Partition
Spark의 Partition은 RDDs나 Dataset를 구성하고 있는 최소 단위 객체이며, 스파크의 성능과 리소스 점유량을 크게 좌우할 수 있는 RDD의 가장 기본적인 개념입니다.

Spark는 Parquet와 호환이 잘되어있어 보통 parquet을 많이 사용하는데, master(local[5])로 '코어5개'로 설정해두었기에 parquet이 write.mode를 사용하여 5개의 파퀘로 저장되는걸 볼수 있다.
그렇다면 우리가 정해진 코어 갯수만큼만 항상 Parquet파일이 저장이되나? 그렇친 않다.
내가 수동으로 정할수도 있다 왜냐면 정보를 보게되면 Size가 분산처리를 한다하면 잘개 쪼개면 데이터를 읽는데 i/o과정에서 시간이 오래걸리기 때문이다.

이렇게 repartitioned 를 사용해서 2개로 수동으로 변경이 가능하다.
비슷한 방법으로 파티션의 개수를 정하는 방법중의 하나가, Coalesce다
하지만 coalesce를 사용할때 repartition은 10개로 변경이 가능하지만 coalesce는 10개로 변경했더니 5가 나온다.
repartition = partition이 현재 가용하는 일꾼, 즉 core개수보다 작거나크게 모두 양방향으로 정할수 있다.
coalesce = coalesce는 아무리 partition 갯수를 늘린다 한들 현재 가용하는 core의 개수보다 많게는 파티션이 분할되지 않는다는 점이다.
파티션을 나눌때 이점을 유의해야 한다.
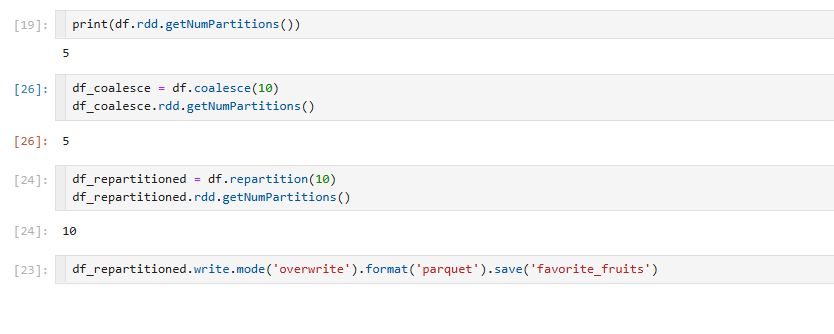
`partitionsby`를 사용하게되면 지정해둔 카테고리별로도 저장이 가능하다.
각각의 과일별로 저장되는걸 볼수가있다.
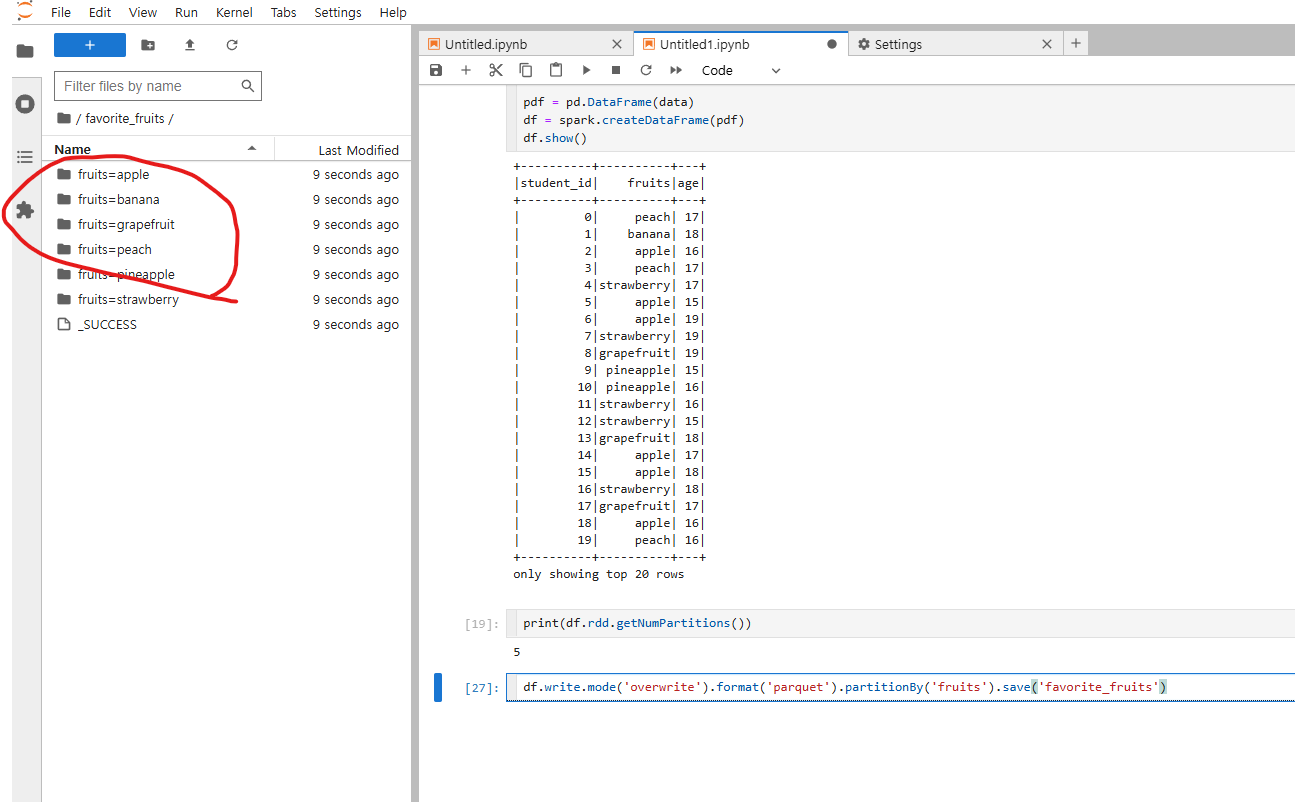
만약 카테고리안에 있는 칼람기준으로 저장한걸 불러들이고 싶다면 이와같이 불러들일수도 있다.
filter조건을 사용하기 위해선 위와같이 from절을 사용해서 col을 불러들어와야한다.
apple만 찾고싶다고 한다면,스파크 입장에서는 이 전체를 다읽어가면서 apple을 찾는게아니라
apple의 위치만 찾아서 읽을수 있고 I/O 시간을 많이 단축시킬수도 있다.
실무에서 많이 사용되기 때문에 알아두길 바란다.

Apache Spark는 이와같이 논리적 파티션, 물리적 파티션이 모두 가용한다.
Shuffle
- transformation
- select
- where/filter
- withColumn
- groupBy : 그룹바이에서는 복잡한 에그리게이션의 명령이 들어가게 된다면 와이드셔플이 크게 이루어질수가 있음.
- agg:
- shuffle
- narrow shuffle(one to one)
- wide shuffle(one to many)
셔플에는 두가지로 구분해 볼수가 있습니다.
1. narrow shuffle : 파인애플을 좋아하는 사람의 개수를 구하고싶어요 그러면 각각의 코어에게 파인애플이 몇개인지 한번 취합해봐 라고 하게 되면 자신이 가지고 있는 데이터를 살펴서 파인애플을 좋아하는 학생이 몇명인지 그냥 카운트만해서 던저준다.
이와같이 코어교환이 일어나지 않음으로서 Spark의 성능이 극대화 된다.
그래서 실제로도 어떻게하면 내로우셔플을 가장 많이 하는 쿼리를 짤수 있을지 가급적으로 많이 사용할수 있는 방법을 생각해야한다.
2. wide shuffle : core끼리 지방방송이 많은 셔플방법이다. core끼리 데이터있는지 계속 체크해보고 스파크 전체 성능을 매우 떨어트리는 행위이다
이런것들을 머릿속에 기억하고 실제로 스파크 핸즈온을 해보는게 좋다.
narrow shuffle

project를 보게되면 fruit가 선택이 되엇고 ('groupby' 가 선택이 됨) - group by에 대해서 partial_count
partial_count = 각각의 파티션 별로 데이터가 분산되어 있을탠데 파티션끼리 카운터 집계를 한다는 뜻

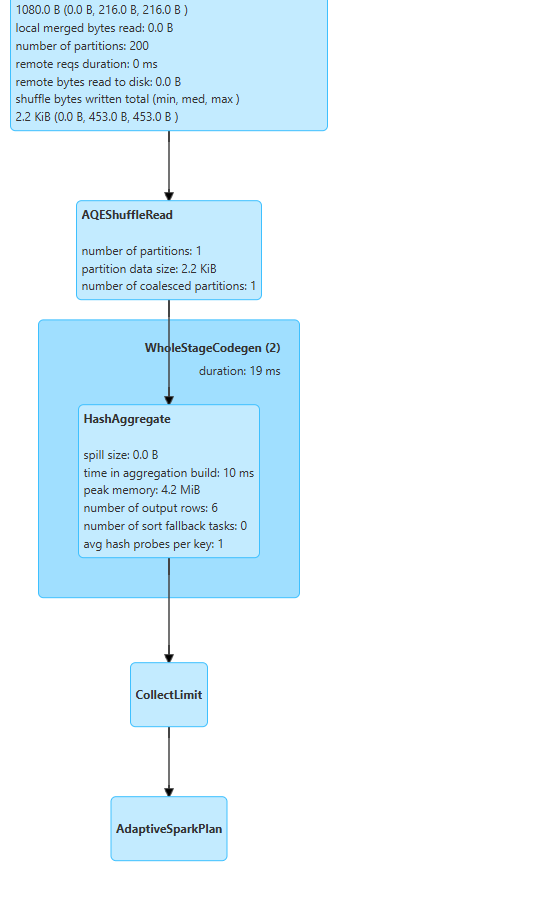
fruit_counts.show()로 확인하면 각각의 과일별로 학생들이 선호하는 선호도 개수가 단순집계로 처리되는걸 볼수있습니다.
이걸 네로우 셔플이라고 합니다.
wide shuffle

학번과 age라는 데이터프레임을 하나 더 만들어서 데이터를 병합을 시켜보겠다. 즉 Join을 시켜보겠다.
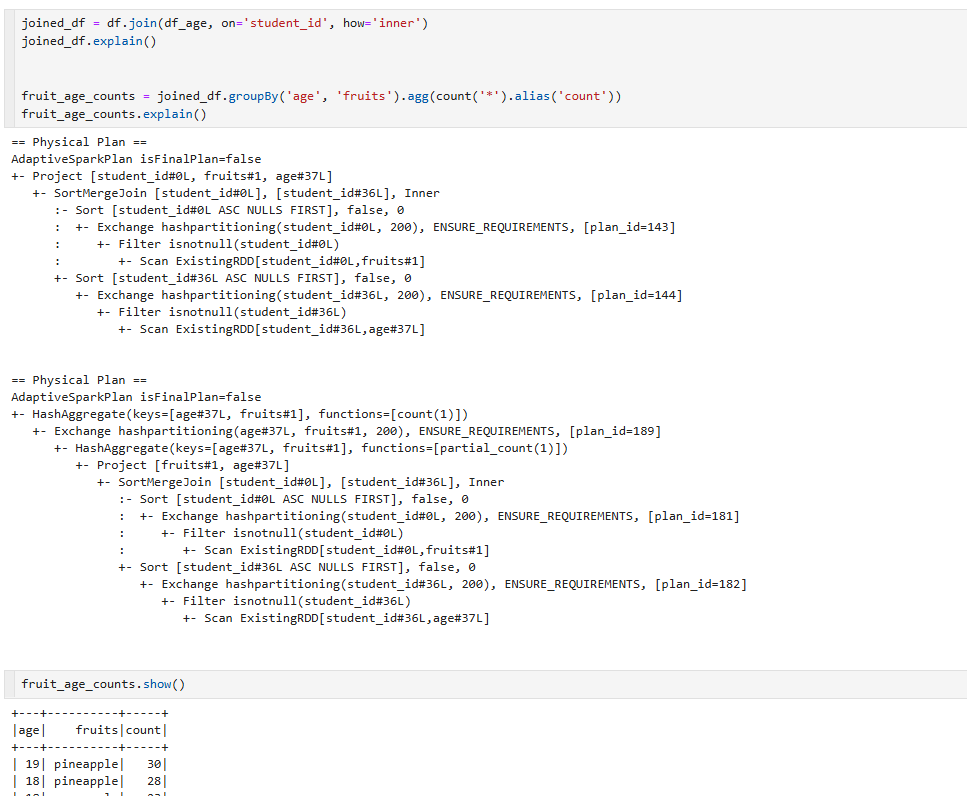
join이라는 dataframe 을 만들고 방식은 inner로 하였다.
첫번째 열에서 sortmergeJoin이라는게 있는데, 데이터를 순서대로 정렬한다는 뜻이다. asc 오름차순으로 정렬된다는 뜻
그리고나서 두번째열에서는 joined_df에 대해서 groupby를 해봤다.
나이별,과일별로 묶은다음에 이 두가지 기준으로 하나의 그룹을 형성한 뒤에 카운트를 해본 결과이다.
특별히 와이드 셔플이 일어나진 않았지만 partial_count가 일어난걸 볼수가 있다.
맨마지막에 AdaptiveSparkPlan isFinalPlan=false 는 최종모델이냐라고하게되면 아니다라고 하고 이와같은 분석을 하게된것이다.
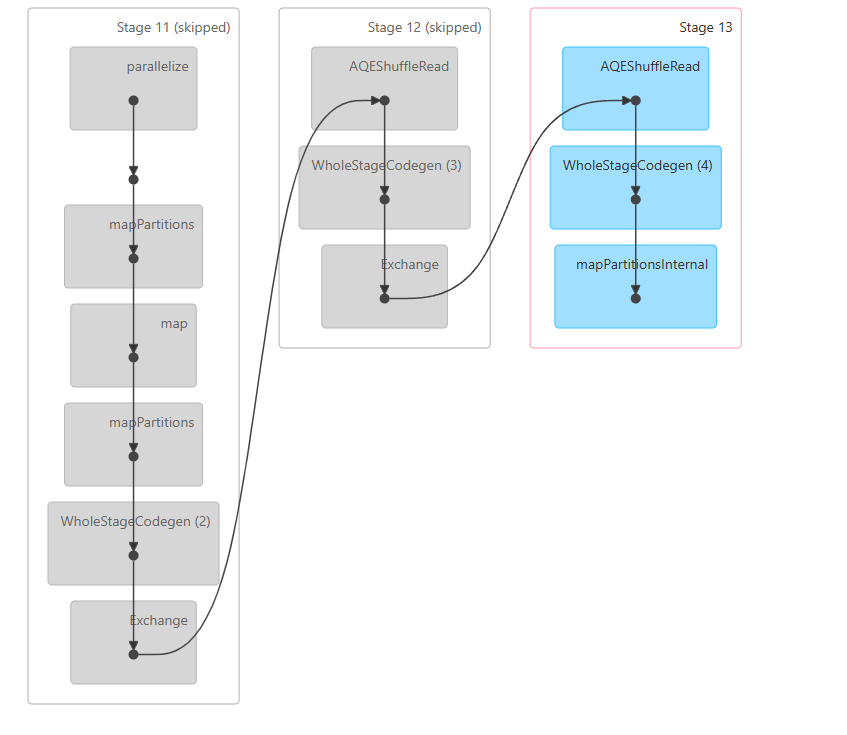
Spark ui로 가서 DAG를 확인해봤을때 병렬로 처리된걸 확인해볼수가있다.
데이터가 셔플로 이루어지는과정과, 교환이 이루어지는걸 볼수가있다.

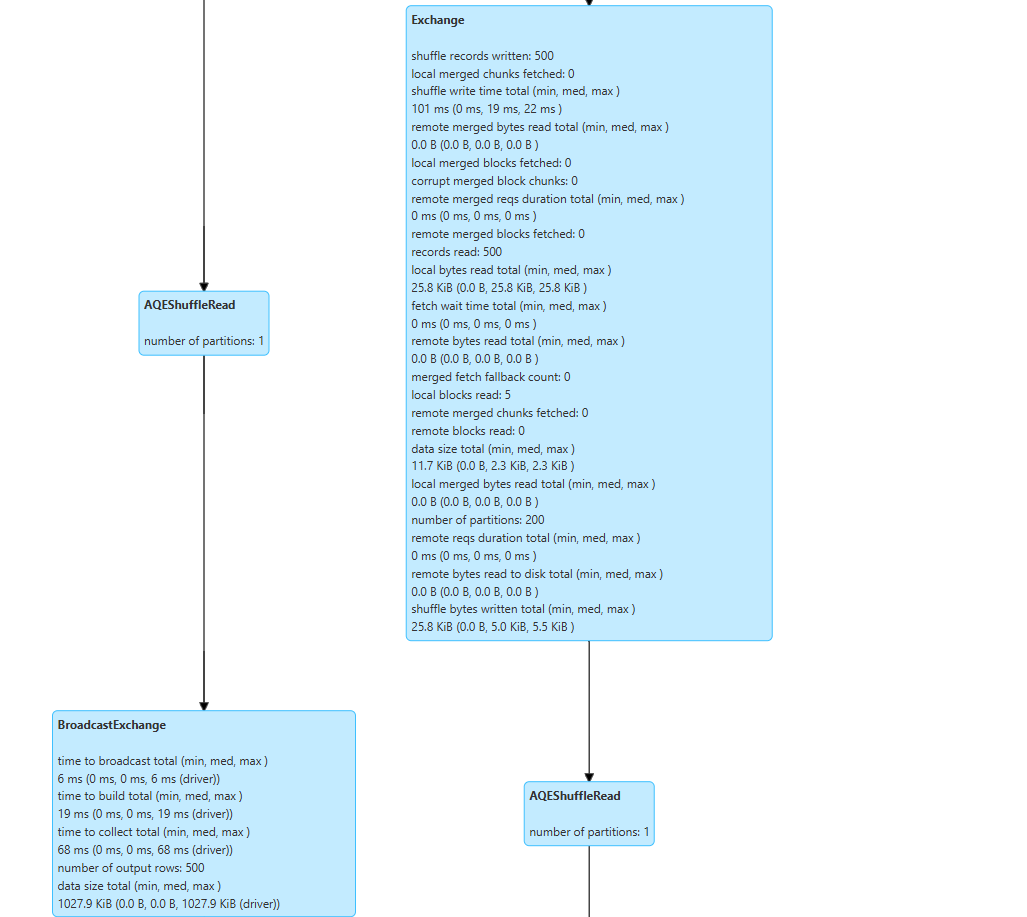


500개씩 들어와서 exchange가 되는과정을 볼수가있고,
두개의 데이터가 병합하는 과정에서 BroadcastHashJoin이 되는걸 볼수있는데,
셔플할때 와이드셔플이 되기전에 최소화 할수 있는 조인이 브로드 캐쉬 조인이라고 이와같은 방법을 적용이 된걸 볼수가있다.
빅데이터가 된다면 이와같이 적용이 될수가없는데 500개밖에 안되서...그렇다
BroadcastHashJoin = 말그대로 방송이다
코어끼리 연락을해서 야! 서로 연락안하고, 네트워크안해도 되니까 내가 아예갖고있는 데이터로 참고할수있게 데이터를 줄게 방송한다고 생각하는게 이해가 쉬울거다. 코어끼리 서로 연락을 하지 못하게 데이터를 제공하는 방식이 BroadcastHashJoin이다.
'Spark' 카테고리의 다른 글
| [Spark] - 12bestCodingQuestions - 스파크 핵심 기법 (0) | 2026.03.21 |
|---|---|
| [Spark] - DataFrame (0) | 2026.03.18 |
| [Spark] - Cluster (0) | 2026.03.18 |
| [Spark] - Spark UI,Lazy Oparation, Action (0) | 2026.03.17 |
| [Spark] - 실전 스파크 (0) | 2026.03.16 |