부호화와 발전 Encoding & Evolution
여러가지 이유로 Application은 변하게 된다. 그리고. Application 기능을 변경하기 위해서는 저장하는 데이터도 변경해야 한다.
서버,클라이언트 측 어플리케이션이 계속 유동적으로 변하기 때문에 예전 버전 코드와 새로운 버전 코드,이전의 데이터 타입과 새로운 데이터 타입이 모든 시스템에서 공존할 수 있기 때문에 상/하위 호환성을 고려해야 한다.
상/하위 호환성에 대해 직관적으로 이해할 수 있는 그림
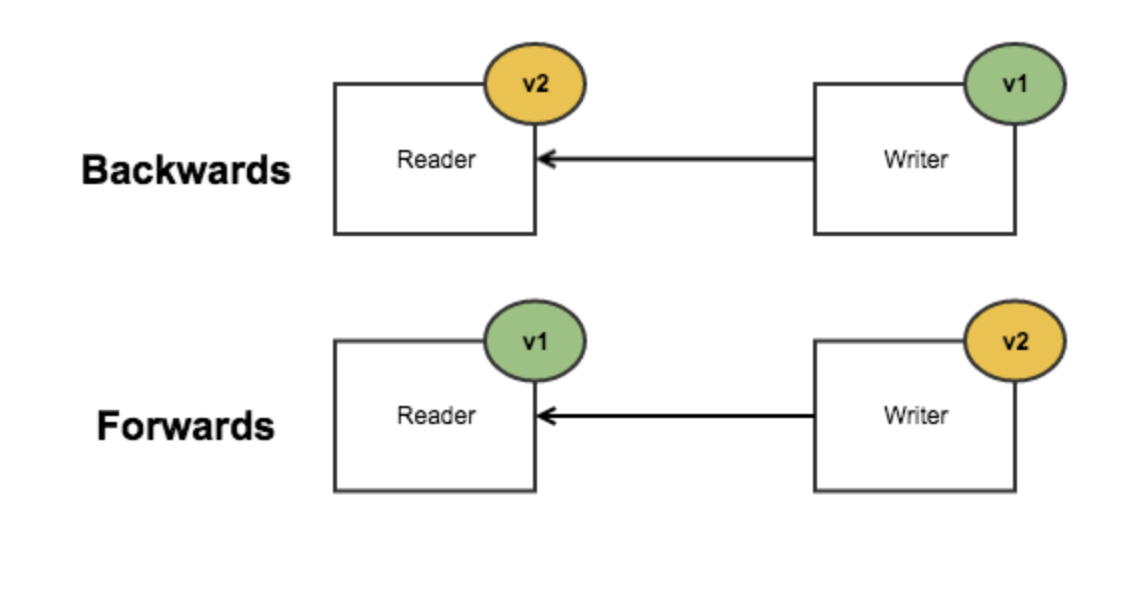
출저:https://stevenheidel.medium.com/backward-vs-forward-compatibility-9c03c3db15c9
- 하위 호환성 Backward Compatibility
- Backward compatibility means that readers with a newer schema can correctly parse data from writers an older schema.
- 새로운 코드는 예전의 코드가 기록한 데이터를 읽을수 있어야 한다. Newer code can read data that was written by older code.
- 새로운 코드는 예전 버전의 코드가 기록한 데이터 형식을 알기에 명시적으로 해당 형식을 다룰 수 있다.
- 상위 호환성 Forward Compatibilitty
- Forward compatibility means that readers with a older schema can correctly parse data from writers an newer schema.
- 예전 코드는 새로운 코드가 기록한 데이터를 읽을 수 있어야 한다. Older code can read data that was written by newer code.
- 더 어렵다. 예전버전의 코드가 새 버전의 코드에 의해 추가된것을 무시할수 있어야 하므로
데이터 부호화 형식 Formats for Encoding Data
- 프로그램은 (최소한) 두가지 형태로 표현된 데이터를 사용해 동작한다
- 메모리에 객체 Object, 구조체 Struct, 목록 List, 배열 Array, 해시 테이블 Hash table, 트리 Tree로 유지
- 이런 데이터 구조는 CPU에서 효율적으로 접근하고 조작할수 있게 최적화
- 데이터를 파일에 쓰거나 네트워크를 통해 전송하려면 JSON과 같은 바이트열의 형태로 부호화 Encoding 해야 한다.
- 포인터는 다른 프로세스가 이해할 수 없다.
- 그래서 이 일련의 바이트열은 보통 메모리에서 사용하는 데이터 구조와는 상당히 다르다.

- 위 그림과 같이 인메모리 표현에서 바이트 열로의 전환을
- 부호화 : Encoding
- 직렬화 : Serialize
- 마샬링: Marshaling
- 바이트 열에서 인메모리 표현으로 전환을
- 복호화 : Decoding
- 역직렬화 Deserialize
- 언마샬링 Unmarshaling
언어별 형식
프로그래밍 언어들은 인메모리 객체를 바이트열롤 부호화 하는 기능을 내장함. 예들은 아래와 같음
- Java
- java.io.Serializable
- Ruby
- Marshal
- Python
- Pickle
- Java의 써드파티 라이브러리
- Kryo
- 프로그래밍 언어에 내장된 부호화 라이브러리는 최소한의 추가 코드만 쓰면 되서 편리하지만 문제점도 많음
- 다른 언어에서 읽기가 어렵기 때문에 프로그래밍 언어가 고정되며 다른 시스템과 통합시 방해가 된다.
- 복호화 Deserialize 과정이 임의의 클래스를 인스턴스화 할수 있어야 하는데, 보안상 문제가 될수도 있다.
- 빠른 부호화를 위해 상/하위 호환성의 불편한 문제를 뒷전으로 하기도.
- 부호화, 복호화에 소요되는 CPU시간이나 부호화된 구조체의 크기같은 효율성도 뒷전으로 하기도 한다.
자바 내장 직렬화는 그닥 성능이 좋치 않은데 아래와 같다.

직렬화 소요시간

An Introduction and Comparison of Several Common Java Serialization Frameworks
This article compares open-source serialization frameworks in the industry by the universality, usability, scalability, performance, and supports for Java data types and syntax.
www.alibabacloud.com
JSON과 XML, 이진 변형 Binary Variants
JSON이 XML 대비 단순하고, 웹 브라우저에 내장된 지원 때문에 인기가 더 많다. 그리고 CSV도 있다.
- 위 문장과 관련하여 아래 문서는 JSON VS XML VS CSV
- 각각의 장단점을 비교한 문서 아래 참조
- 일반적으로 JSON은 현재까지 최고의 데이터 교환 형식이다. 가볍고 컴팩트하며 다목적이다. CSV는 엄청난 양의 데이터를 전송하고 대역폭이 문제인 경우에만 사용해야 한다. 오늘날 XML은 문서 마크업에 더 적합하기 때문에 데이터 교환. 형식으로 사용되어서는 안된다.
https://myhalo.com.sg/repair-quote/
- XML,CSV에서는 수와 숫자 digit로 구성된 문자열을 구분할 수 없다.
- 2^53을 넘어가면 부동소수점 문제가 발생한다.
- twitter는 이 문제를 해결하기 위해 64bit 숫자를 사용한다.
- JSON과 XML은 사람이 읽을수 있는 유니코드 문자열을 잘 지원한다. 그러나 이진 문자열을 지원하지 않는다.
- 이진 문자열은 유용하다. 그래서 이진 데이터를 Base64를 사용해 텍스트로 부호화 Encoding해 이 제한을 피한다.
- 그리고 값이 Base64로 부호화 되었다는 사실을 스키마를 사용해 표시
- 그리고 데이터 크기가 33% 증가
- CSV는 스키마가 없어서 각 로우의 컬럼의 의미를 정의하는 작업은 앱이 해야 한다.
이진 부호화 Binary encoding
작은 데이터셋이라면 무시할 수 있지만 "테라바이트 정도가 되면 데이터 타입의 선택이 큰 영향을 미친다"
- 데이터 공간은 이진 형식 < JSON, XML
- 이진 부호화의 예제로 쓸 JSON
- 스키마를 지정하지 않기 때문에 데이터 안에 모든 객체의 필드 이름을 포함해야 한다.
- 이 경우 userName, favoriteNumber, interests 라는 string을 포함해야 한다.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
메세지 팩 Message Pack
- JSON 용 이진 부호화 형식
- 위의 JSON을 Message Pack으로 Encoding해서 얻은 Byte Sequence이다.
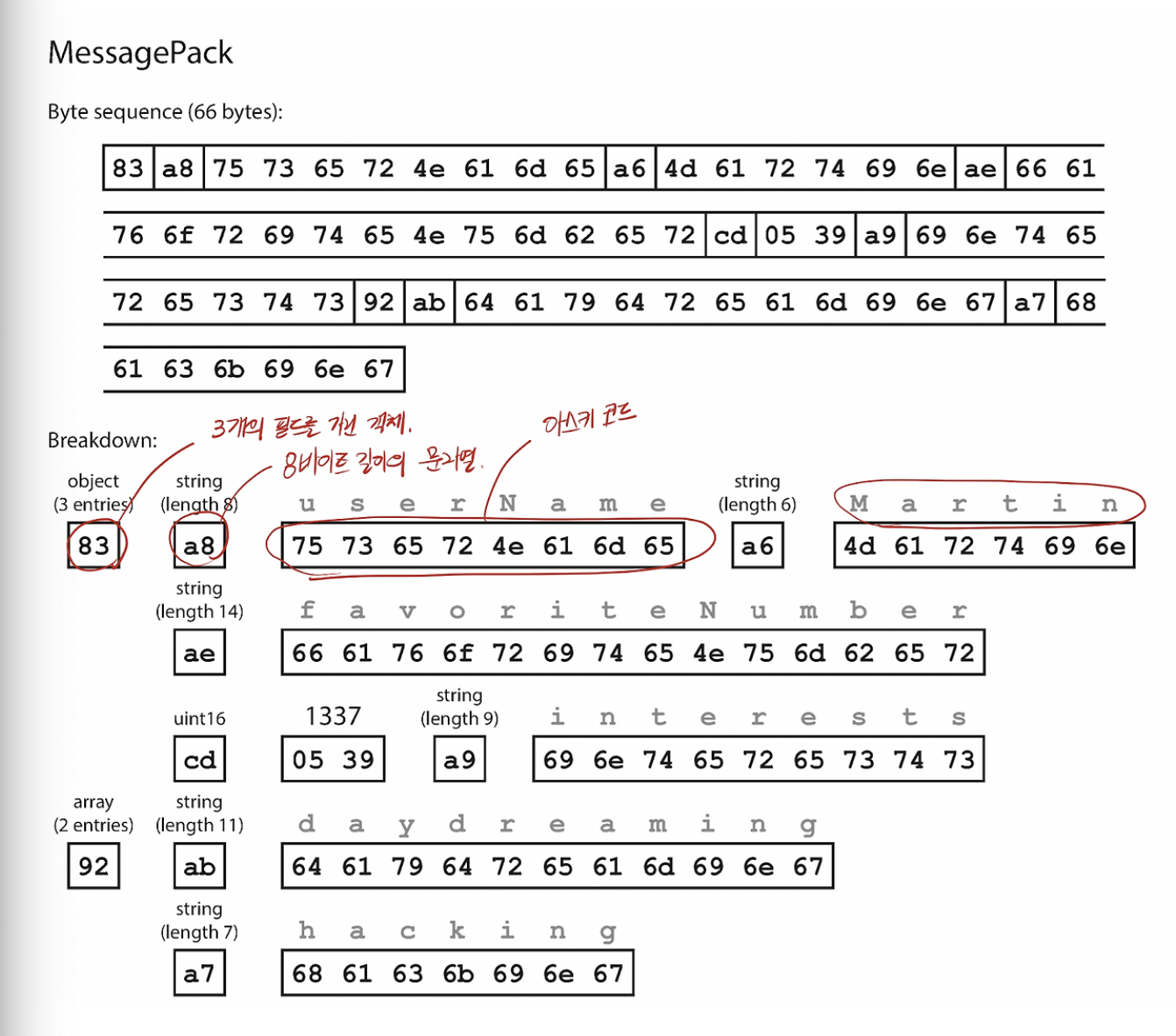
참조:https://github.com/msgpack/msgpack/blob/master/spec.md#overview
msgpack/spec.md at master · msgpack/msgpack
MessagePack is an extremely efficient object serialization library. It's like JSON, but very fast and small. - msgpack/msgpack
github.com
스리프트와 프로토콜 버퍼 Thrift and Protocol Buffers
아파치 스리프트 Apache Thrift, 프로토콜 버퍼 Protocol Buffers(protobuf)
둘다 부호화 할 데이터를 위한 스키마가 필요하다.다시,아래를 부호화 Encoding하기 위해서는
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}- 스리프트
- 스리프트 인터페이스 정의 언어
- IDL interface definition language로 스키마를 기술해야 한다.
struct Person{
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}- 프로토콜 버퍼
- 스리프트와 매우 비슷함
message Person {
required string user_name =1;
optional int64 favorite_number =2;
repeated string interests =3;
}
위의 두 정의를 이용해 코드를 생성하는 도구를 가지고 다양한 프로그래밍 언어로 스키마를 구현한 클래스를 생성 어플리케이션은 생성된 코드를 호출해 스키마의 레코드를 부호화, 복호화 할수 있다.
- 스리프트 바이너리 프로토콜 BinaryProtocol
- 아래와 같으며 59바이트
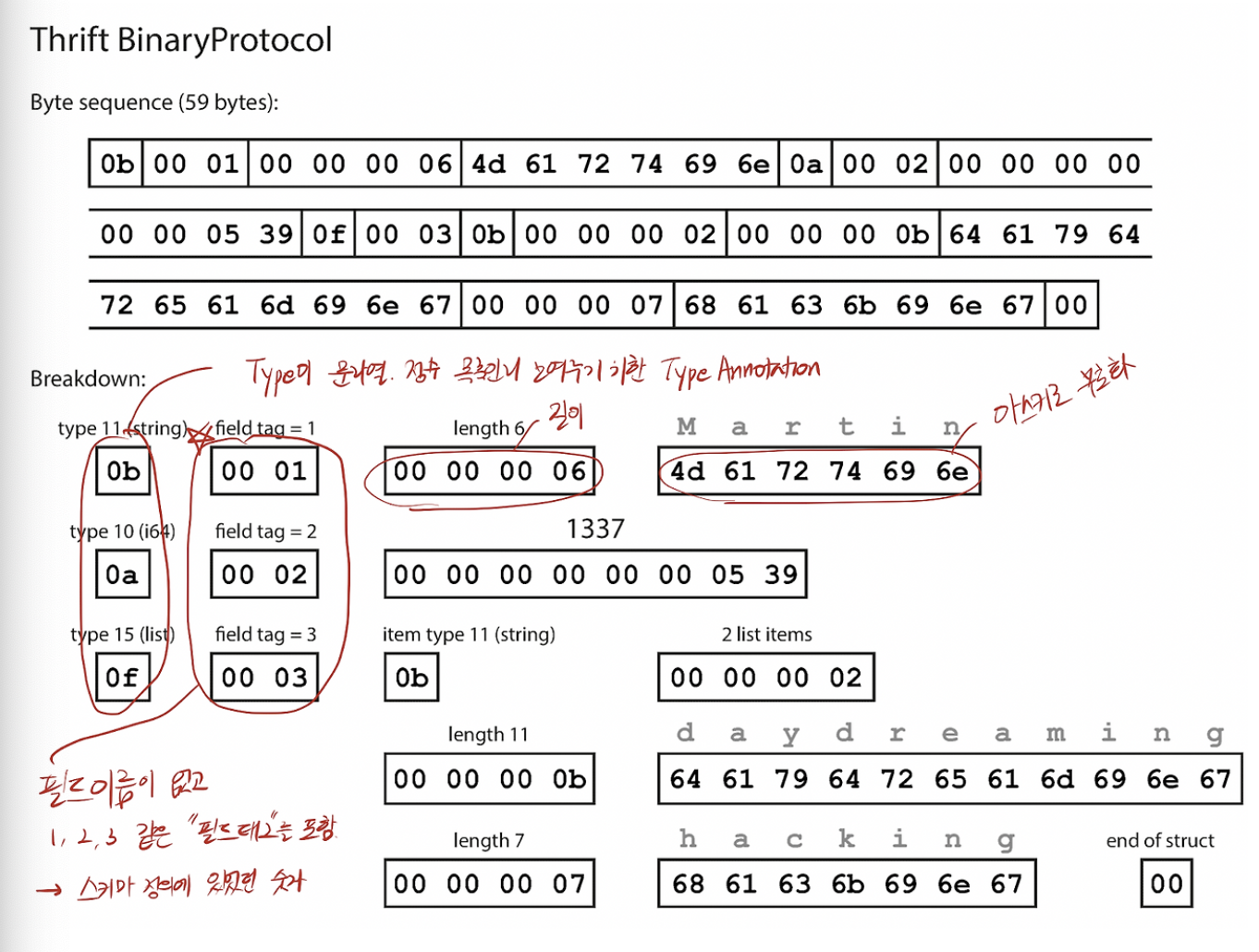
- 스리프트 컴팩트 프로토콜 CompactProtocol
- 아래와 같으며 34바이트
- 필드 타입과 태그 숫자를 단일 바이트로 줄임 그리고 가변 길이 정수 variable-length integer를 사용해서 부호화
- 숫자 1337도 2바이트로 부호화 (큰 수는 더 많은 바이트로)

- 프로토콜 버퍼
- 컴팩트 프로토콜과 비슷하고 33바이트

- 아래를 다시 보면 required와 optional이 명시되어 있다.
- 부호화하는 방법에는 차이가 없으나 required를 사용하면 필드가 설정되지 않은 경우를 실행시에 확인할수 있다고함.
struct Person{
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}https://protobuf.dev/getting-started/pythontutorial/
Protocol Buffer Basics: Python
A basic Python programmers introduction to working with protocol buffers.
protobuf.dev

- 다운로드 받은 프로토콜 버퍼 컴파일러로 아래와 같이 실행하면 addressbook_pb2.py가 생성된다.
- 이는 메세지를 읽고 쓰는데 필요한 Python 클래스이다.

필드 태그와 스키마 발전 Datatypes and schema evolution
스키마는 필연적으로 시간이 지남에 따라 변하고 이를 Schema Evolution 스키마 발전 이라고 부른다.
- 부호화 된 레코드는 부호화된 필드의 연결이고
- 각필드는 태그 숫자를 식별하며 데이터 타입을 주석으로 단다.
- 필드 값을 설정하지 않으면 부호화 레코드에서 생략한다.
- 필드 태그가 없으면 기존의 모든 부호화된 데이터를 인식 불가능 할 수 있기 때문에 변경 불가능하다.
- 태그 번호를 추가하는 것으로 스키마에 새로운 필드를 추가할수 있는데
- 예전 코드는 v1은 (새로운 태그 번호 추가에 대해 알지 못함)
- 새로운 코드 v2로 기록한 데이터를 읽으려고 할때(v1 코드가 모르는 태그 번호를 가진 필드가 있음)
- 해당 필드를 무시한다. 즉, 상위 호환성 Forward Compatibility가. 유지된다.
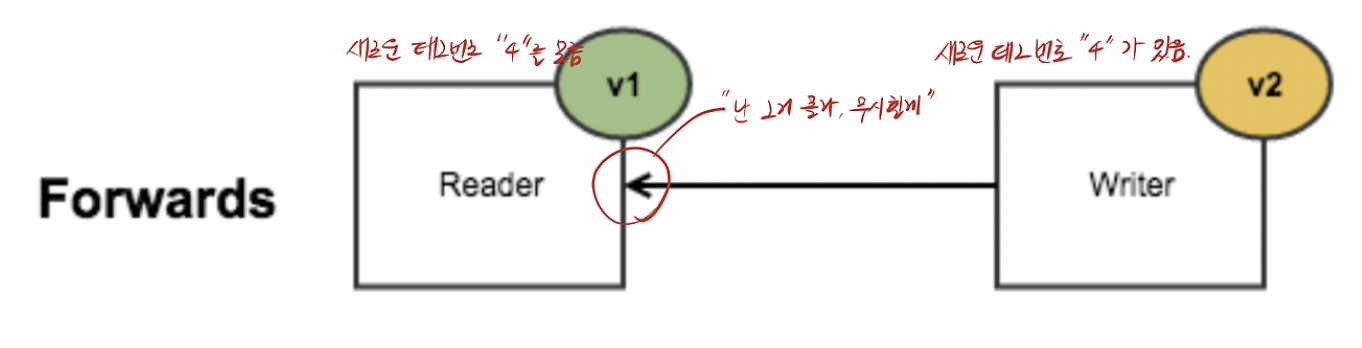
- 각 필드 태그 번호가 있는 동안에는 같은 의미를 유지하기에 새로운 코드도 항상 예전 데이터를 읽을 수 있다.
- 즉, 하위 호환성 Backward Compatibility가 유지된다.

- 하지만 새로운 필드를 추가했을때 required로 하면 예전 코드로 기록한 데이터에는 이 필드가 없다. 그래서 새로운 코드가 예전 코드로 기록한 데이터를 읽는 작업은 실패한다.
- 그러므로 호환성을 위해서는 스키마의 초기 배포후에 추가되는 모든 필드는 optional로 하거나 기본값을 가져야 한다.
데이터 타입과 스키마 발전 Datatypes and schema evolution
- 필드의 데이터 타입을변경하는건 가능하지만. 정확하지 않거나 내용이 잘릴 위험이 있다.
- 32비트 정수를 64비트로 바꾸는 경우(새 코드는 64비트로 읽으려고 하는가?)
Perser가 누락된 비트를 0으로 채울수 있기 때문에 새로운 코드는 예전 코드가 기록한 데이터를 쉽게 읽을수 있다. - 예전 코드가 기록한 데이터에 누락된 부분을 0으로 채우기 때문이다.
- 새로운 코드가 기록한 데이터를 예전 코드가 읽는경우
- 값을 유지하기 위해 32비트 변수를 계속 사용한다.
- 복호화된 64비트 값은 32비트에 맞지 않기 때문에 잘린다.
- 프로토콜 버퍼에는 "목록"이나 "배열 데이터타입"이 없다
- 필드에 repeated가 있다 repeated 필드의 부호화는 레코드에 "단순히 동일한 필드 태그가 여러번 나타난다."

- optional 필드를 repeated 필드고 변경해도 문제가 없다.
- 0이나 1개의 엘리먼트가 있는 목록으로 보게 되고
- 새로운 데이터를 읽는 예전 코드는 "목록의 마지막 엘리먼트만 보게 된다."
아브로(Avro)의 스키마
쓰기 스키마와 읽기 스키마
- 쓰기 스키마 : 파일/데이터베이스/네트워크로 보내기 위해 직렬화하기 원하는 데이터의 스키마
- 읽기 스키마 : 파일/데이터베이스/네트워크에서 읽기 위해 역직렬화되기 원하는 데이터의 스키마
아브로의 핵심 아이디어는
쓰기 스키마와 읽기 스키마가 동일하지 않아도 되며, 단지 호환 가능하면 된다.
데이터를 읽을 때(=역직렬화), 아브로 라이브러리가 두 스키마를 보고 쓰기 스키마에서 읽기 스키마로 데이터를 변환해 차이를 해소한다. 어떻게 변환하는지 살펴보자.
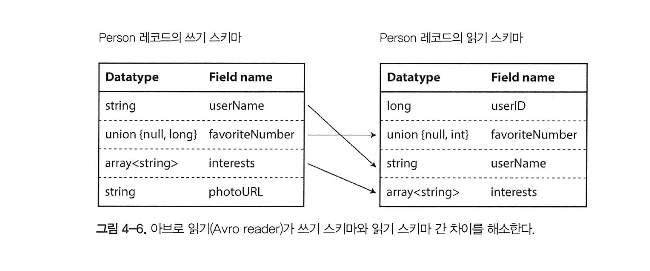
스키마 해석에서는 이름으로 필드를 일치하므로, 순서는 상관없다.
- 읽기 스키마에는 없고 쓰기 스키마에만 있는 경우 필드를 무시한다
- 읽기 스키마에 필요하지만, 쓰기 스키마에 없는 경우, 읽기 스키마의 기본값으로 채운다.
스키마 발전 규칙
필드의 추가/삭제
아브로에서 상위/하위 호환성은 다음과 같다.
- 상위 호환성 : 새로운 버전의 쓰기 스키마와, 예전 버전의 읽기 스키마를 가질수 있다.
- 하위 호환성: 새로운 버전의 읽기 스키마와, 예전 버전의 쓰기 스키마를 가질수 있다.
호환성을 유지하기 위해서는 기본값이 있는 필드만 추가/삭제할 수 있다.
예전 스키마를 읽을때 이전에 없던 추가된 필드는 기본값으로 채워지게 되면서 호환성이 유지된다.
기본값이 없다면 어떻게 될까?
- 기본값이 없는 필드를 추가 → new 읽기가 old 읽기를 읽을 수 없음 (하위 호환성 X)
- 기본값이 없는 필드를 삭제 → old 읽기가 new 읽기를 읽을 수 없음 (상위 호환성 X)
유니온 타입
아브로는 Thrift, Protocol Buffers처럼 optional, required 표시를 사용하지 않는다.
대신, 유니온 타입 과 기본값을 사용한다.
아브로에서는 필드에 널(null)을 허용하기 위해 유니온 타입을 사용해야 한다.
union { null, long, string } field;
예를 들어 이는 filed 수나 문자열 또는 널일수 있다는 의미이다.
즉, 필드가 유니온 엘리먼트 중 하나인 경우에만 기본값으로 널을 사용할 수 있다.
(* 이 방식이 복잡해 보이지만 널일 수 있는것이 명확해서 버그를 막는데 도움이 된다.)
그리고 유니온 타입에 엘리먼트를 추가하는 것은 하위 호환성은 있지만 상위 호환성은 없다.
(새 코드에서는 예전 엘리먼트를 모두 갖고 있지만, 예전 코드에서는 새 엘리먼트가 없기 때문)
필드의 타입/이름 변경
아브로에서는 필드의 데이터 타입 과 이름에 대한 변경이 가능하다.
하지만 이름의 변경은 하위 호환성이 있지만, 상위 호환성이 없다.
- 상위 호환성 : 예전 코드는 새 데이터를 읽을 수 없다 (예전 코드에는 별칭이 없기 때문)
- 하위 호환성 : 새 코드는 예전 데이터를 읽을 수 있다 (새 코드에서 별칭에 예전 쓰기 이름을 매치)
그러면 쓰기 스키마는 무엇인가?
위에서 읽기를 할때 쓰기 스키마와 읽기 스키마 간의 차이를 해소한다고했다.
그렇다면, 읽는 입장에서는 어떻게 쓰기 스키마를 알수 있을까?
모든 레코드에 전체 스키마를 포함할 수 는 없는데, 그럼 케바케가 된다.
- 대용량 파일 → 파일의 시작 부분에 한 번만 쓰기 스키마 포함
- 데이터베이스 → 레코드의 시작 부분에 스키마의 버전 번호 포함
- 네트워크 → 스키마 버전 합의 후 사용
스키마의 버전을 번호로 사용하면, 호환성 체크를 하기에 편리하고 유용하다.
동적 생성 스키마
프로토콜 버퍼와 스리프트와 달리, 아브로에는 스키마의 태그 번호가 포함돼 있지 않다.
이는 아브로의 장점이 되는데, 스키마가 변경될때 마다 칼럼 이름과 필드 태그를 매핑할 필요가 없기 때문이다.
아브로는 필드 이름으로 식별하기 때문에 매치가 가능해진다.
스키마의 장점
그동안 살펴본 스리프트, 프로토콜 버퍼, 아브로는 "스키마"를 통해 이진 부호화 형식을 표현한다.
이 스키마는 XML/JSON의 스키마보다 훨씬 간단하면서 더 자세한 유효성 검사 규칙을 지원한다.
이런 스키마를 이용한 방식은 1984년 처음으로 표준화된 스키마 정의 언어인 ANS.1과 공통점이 많다.
스리프트, 프로토콜 버퍼와 유사하게 태그 번호를 사용해 스키마 변경을 제공한다.
ODBC / JDBC API 같이 독자적으로 이진 부호화를 구현하기도 한다.
질의를 데이터베이스로 보내고 응답을 받을 수 있는 네트워크 프로토콜이 있고,
이 프로토콜로부터 응답을 인메모리 데이터 구조로 복화하나는 드라이버를 제공하는것이다.
JDBC는 JAVA에서 DB에 접속하게 해주는 JAVA API입니다.
ODBC는 마이크로소프트사에 의해 만들어진 데이터베이스에 접근하기 위한 소프트웨어의 표준 규격으로,
프로그램 내에 ODBC 문법을 사용하면 여러 종류의 데이터베이스에 접근할 수 있습니다.
JSON, XML, CSV 같은 Human-readable한 텍스트 타입과 비교 했을때 이진 부호화의 장점을 정리하면 다음과 같다.
- 크기가 작다
- 스키마 버전 관리가 쉽다
- 스키마 변경에 대한 호환성 확인
- 자동 코드 생성 가능
스키마 리스(schemaless) 또는 읽기 스키마(schema-on-read) JSON 처럼 동일하게 유연성을 제공할 수 있는 형태로 발전했기 때문에 좋다는 의미다.
'0️⃣Algorithm&자료구조&codingTest > Book&Study' 카테고리의 다른 글
| [데이터중심 애플리케이션 설계] - 6장 파티셔닝 (0) | 2026.01.21 |
|---|---|
| [데이터중심 애플리케이션 설계] - 5장 복제 (1) | 2026.01.21 |
| [데이터중심 애플리케이션 설계] - 3장 저장소와 검색 (1) | 2026.01.18 |
| [데이터 중심 애플리케이션 설계] - 2장 데이터 모델과 질의 언어 (1) | 2026.01.13 |
| [데이터 중심 애플리케이션 설계] - 1장. 신뢰할수 있고 확장가능하며 유지보수 하기 쉬운 어플리케이션 (0) | 2026.01.11 |



