))
- () -> [:WITHIN*0..] -> () : 0회 이상 WITHIN edge을 따라 가라
- 순방향으로 질의할 수도 있지만, 역방향으로 질의할 수도 있다.
3-1-2. SQL 에서 Graph 질의
- 관계형 스키마로 표현
CREATE TABLE vertices (
vertex_id INTEGER PRIMARY KEY,
properties JSON
);
CREATE TABLE edges (
edge_id INTEGER PRIMARY KEY,
tail_vertex INTEGER REFERENCES vertices (vertex_id),
head_vertex INTEGER REFERENCES vertices (vertex_id),
label TEXT,
properties JSON
)
CREATE INDEX edges_tails ON edges (tail_vertex); # vertex 가 주어지면 outgoing edge 집합을 쉽게 찾음
CREATE INDEX edges_heads ON edges (head_vertex); # vertex 가 주어지면 incoming edge 집합을 쉽게 찾음- SQL 에서는 질의에 필요한 Join을 미리 알고 있어야하지만,
- 그래프 질의에서는 찾고자 하는 vertex를 찾기 전에 가변적인 여러 edge를 순회해야 한다. 따라서, 미리 Join수를 알 수가 없다.
- SQL에서 굳이 어렵게라도 하려면, 재귀 공통 테이블식(recursive common table expression)을 통해 구현할 수 있다.
WITH RECURSIVE 가상테이블1명 AS (
SELECT - # 초기질의
UNION [ALL]
SELECT - # 재귀질의
[WHERE -] # 종료 조건
), ( 가상테이블2명 AS ... ), ( ... )- 책에서는 RDBMS에서 그래프 데이터 모델을 권장하고 있진 않지만, 스토리지 엔진으로 InnoDB 대신 그래프 엔진을 선택하면 위에보단 나은 성능을 가져간다.
- MariaDB: OQGRAPH(Open Query Graph)
OQGRAPH | Server | MariaDB Documentation
Explore the OQGRAPH storage engine in MariaDB Server. Learn how to efficiently manage hierarchical and complex graph data structures, perfect for social networks and bill of materials.
mariadb.com
3-1-3. 문서 DB에서 Graph 질의
- mongodb 3.4부터 $graphLookup을 지원한다.
- $lookup과 마찬가지로 sharding 컬렉션에선 사용 불가능
- 일반적인 graph 유즈케이스의 70% 정도를 커버
3-2 트리플 저장소 모델
- 트리플 저장소 모델은 같은 생각을 다른 용어로 사용해서 설명할 뿐, 속성 그래프 모델과 거의 동등하다.
- three-part(트리플) statements:주어(subject) + 서술어(predicate) + 목적어(object)
- ex:) 빨간색소년(=주어)은 사과(=목적어)를 좋아(=서술어)한다.
- 주어 = vertex
- 목적어
- 원시 데이터값(정수, 문자열)이라면, 서술어와 목적어는 각각 vertex 속성의 key와 value이다.
- 그래프의 다른 vertex 이라면, 서술어는 edge 이고, 주어는 꼬리노드, 목적어는 머리 노드이다.
- turtle 형식으로 트리플 작성 예제
- turtle 문법:https://www.w3.org/TR/turtle/
RDF 1.1 Turtle
Abstract The Resource Description Framework (RDF) is a general-purpose language for representing information in the Web. This document defines a textual syntax for RDF called Turtle that allows an RDF graph to be completely written in a compact and natural
www.w3.org
- _:lucy a :Person.
- _:lucy :name "Lucy". : vertex lucy의 name은 Lucy다.
- _:lucy :bornIn _:idaho. : vertex lucy 는 vertex idaho 에서 태어났다.
3-2-1. 스파클(SPARQL) 질의 언어
https://www.w3.org/TR/sparql11-query/
SPARQL 1.1 Query Language
Abstract RDF is a directed, labeled graph data format for representing information in the Web. This specification defines the syntax and semantics of the SPARQL query language for RDF. SPARQL can be used to express queries across diverse data sources, whet
www.w3.org
- SPARQL Protocol RDF Query
- SPARQL Protocol and RDF Query Language
RDF 데이터 모델을 사용한 트리플 저장소 질의 언어
RDF = Resource Description Framework
시맨틱 웹에서 유래 : 서로 다른 웹사이트가 일관된 형식으로 데이터를 개시한다면, 만물을 데이터베이스처럼 쓸 수 있을 것이다.
사람이 읽을 수 있는 형식
인터넷 전체의 데이터 교환을 위해 설계
사이퍼 보다 먼저 만들어지고, 사이퍼가 스파클의 일부를 차용함
스파클은 변수를 ?으로 시작
ex1) 미국에서 유럽으로 이주한 사람 찾기
사이퍼 : (person) -[:BORN_IN] -> () -[:WITHIN*0..] -> (location)
스파클 : ?person :bornIn / :within* ?location
ex2) usa 변수 선언
사이퍼 : (usa {name:'United States})'
스파클 : ?usa :name 'United States'.
3-3 DataLog
- 1980년대 탄생, 가장 오래되었음
서술어(주어, 목적어)로 작성한다.
name(usa, 'United States')
within(idaho, usa)
변수는 대문자로 시작
사이퍼나 스파클은 바로 SELECT로 질의하지만, Datalog 는 단계를 나눠 조금씩 질의하며 나아간다.
3-4 그래프 데이터 모델과 네트워크 모델의 차이점
| 네트워크 모델 | 그래프 모델 | |
|---|---|---|
| 스키마 | 중첩 가능한 레코드 타입을 지정 | vertex는 edge 로 다른 vertex와 자유롭게 연결 |
| 특정 레코드 도달 | 접근 경로 중 하나씩 탐색 | 고유id로 직접 참조 or 색인을 통해 빠르게 탐색 |
| 정렬 | tree구조라 삽입 시점에 정렬해둠 | 읽기 질의를 할때 유연하게 정렬 |
| 질의어 | 명령형, 스키마 변경에 따라 질의어 변경필요 | 선언형 |
'0️⃣Algorithm&자료구조&codingTest > Book&Study' 카테고리의 다른 글
| [데이터중심 애플리케이션 설계] - 4장 부호화와 발전 (1) | 2026.01.19 |
|---|---|
| [데이터중심 애플리케이션 설계] - 3장 저장소와 검색 (1) | 2026.01.18 |
| [데이터 중심 애플리케이션 설계] - 1장. 신뢰할수 있고 확장가능하며 유지보수 하기 쉬운 어플리케이션 (0) | 2026.01.11 |
| [견고한 데이터 엔지니어링] (0) | 2026.01.05 |
| [데이터 중심 애플리케이션] (0) | 2025.12.19 |



