
들어가며
분산 시스템에서 데이터 복제(Replication)은 가용성과 내구성을 보장하는 핵심 메커니즘이다. Apache Kafka는 단일 클러스터 내에서 파티션 간 복제를 통해 데이터를 보호하지만, 여러 Kafka 클러스터 간의 데이터 복제가 필요한 경우에는 어떻게 해야 할까?
바로 이때 Apache Kafka MirrorMaker2(MM2)가 등장한다.
MirrorMaker 2는 Kaffka 2.4.0부터 도입된 차세대 크로스 클러스터 복제 도구로, Kafka Connect 프레임워크를 기반으로 완전히 재설계 되었다. 초기 버전인 MirrorMaker 1의 한계를 극복하고, 더욱 강력하고 유연한 지오-레플리케이션(Geo-Replication)기능을 제공한다.
1. MirrorMaker 2란 무엇인가?
정의
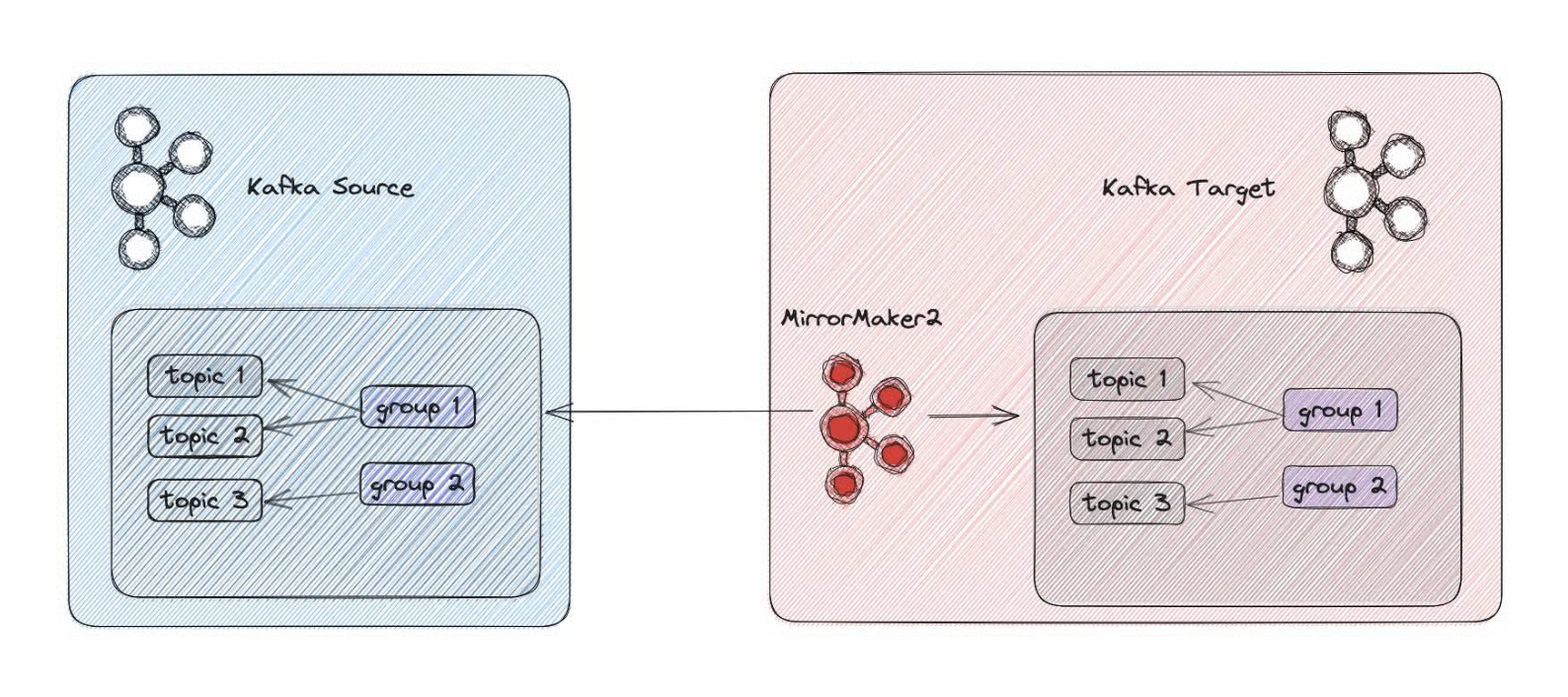
Apache Kafka MirrorMaker 2(MM2)는 서로 다른 Kafka 클러스터 간에 토픽, 메세지, 컨슈머 그룹 오프셋을 복제하는 도구다.
Kafka Connect 프레임워크 위에 구축되어 높은 안정성, 확장성, 그리고 복잡한 지오-레플리케이션 시나리오를 지원한다.
핵심 개념
MirrorMaker 2를 이해하기 위한 주요 용어:
- Source Cluster (소스 클러스터): 데이터가 복제되는 원본 클러스터
- Target/Sink Cluster (타겟 클러스터): 데이터가 복제되는 목적지 클러스터
- Mirror Flow (미러 플로우): 소스에서 타겟으로의 단방향 복제 흐름
- Remote Topic (원격 토픽): 타겟 클러스터에 생성된 복제본 토픽
- Active/Active: 양방향 복제로 두 클러스터 모두 활성 상태
- Active/Passive: 단방향 복제로 재해 복구용 대기 클러스터 운영
2. MirrorMaker 1 VS MirrorMaker 2: 무엇이 달라졌을까?
MirrorMaker 1의 한계
초기 버전인 MirrorMaker 1은 단순히 Kafka Consumer와 Producer 쌍으로 구성되어 소스 클러스터에서 읽어 타겟 클러스터로 쓰는 방식이었다. 하지만 다음과 같은 한계가 있다.
- ❌ 정적 설정: 동적으로 토픽 추가/변경 불가
- ❌ 오프셋 동기화 불가: 컨슈머 그룹 오프셋 복제 미지원
- ❌ 제한된 확장성: 대규모 클러스터에서 성능 문제
- ❌ 복잡한 토폴로지 지원 부족: 양방향 복제나 다중 클러스터 지원 부족
MirrorMaker 2의 주요 개선사항
MirrorMaker 2는 Kafka Connect를 기반으로 완전히 재설계되어 다음과 같은 혁신을 이뤘다.
✅ 동적 설정 변경 지원
- 런타임에 복제 토픽 추가/제거 가능
- 실시간 설정 업데이트
✅ 양방향(Bidirectional) 복제
- Active/Active 클러스터 패턴 지원
- 무한 루프 방지 메커니즘 내장
✅ 컨슈머 오프셋 동기화
- 장애 복구 시 정확한 오프셋에서 재시작
- 페일오버(Failover) 시나리오 완벽 지원
✅ 향상된 성능 및 확장성
- Kafka Connect 프레임워크의 병렬 처리
- 대규모 클러스터 환경 최적화
✅ 고급 기능
- 토픽 필터링 및 이름 변경(Renaming)
- 정규 표현식 기반 토픽 선택
- 엔드-투-엔드 메트릭 및 모니터링
3. MirrorMaker 2 아키텍쳐
3.1 핵심 컴포넌트
MirrorMaker 2는 Kafka Connect 기반으로 세 가지 특수 커넥터로 구성된다.
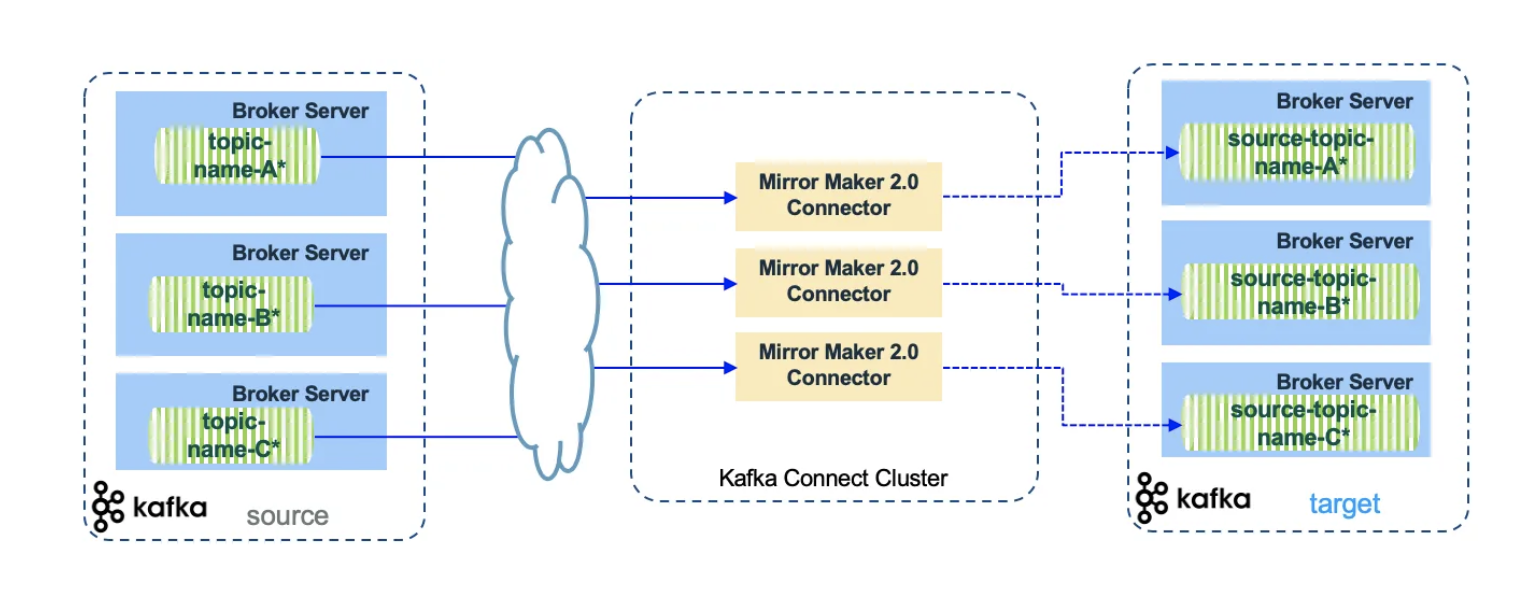
1. Mirror Source Connector
역할
- 소스 클러스터에서 타겟 클러스터로 레코드 복제
- 오프셋 동기화 활성화
- 토픽 메타데이터 복제
동작 방식
- Consumer: 소스 클러스터에서 메시지 읽기
- Producer: 타겟 클러스터로 메시지 쓰기
- 각 커넥터는 Consumer-Producer 쌍으로 동작
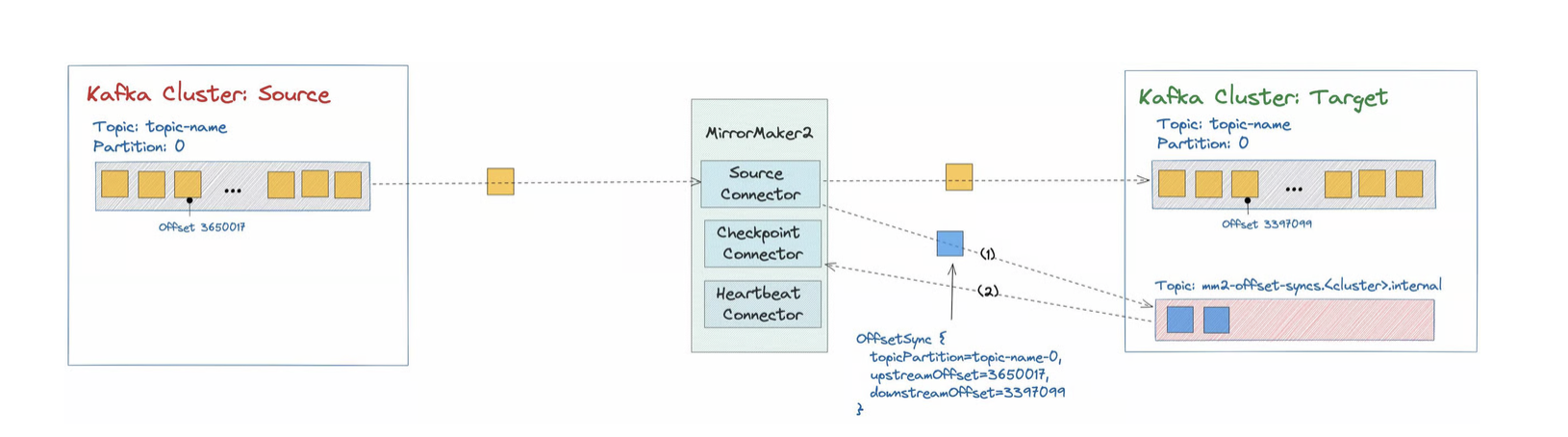
2. Mirror Checkpoint Connector
역할
- 컨슈머 그룹 오프셋 번역 및 동기화
- 체크포인트(Checkpoint) 발행
- 페일오버 시나리오 지원
주요 기능
- 소스 클러스터의 컨슈머 오프셋을 타겟 클러스터 오프셋으로 변환
- 클라이언트가 페일오버 시 정확한 위치에서 재개 가능
3. Mirror Heartbeat Connector
역할
- 복제 플로우의 헬스 체크
- 하트비트(Heartbeat) 메시지 발행
- 복제 토폴로지 디스커버리
모니터링
- 클러스터 간 연결 상태 확인
- 레플리케이션 지연(Replication Lag) 측정
- 클라이언트의 토폴로지 감지 지원
3.2 내부 토픽
MirrorMaker 2는 상태 추적을 위해 여러 내부 토픽을 생성한다.

4. MirrorMaker 2 주요 사용 사례
4.1 재해 복구(Disaster Recovery)
시나리오
- 주 클러스터에서 백업 클러스터로 지속적인 데이터 복제
- 주 클러스터 장애 시 백업 클러스터로 신속한 페일오버
장점
- 데이터 손실 최소화 (RPO: Recovery Point Objective 감소)
- 빠른 복구 시간 (RTO: Recovery Time Objective 감소)
- 컨슈머 오프셋 동기화로 정확한 재시작 지점 보장
아키텍처
Primary Cluster (Active) → Secondary Cluster (Passive)
↓
Application
4.2 데이터 격리(Data Isolation)
시나리오
- 민감한 데이터를 프라이빗 클러스터에 보관
- 공개 데이터만 퍼블릭 클러스터로 선택적 복제
구현
- 토픽 화이트리스트/블랙리스트 설정
- 정규 표현식으로 복제 대상 필터링
# 특정 토픽만 복제
topics = public.*
# 제외할 토픽 패턴
topics.exclude = .*sensitive.*
4.3 데이터 집계(Data Aggregation)
시나리오
- 여러 지역 클러스터의 데이터를 중앙 클러스터로 집계
- 분석, 리포팅, 머신러닝용 통합 데이터 뷰 제공
토폴로지
Region A Cluster ──┐
Region B Cluster ──┼─→ Central Analytics Cluster
Region C Cluster ──┘
4.4 데이터 마이그레이션(Data Migration)
시나리오
- 온프레미스에서 클라우드로 이전
- Kafka 버전 업그레이드
- 다른 Kafka 배포판으로 전환
프로세스
1. 기존 클러스터에서 신규 클러스터로 복제 시작
2. 애플리케이션을 점진적으로 신규 클러스터로 전환
3. 완전 전환 후 복제 중단
제로 다운타임 마이그레이션 가능
4.5 엣지 컴퓨팅(Edge Computing)
시나리오:
- 엣지 디바이스/로케이션에서 중앙 클러스터로 데이터 전송
- 저지연 처리와 중앙 분석의 균형
특징:
- 네트워크 지연 허용 (100ms 이상도 가능)
- 간헐적 연결 환경 지원
5. MirrorMaker 2 복제 규칙
MirrorMaker 2의 동작을 이해하기 위한 핵심 규칙들
규칙 1: 단방향 복제 (Unidirectional)
각 미러 플로우는 단방향이다.
Cluster A → Cluster B
규칙 2: 다중 토픽 복제
하나의 플로우가 여러 토픽을 복제할 수 있다.
topics = topic-1, topic-2, topic-3
# 또는 정규 표현식
topics = orders.*규칙 3: 일대일 토픽 매핑
각 소스 토픽은 정확히 하나의 원격 토픽으로 복제된다.
규칙 4: 자동 토픽 생성
타겟 클러스터에 토픽이 없으면 자동 생성된다..
규칙 5: 토픽 이름 변경 (기본값)
기본적으로 소스 클러스터 이름이 접두사로 추가된다.
topic-1 (sourceCluster) → sourceCluster.topic-1 (targetCluster)
규칙 6: 다중 플로우 지원
복잡한 토폴로지 구성 가능
Fan-out (분산)
Cluster A → Cluster B
Cluster A → Cluster C
Fan-in (집계)
Cluster A → Cluster C
Cluster B → Cluster C
Bidirectional (양방향)
Cluster A ⟷ Cluster B
규칙 7 & 8: 무한 루프 방지
타겟 클러스터 이름이 포함된 토픽은 해당 클러스터로 복제되지 않는다.
예시
# Cluster A에서 생성된 토픽
A.topic-1 (Cluster B) → Cluster A로 복제 안 됨 (무한 루프 방지)6. 배포 아키텍처 설계
6.1 배포 위치 Remote Consume, Local Produce
베스트 프랙티스
MirrorMaker 2는 타겟 클러스터와 같은 네트워크 영역에 배포하는궛이 권장됩니다.

이유
성능: Kafka Producer는 Consumer보다 지연에 민감함
- 로컬 네트워크에서 쓰기 작업 수행 → 안정성 향상
- 복제 지연 최소화
유연성: 네트워크 제약 없이 프로듀서 튜닝 가능
- 배치 크기(Batch Size) 최적화
- 압축(Compression) 설정 조정
- 로컬 네트워크에서 신뢰성 높은 튜닝
집계 시나리오: 다중 소스 클러스터 복제 시 유리
6.2 단일 VS 다중 배포
단일 배포(권자)
- 모든 토픽을 하나의 대형 MM2 인스턴스에서 처리
- 관리 포인트 최소화
- 대부분의 사용 사례에 적합
다중 배포
다음 경우에만 고려
사용 시나리오
복제 효율성: 토픽별로 다른 튜닝 파라미터 필요
- 메시지 크기가 크게 다름
- 압축 타입이 다름
장애 격리: 특정 애플리케이션 그룹 장애가 전체 복제에 영향 방지
주의사항
- 각 배포마다 고유한 내부 토픽 이름 필요
- 컨슈머 그룹 매핑 복잡도 증가
6.3 토픽생성: 수동 VS 자동
자동 생성(기본값)
- MM2가 자동으로 타겟 클러스터에 토픽 생성
- 간편하지만 일부 설정 미복제 가능성
수동 생성(권장)
이유
- min.insync.replicas 같은 중요 설정 보존
- 파티션 수, 복제 팩터 정확한 제어
- 프로덕션 환경에서 권장
도구
# Kafka CLI 사용
kafka-topics.sh --create \
--bootstrap-server target-cluster:9092 \
--topic sourceCluster.topic-1 \
--partitions 10 \
--replication-factor 3 \
--config min.insync.replicas=27. 설정 예시
기본 MirrorMaker 2 설정
# 클러스터 정의
clusters = source, target
source.bootstrap.servers = source-kafka:9092
target.bootstrap.servers = target-kafka:9092
# 복제 플로우 정의
source->target.enabled = true
# 복제할 토픽 선택 (정규 표현식)
source->target.topics = .*
# 제외할 토픽
source->target.topics.exclude = .*internal.*, .*checkpoint.*
# 컨슈머 그룹 필터
source->target.groups = .*
source->target.groups.exclude = console-consumer-.*
# 동기화 설정
sync.topic.configs.enabled = true
sync.topic.acls.enabled = false
# 성능 튜닝
tasks.max = 4
replication.factor = 3
Active/Active 설정 (양방향)
clusters = clusterA, clusterB
clusterA.bootstrap.servers = clusterA:9092
clusterB.bootstrap.servers = clusterB:9092
# 양방향 플로우
clusterA->clusterB.enabled = true
clusterB->clusterA.enabled = true
# 동일한 토픽 복제
clusterA->clusterB.topics = orders, inventory
clusterB->clusterA.topics = orders, inventory
# 오프셋 동기화
sync.group.offsets.enabled = true
sync.group.offsets.interval.seconds = 60
# 무한 루프 방지 (기본 활성화)
replication.policy.class = org.apache.kafka.connect.mirror.DefaultReplicationPolicy8. 모니터링 및 운영
주요 메트릭
복제 지연(Replication Lag)
record-lag-max
record-lag-avg
처리량(Throghput)
byte-rate
record-count
오프셋 동기화
checkpoint-latency-ms
offset-syncs-total
헬스 체크
하트비트 토픽 모니터링
kafka-console-consumer.sh \
--bootstrap-server target:9092 \
--topic heartbeats \
--from-beginning
내부 토픽 확인
# 오프셋 동기화 상태
kafka-console-consumer.sh \
--bootstrap-server target:9092 \
--topic mm2-offset-syncs.target.internal \
--formatter "org.apache.kafka.connect.mirror.formatters.OffsetSyncFormatter"9. 베스트 프랙티스
권장 사항
타겟 클러스터 근처 배포
- Remote consume, local produce 패턴 준수
수동 토픽 생성
- 중요 설정 값 보존
적절한 필터링
- 불필요한 토픽 복제 방지
- 내부 토픽 제외
모니터링 설정
- 복제 지연 알림 구성
- 하트비트 모니터링
오프셋 동기화 활성화
- 페일오버 시나리오 대비
점진적 배포
- 소규모 토픽으로 테스트
- 단계적 확장
피해야 할 사항
1.과도한 복제
- 모든 토픽 무분별한 복제 금지
2.네트워크 고려 부족
- 대역폭 및 지연 시간 확인 필수
3.설정 검증 생략
- 프로덕션 전 충분한 테스트
4.모니터링 부재
- 복제 상태 실시간 추적 필수
10. 문제 해결(Troubleshooting)
일반적인 문제
1. 복제 지연 증가
원인
- 네트워크 대역폭 부족
- 타겟 클러스터 성능 저하
- 배치 크기 튜닝 부족
해결
# Producer 배치 크기 증가
producer.batch.size = 32768
producer.linger.ms = 100
# 압축 활성화
producer.compression.type = snappy
# Task 수 증가
tasks.max = 8
2. 토픽 자동 생성 실패
원인
- 타겟 클러스터 권한 부족
- 자동 토픽 생성 비활성화
해결
- 수동으로 토픽 사전 생성
- ACL 권한 확인
3. 컨슈머 오프셋 동기화 안됨
원인
- Checkpoint Connector 비활성화
- 오프셋 토픽 누락
해결
# 오프셋 동기화 명시적 활성화
checkpoints.topic.replication.factor = 3
sync.group.offsets.enabled = true
emit.checkpoints.interval.seconds = 60
11. 마치며
Apache Kafka MirrorMaker 2는 Kafka 클러스터 간 데이터 복제를 위한 강력하고 유연한 솔루션이다.
Kafka Connect 기반의 현대적인 아키텍처로 재설계되어, 다음과 같은 핵심 가치를 제공한다.
주요 장점 요약
✨ 높은 안정성
- Kafka Connect의 검증된 프레임워크
- 자동 장애 복구 및 재시도
✨ 뛰어난 확장성
- 병렬 처리 및 분산 아키텍처
- 대규모 클러스터 환경 지원
✨ 유연한 토폴로지
- 양방향, 다중 클러스터, 복잡한 파이프라인
- 무한 루프 자동 방지
✨ 운영 편의성
- 동적 설정 변경
- 포괄적인 모니터링 메트릭
- 오프셋 자동 동기화
적용 시나리오
MirrorMaker 2는 다음과 같은 경우에 필수적입니다:
- 🔥 재해 복구(DR) 및 고가용성(HA) 구현
- 🌍 지리적으로 분산된 데이터 센터 운영
- 📊 다중 리전 데이터 집계 및 분석
- 🚀 제로 다운타임 클러스터 마이그레이션
- 🔒 데이터 격리 및 보안 요구사항
시작하기
MirrorMaker 2를 도입할 때는
- 사용 사례 명확화 - DR인지, 마이그레이션인지, 집계인지 결정
- 소규모 시작 - 중요하지 않은 토픽으로 테스트
- 모니터링 구축 - 복제 지연 및 상태 추적
- 점진적 확장 - 검증된 설정을 프로덕션으로 확대
MirrorMaker 2는 복잡한 멀티 클러스터 Kafka 환경을 성공적으로 운영하기 위한 필수 도구이다.
적절한 설계와 모니터링을 통해 안정적이고 효율적인 지오-레플리케이션을 구현할 수 있다.
참고 자료
- Apache Kafka MirrorMaker 2.0 (KIP-382)
- Demystifying Kafka MirrorMaker 2 - Red Hat
- Apache Kafka MirrorMaker 2 Theory - Instaclustr
- Kafka MirrorMaker: How to Replicate Data - Confluent
- MirrorMaker 2 Usages & Best Practices - GitHub
'🔥 Data Engineer > Kafka' 카테고리의 다른 글
| [Kafka] - 카프카 관리툴의 종류와 특징 비교 (1) | 2026.01.09 |
|---|---|
| [Kafka] - Kafka Connect (0) | 2026.01.09 |
| [Kafka] - 카프카 설치 및 초기세팅 (0) | 2026.01.08 |
| [Kafka] - Apache Kafka 4.0: 아키텍처 및 주요 특징 (1) | 2026.01.08 |
| [Kafka] - Quorum과 Kafka의 Quorum 동작방식 완벽가이드 (0) | 2026.01.08 |
