Spark UI - JupyterNotebook
Spark 데이터프레임을 500명의 학생을만들어 각각의 무작위로 6가지 과일중 하나를 배정하도록 하게하여서
복수 추출이 가능하게끔 만들어보았습니다.
Docker에서 Token을 생성하고 jypyter Notebook을 활용해서 Spark에서 어떤식으로 분산처리 되는 과정까지 함께 살펴보도록 하겠습니다. 추가적으로 Lazy Oparation과 Action에 대해서도 알아보겠습니다.
이전에 Docker설정을 해두어서 Spark Container를 하나 만들고 Jupyter Notebook Token을 만들어서 들어가줍니다.

Spark를 그냥 Sc해도 되겠지만, Spark로 Conventional하게 Session을 만들었고,
.builder = Spark-context가 만들어져서 이 spark-context가 RDD를 만들고 JVM과 소통하면서 실제로 Spark-context가 작동하는 원리다. 빌더가 background 단위에서 spark-context를 만들어줍니다.
.master = local의 call을 4개정도 주었다.
.getOrcreate = 내가 만든 app 스파크 세션을 불러올것이고 아니면 새로 생성한다는 의미. ('myFirstSparkSession')
과일은 6개로 형성하였고 학생수는 500명으로 하였습니다.
pandas로 DataFrame을 만들어줬고,random.choice를 활용해서 랜덤으로 받을수 있게끔 설정해두었습니다.
Spark DataFrame은 볼때 Show라는 명령어를 통해서 데이터를 볼수 있습니다.(숫자를 집어넣어서 볼수도 있음.)
display()도 사용가능한데 로컬세팅환경에서는 show를쓰고 display는 databricks를 활용해서 프레임을 디테일하게 확인가능합니다.
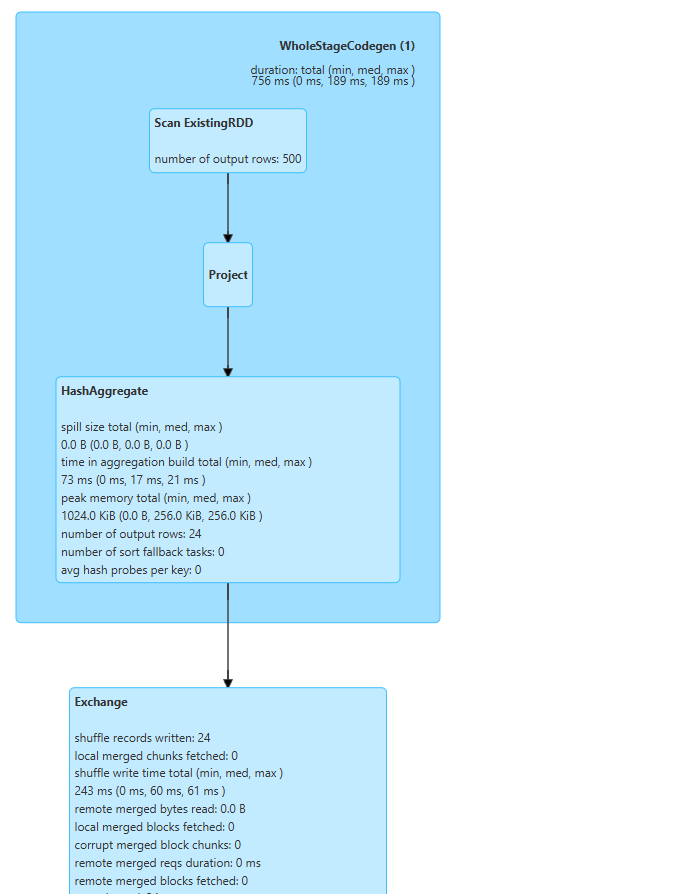
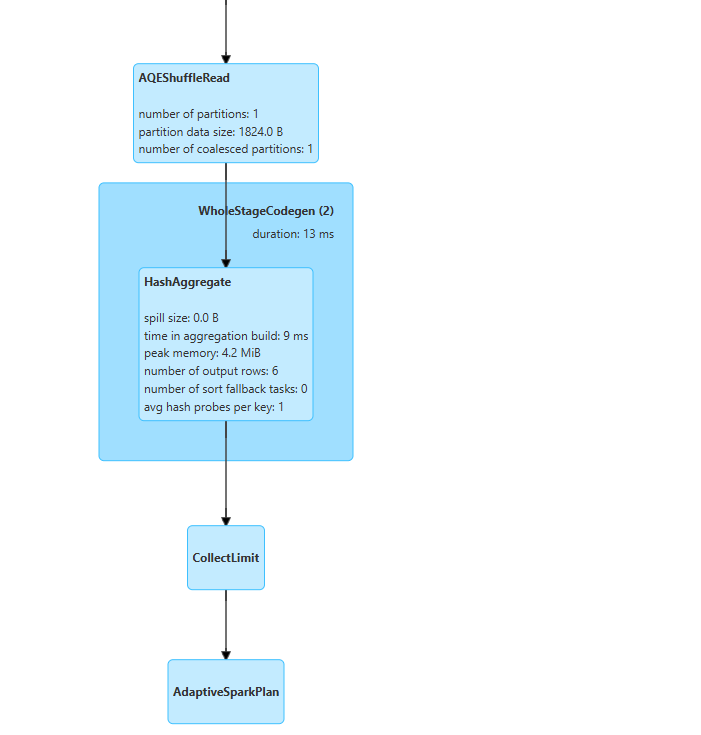
해당 내용은 Java IDE를 클릭해서 보게되면 이와같이 Spark는 방금전에 조합으로 어떤식으로 처리하고 가장효과적이고 효율적인지 이와같이 스스로 분석하게 된다.
RDD = 500개가 스캔을해서 만들어지고
Project = SQL 문에서 Select에 해당된다.
Hash Aggregate, Exchange = 집계할때의 전략을세우고 데이터를 교환해서 셔플하는 과정
AQEShuffleRead = 최적화콜 셔플할때 최적화단계
Adaptive SparkPlan = 최종단계이고 가장 최적화된 SparkPlan이 세워졌다. 이와같은 Dag가 세워짐
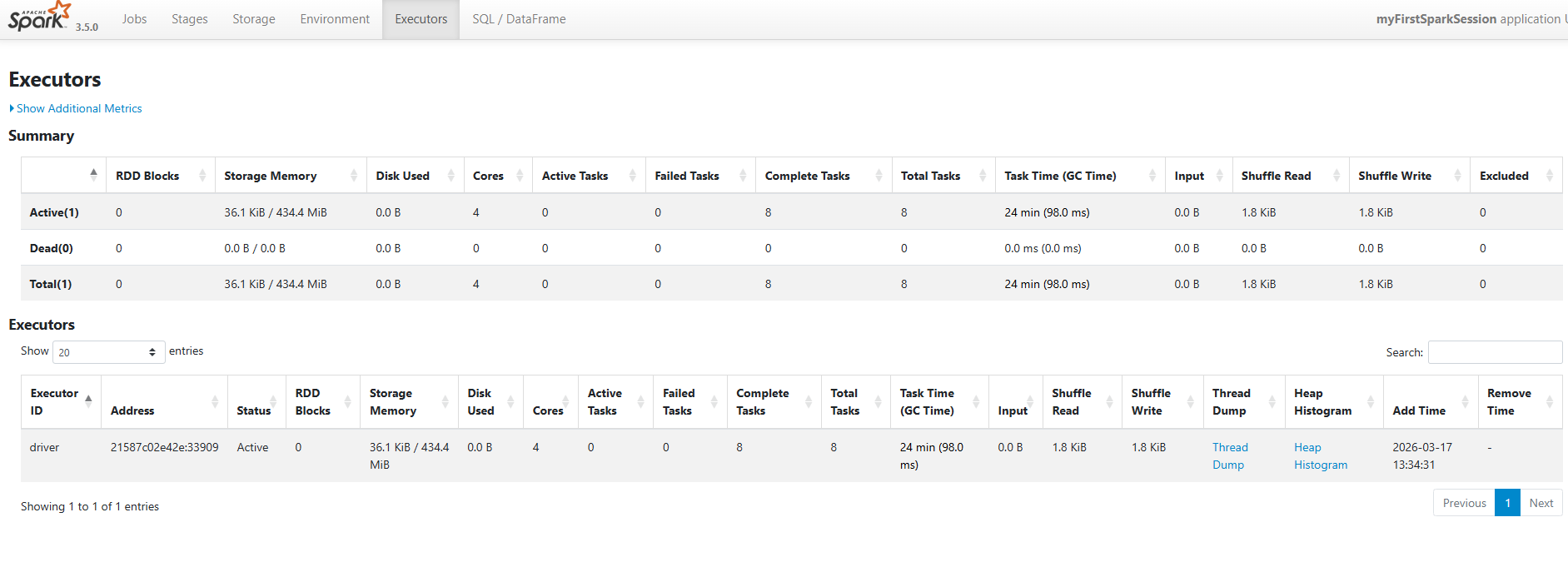
Executor를 보게되면 Spark UI에서 보게 되면 실제로 클라우드에서 보는것과 조금 다릅니다.
로컬환경에서 머신하나에 대해서 가상머신이기 때문에 drive에 executor가 표현되지 못한다.
하지만 실제로는 모든프로젝트는 클라우드환경에서 빅데이터를 가지고다루기 때문에 드라이버는 로컬환경에서 존재하지 않고 가상머신에서 YARN으로 JVM이 올라가면서 결국 드라이버가 모든 작업에 대한 오케스트레이션을 하게된다.
실제로 클라우드 환경을 적용햇을때 executor 1,2,3 번호가 매겨지게 된다.
Spark Lazy Operations & Action
레이지 오퍼레이션스와 액션의 각각의 명령에 대해서 한번 짚고 넘어가보겠습니다.
python,sql을 다뤄본사람들은 쉽게 명령어를 이해할것이다.
눈으로 한번 훓어보고 스파크에 대한 명령문을 머리속에 익혀두길 바랍니다.
Lazy Operations
| select() | column 선택 |
| filter()/where() | 특정조건 |
| withColumn() | 추가적인 column ex:) column에 F열까지밖에없는데 G열을 어떻게 구성해서 넣을지 |
| drop() | dataFrame에서 특정한 Column을 없애버리기 |
| groupBy() | dataFrame의 특정 Column값 묶고 취합 |
| agg() | 통계를 내기위한 명령어 = aggrigate |
| join() | dataFrame 두개를 합칠때 사용 |
| union() / unionAll() | dataFrame 두개이상을 연결시키기 위함 |
| distinct() | 특정 Column의 값에서 유니크한 값만 추출할때 |
| sort()/orderBy() | 내림차순 오름차순 정렬할때 사용 |
| limit() | 데이터 추출할때 갯수 |
| repartition()/coalesce() | dataFrame이 실제로 메모리상에 저장되어 있을때 몇덩어리의 파티션을 정할지 |
| selectExpr() | Expr = Expression SQL로 작성된 Select 구문을 직접 사용하기 위해서 사용됨 |
| withColumnRenamd() | Column 이름을 변경하기 위함 |
| dropDuplicates | Duplicates = 중복된 값을 탈락시키기 위함 |
Action
| show() | 데이터 결과 확인하기위한 용도 |
| collect() | rdd단위로 row단위로 데이터를 모아서 볼때 즉,특정한 컬럼의 값을 볼때 사용 |
| count() | 갯수를 샐때 |
| head()/take(n)/first() | DataFrame의 머리부분,앞부분 처음에 몇개를 추출한다, take는 데이터프레임의 일부만 보기위함, First는 첫번째만 보기위함 |
| write()/save() | Data를 실제로 쓰는 행위, 파일을 저장하는 행위 |
| foreach() | 데이터프레임의 행을 각각 불러오면서 데이터를 처리하고 싶을때 ForEach를 사용 |
| foreachPartition() | 파티션 단위로 DataFrame을 처리할때 |
| writeStream() | 스트림 방식으로 들어오는 데이터를 실제로 다시 스트림 방식으로 파일로 저장할때 사용 |
| toPandas() | spark dataFrame을 Pandas dataFrame으로 변형할때 사용 |
| describe() | 데이터 프레임의 내용을 요약하기위함 |
| summary() | 데이터 프레임의 내용을 요약하기위함 |

explain의 lineage는 아래에서부터 위로 올라가면서 읽으면 됩니다.
정리
이번블로그에서는 Spark UI와 예제를 만들어서 활용한 분산처리 방식을 직접 해보고 LazyOperation을 활용해봤습니다.
다음시간에는 파티션과 셔플 그리고 클러스터에대한 리소스구성과 동작에 대한 이해방식을 다뤄보도록 하겠습니다.
'Spark' 카테고리의 다른 글
| [Spark] - 12bestCodingQuestions - 스파크 핵심 기법 (0) | 2026.03.21 |
|---|---|
| [Spark] - DataFrame (0) | 2026.03.18 |
| [Spark] - Cluster (0) | 2026.03.18 |
| [Spark] - Partition&Shuffle (0) | 2026.03.17 |
| [Spark] - 실전 스파크 (0) | 2026.03.16 |