분산 시스템을 공부하다 보면 반드시 마주치게 되는 개념이 있다. 바로 Quorum(쿼럼)이란 단어다. 오늘은 Quorum이 무엇인지, 왜 필요한지, 그리고 Apache Kafka에서 어떻게 활용되는지 깊이 있게 알아보자.
Quorum이란 무엇인가?
Quorum(쿼럼)이란 우리말로 "정속수"를 의미한다. 표준 국어대사전에서는 정속수를 "합의체가 의사를 진행하고 결정하는 데에 필요한 최소한의 출석 인원"이라고 정의한다.
분산 시스템에서 Quorum은 특정 작업을 수행하기 위해 필요한 최소한의 노드 합의 수를 의미한다.즉, 의사결정에 필요한 최소 참여자 수라고 할 수 있다.
Quorum의 핵심 개념
분산 시스템에서 가장 많이 사용되는 것은 Majority Quorum(과반수 쿼럼)입니다.
n개의 노드가 있을때, n/2보다 큰 수의 노드가 동의해야 작업이 진행되는 방식이다.
예를 들어:
- 3개 노드: 최소 2개의 동의 필요
- 5개 노드: 최소 3개의 동의 필요
- 7개 노드: 최소 4개의 동의 필요

Quorum이 필요한가?
1.Split Brain 문제해결
분산 시스템에서 가장 치명적인 문제 중 하나가 Split Brain(스플릿. 브레인) 현상이다.이는 클러스터에서 둘 이상의 노드 그룹이 서로 독립적으로 I/O 요청을 처리하면서 충돌이 발생하는 상황을 말한다.
Split Brain 시나리오
하나의 Primary 노드에 4대의 Secondary 노드가 연결되어 있다고 가정해보자.
Primary
├── Secondary 1
├── Secondary 2
├── Secondary 3 (네트워크 단절)
└── Secondary 4 (네트워크 단절)
네트워크 문제로 Secondary 3,4 가 고립됬다면,
- Secondary 3, 4는 Primary가 죽었다고 판단
- 둘중 하나를 새로운 Primary로 승격
- 실제로는 원래 Primary가 정상 작동중
- 결과: 두 개의 Primary가 존재하며 데이터 오염 발생
Quorum을 통한 해결
"데이터를 쓰기 위해서는 최소 3대의 노드로부터 동의를 얻어야 한다"는 Quorum 규칙을 적용하면
- Secondary 3, 4는 정족수를 만족하지 못함
- 데이터 쓰기 작업 불가
- 데이터 오염 방지
데이터 일관성 보장
Quorum 모델은 두가지 핵심 규칙을 통해 데이터 일관성을 보장한다.
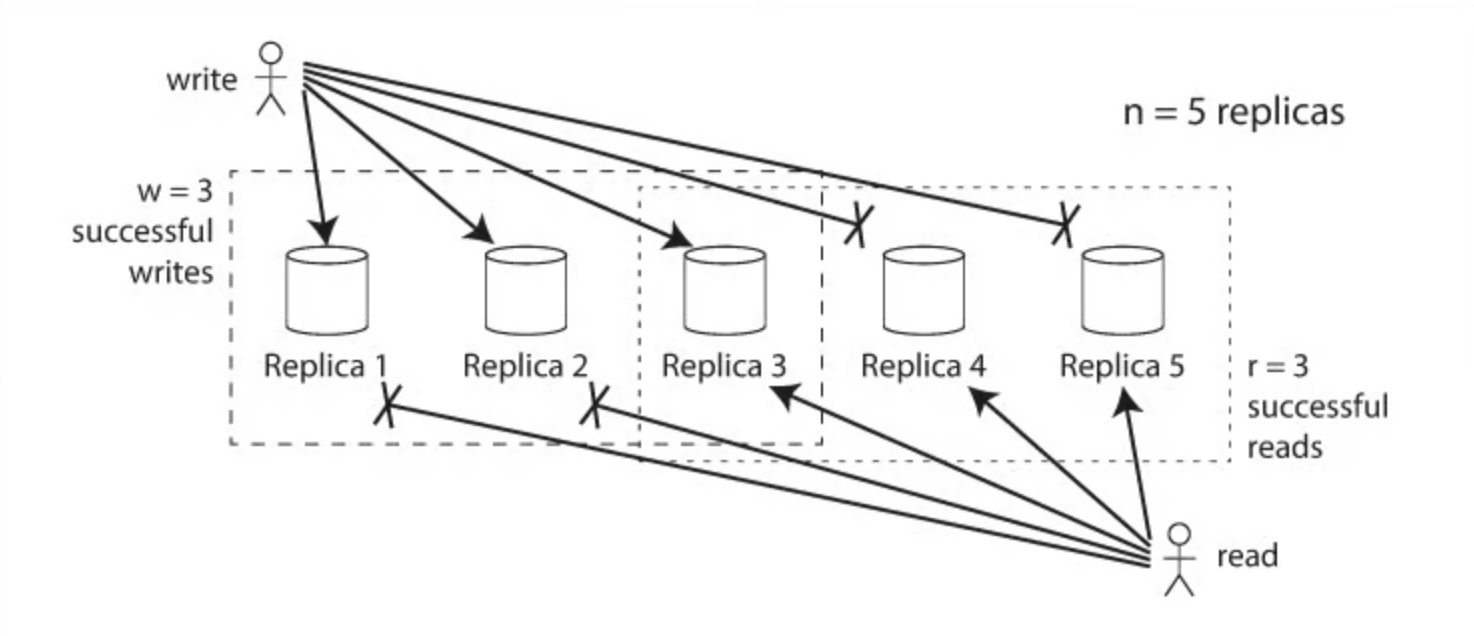
규칙 1: Read Set과 Write Set의 중첩
Vr (Read Set) + Vw (Write Set) > V (Total Nodes)
Read를 수행하는 노드들과 Write를 수행하는 노드들이 반드시 최소 하나 이상 겹쳐야 한다.
이를 통해
- 동일한 데이터 항목이 두 트랜잭션에 의해 동시에 읽히고 쓰이는 것을 방지
- Read Quorum이 최신 버전의 데이터를 포함함을 보장
예시 (총 3개 노드):
✅ Vw=2, Vr=2 → 2+2=4 > 3 (중첩 보장)
❌ Vw=1, Vr=1 → 1+1=2 < 3 (중첩 보장 안 됨)
규칙 2: Write Set 간의 중첩
Vw > V/2
Write 작업에 참여하는 노드 수가 전체 노드의 과반수를 초과해야 합니다.
이를 통해:
- 동일한 데이터에 대한 두 Write 작업이 동시에 발생하는 것을 방지
- 모든 Write 작업이 이전 Write 작업을 인지함을 보장
예시 (총 5개 노드):
- 5/2 = 2.5, 따라서 Vw ≥ 3
- 첫번째 Write: 노드 1,2,3
- 두번째 Write: 노드 2,4,5
- 노드 2가 중첩되어 순차성 보장

Kafka에서의 Quorum: KRaft모드
Apache Kafka는 3.0 버전부터 KRaft(Kafka Raft)모드를 도입하여 ZooKeeper의존성을 제거하고 자체 Quorum 메커니즘을 구현했다
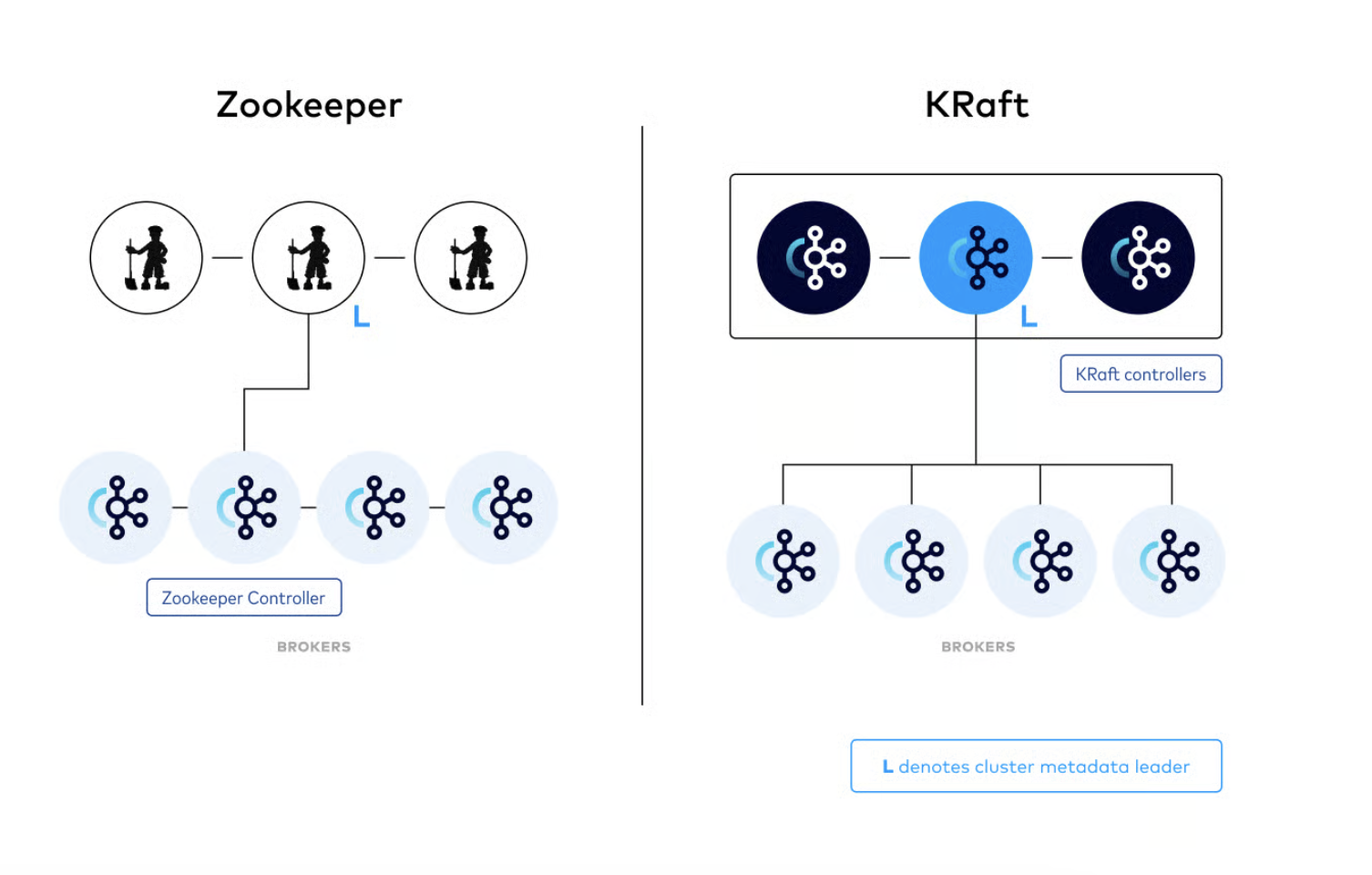
ZooKeeper 모드 VS KRaft모드
ZooKeeper모드의 한계
1. 성능 문제
- 모든 토픽/파티션 메타데이터를 ZooKeeper에서 읽어야 함
- 메타데이터 업데이트가 ZooKeeper에선 동기, 브로커에서는 비동기로 발생
- 메타데이터 불일치 가능성
- 컨트롤러 재시작 시 모든 메타데이터를 ZooKeeper에서 재로딩 (대규모 클러스터에서 병목)
- 파티션 리미트 약 200,000개
2. 운영 복잡도
- Kafka와 ZooKeeper는 완전히 다른 애플리케이션
- 별도의 설정 파일, 환경 변수, 서비스 데몬 관리 필요
- 독립적인 버전 업글레이드 및 릴리스 노트 확인 필요
3. 모니터링 부담
- 두 시스템의 서로 다른 메트릭 체계
- 별도의 모니터링 도구 및 알림 설정 필요
- 두 시스템 간 통신 문제 디버깅 어려움
KRaft모드의 장점
1. 아키텍처 단순화
- ZooKeeper 의존성 제거
- Kafka 단일 애플리케이션 내에서 메타데이터 관리
- Controller Quorum을 통한 자체 합의
2. 성능 향상
- 메모리 내 메타데이터 캐시 유지
- 파티션 수 제한 대폭 완화(200,000개 → 수백만 개)
- 컨트롤러 장애 복구 시간 대폭 단축
3. 운영 효율성
- 하나의 시스템만 관리
- 단일 모니터링 체계
- 간소화된 배포 및 업그레이드

KRaft의 Quorum 동작 방식
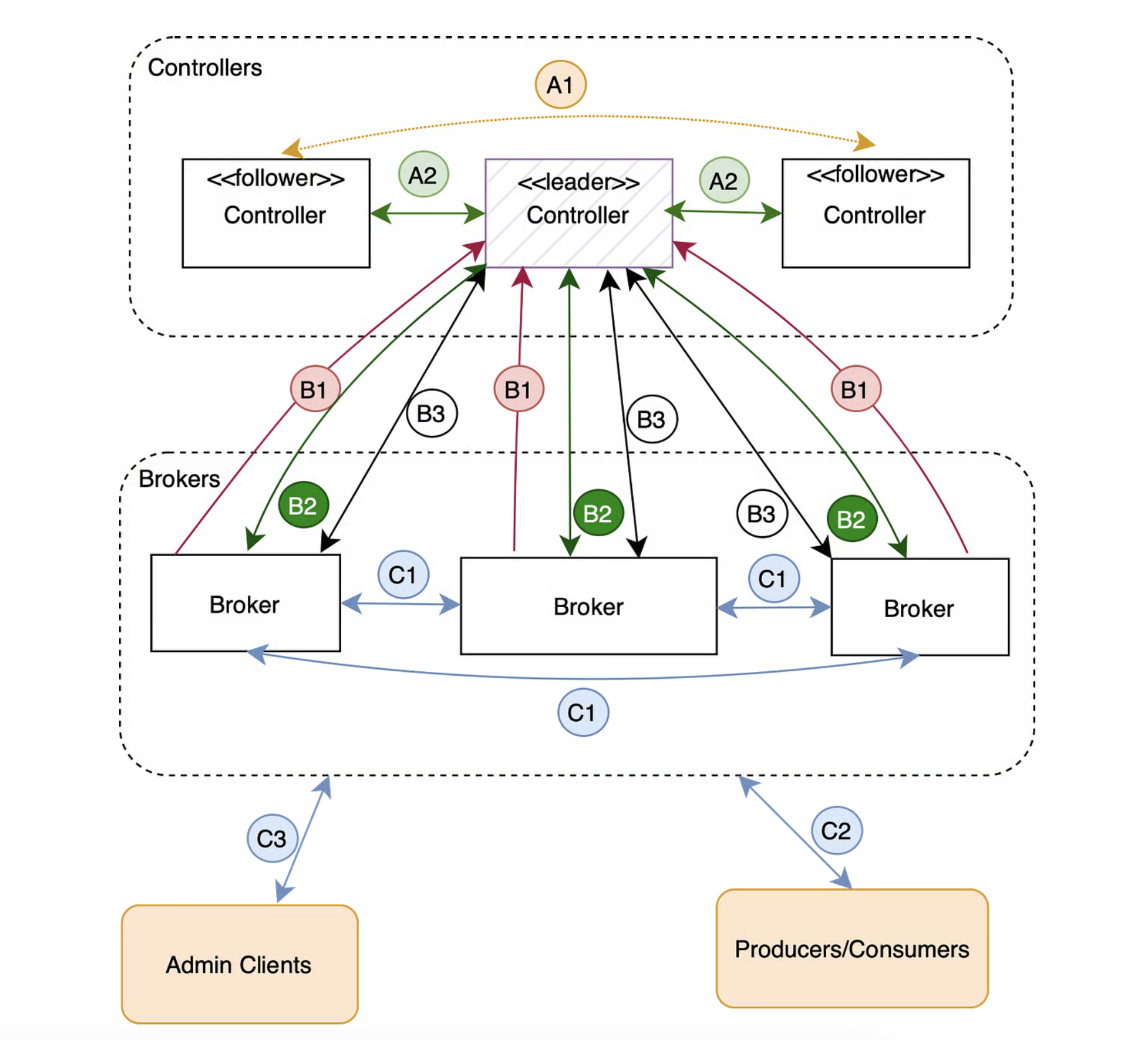
1. Controller Quorum 구성
KRaft 모드에서는 Controller Quorum이라는 컨트롤러 노드 그룹이 존재한다.
Controller Quorum (3대 권장)
├── Controller 1 (Active Leader) ✅
├── Controller 2 (Standby)
└── Controller 3 (Standby)
구성 원칙:
- 반드시 홀수로 구성 (3대 또는 5대 권장)
- 3대 구성: 1대 장애 허용
- 5대 구성: 2대 장애 허용
2. Raft 합의 알고리즘
KRaft는 Raft 합의 알고리즘을 기반으로 동작한다.
핵심 RPC:
- Vote: 리더 선출을 위한 투표
- BeginQuorumEpoch: 새로운 쿼럼 시작 알림
- EndQuorumEpoch: 쿼럼 종료 알림
- Fetch: 메타데이터 가져오기
리더 선출 과정:
1. 컨트롤러 1 장애 발생
↓
2. 컨트롤러 2, 3이 타임아웃 감지
↓
3. 후보자(Candidate)가 자신에게 투표
↓
4. 다른 컨트롤러들에게 투표 요청
↓
5. 과반수 표를 얻은 후보자가 새로운 리더로 선출
↓
6. BeginQuorumEpoch로 새 리더 알림
3. 메타데이터 관리
KRaft 모드에서는 @metadata 라는 특별한 내부 토픽을 사용하여 클러스터 메타데이터를 관리한다.
__cluster_metadata-0/
├── 00000000000000000000.log (메타데이터 로그)
└── quorum-state (쿼럼 상태)
메타데이터 복제 방식:
- Active 리더 컨트롤러가 메타데이터 변경 기록
- 로그를 Standby 컨트롤러들에게 복제
- 과반수 복제 완료 시 커밋
- 브로커들은 메타데이터를 구독하여 동기화
4. 장애 허용 메커니즘
Quorum 유지 중:
3대 구성에서 1대 장애
→ 2/3 과반수 유지
→ 정상 작동 계속
Quorum 상실:
3대 구성에서 2대 장애
→ 1/3 과반수 미달
→ 메시지 읽기/쓰기는 일정 시간 가능
→ 메타데이터 변경 작업 차단
(새 토픽 생성, 파티션 추가 등 불가)
KRaft 설정 예시
주요 설정 파라미터
# 노드 역할 (broker, controller, 또는 둘 다)
process.roles=broker,controller
# 노드 고유 ID
node.id=0
# Controller Quorum 투표자 목록
controller.quorum.voters=0@172.17.20.57:9093,1@172.17.20.58:9093,2@172.17.20.59:9093
# 리스너 설정(브로커와 컨트롤러 포트 분리)
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
# 외부 통지 주소
advertised.listeners=PLAINTEXT://172.17.20.57:9092
# 로그 디렉터리
log.dirs=/tmp/kraft-combined-logs
Cluster ID 생성 및 초기화
# 1. Cluster ID 생성
$ bin/kafka-storage.sh random-uuid
KLvENWRBTF6-9Mb33Y8zhA
# 2. Storage 초기화
$ bin/kafka-storage.sh format \
-t KLvENWRBTF6-9Mb33Y8zhA \
-c config/kraft/server.properties
# 3. KRaft 모드 시작
$ bin/kafka-server-start.sh config/kraft/server.properties
KRaft의 성능 개선

Confluent의 벤치마크 결과에 따르면

성능 향상 이유
1. 메모리 내 메타데이터 캐시
2. ZooKeeper 통신 오버헤드 제거
3. 효율적인 메타데이터 복제 메커니즘
4. 빠른 리더 선출 프로세스
Controller Quorum 운영
Quorum 증설
기존 3대 Controller Quorum을 5대로 확장하는 과정
# 1. 기존 컨트롤러 설정 파일 수정
controller.quorum.voters=0@host1:9093,1@host2:9093,2@host3:9093,3@host4:9093,4@host5:9093
# 2. 각 노드 순차적으로 재시작
# - 설정 파일 수정
# - quorum-state 파일 삭제
# - 노드 재시작
# 3. 새 노드 추가
# - process.roles에 controller 추가
# - listeners에 컨트롤러 프로토콜 추가
# - controller.quorum.voters 업데이트메타데이터 확인
# 메타데이터 셸 사용
$ bin/kafka-metadata-shell.sh \
--snapshot /tmp/kraft-combined-logs/__cluster_metadata-0/00000000000000000000.log
>> ls /
brokers local metadataQuorum topicIds topics
>> cd brokers/
>> ls
0 1 2
>> cat 0/registration
RegisterBrokerRecord(brokerId=0, ...)
실전 적용 가이드
1. 신규 클러스터 구성
권장 구성
프로덕션 환경:
- Controller Quorum: 3대 (작은 규모) ~ 5대 (대규모)
- 전용 Controller 노드 또는 Combined 모드 선택
개발/테스트 환경:
- Controller Quorum: 1대 또는 3대
- Combined 모드 (broker + controller)
2. ZooKeeper에서 마이그레이션
주의사항
- Kafka 3.3.0부터 KRaft 정식 지원
- Kafka 3.4.0부터 마이그레이션 도구 제공
- 마이그레이션 전 충분한 테스트 필수
- 백업 및 롤백 계획 수립
3. 모니터링 포인트
필수 메트릭
- kafka.controller:type=KafkaController,name=ActiveControllerCount
- kafka.controller:type=ControllerStats,name=LeaderElectionRateAndTimeMs
- kafka.server:type=KafkaServer,name=BrokerState
- kafka.log.remote:type=RemoteLogMetricsManager,name=RemoteLogMetadataCount
정리
Quorum의 핵심 가치
1. 데이터 일관성: Read/Write Set의 중첩을 통한 동시성 제어
2. 장애 허용: 과반수 원칙으로 부분 장애 극복
3. Split Brain 방지: 정족수 미달 시 작업 차단
Kafka KRaft의 혁신
1. 아키텍처 단순화: ZooKeeper 제거로 단일 시스템 관리
2. 성능 향상: 10배 이상의 복구 속도 및 파티션 수 증가
3. 운영 효율성: 통합된 모니터링 및 관리 체계
향후 전망
- Kafka 4.0부터 ZooKeeper 모드 deprecated 예정
- KRaft가 표준 운영 모드로 자리 잡을 전망
- 더욱 강화된 메타데이터 관리 기능 추가 예정
참고 자료
KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum - Apache Kafka - Apache Software Foundation
Current state: Accepted Discussion thread: here JIRA: KAFKA-9119 - 이슈 세부사항 가져오는 중... 상태 Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast). Currently, Kafka us
cwiki.apache.org
KRaft - Apache Kafka Without ZooKeeper
Apache Kafka Raft (KRaft) simplifies Kafka architecture by consolidating metadata into Kafka, removing the ZooKeeper dependency. Learn how it works, benefits, and what this means for Kafka's scalability.
developer.confluent.io
Apache Kafka의 새로운 협의 프로토콜인 KRaft에 대해(1)
devocean.sk.com
분산환경에서 Quorum(정족수)은 왜 필요할까 / Quorum이란 무엇인가
https://aws.amazon.com/ko/blogs/korea/amazon-aurora-under-the-hood-quorum-and-correlated-failure/ Amazon Aurora 내부 들여다보기 (1) – 쿼럼 및 상관 오류 해결 방법 | Amazon Web Services 이 글은 AWS Database Blog의 Aurora 집중 해부
2kindsofcs.tistory.com
분산 시스템의 핵심 개념인 Quorum과 Kafka의 진화한 아키텍처 KRaft에 대해 알아보았다. 이 개념들은 현대 데이터 인프라의 신뢰성과 확장성을 보장하는 핵심 기술이다. 여러분의 시스템에도 적용해보시기 바랍니다.
'🔥 Data Engineer > Kafka' 카테고리의 다른 글
| [Kafka] - 카프카 관리툴의 종류와 특징 비교 (1) | 2026.01.09 |
|---|---|
| [Kafka] - Kafka Connect (0) | 2026.01.09 |
| [Kafka] - 카프카 설치 및 초기세팅 (0) | 2026.01.08 |
| [Kafka] - Kafka MirrorMaker 2란? (0) | 2026.01.08 |
| [Kafka] - Apache Kafka 4.0: 아키텍처 및 주요 특징 (1) | 2026.01.08 |
