DataFrame에 대한 개념에 대해서 다뤄보고 블로그를 작성해보려합니다.
이번 주제는 sparkDataFrame과 PandasDataFrame에 대해서 이해하고 넘어가기위함입니다.

PandasDataFrame
pandasDataFrame을 생성할때 데이터로 사용한것을 보게되면 fruits 같은 경우는 6가지에서 Numpy로 배열을 만든 모습이다.
numpy array를 만들었는데, 학생의 수도 1000명을가지고 array를 만든 상황이다.
학생 번호도 우리가 1000개를 배열로 다 만들었다.
지금 데이터프레임이라고 하는것은 결국 위에 표와같은 현재 배열을 나타낸다
Numpy array에 각각 해더값을 줘서 스키마를 입힌다음에 이와같은 x,y 가로 세로 엑셀모양의 형태로 나타내는것을 데이터프레임이라고 한다.
DataFrame = wrapper이다
즉 데이터프레임은 연속적인 데이터의 특징을 이름을 명명하고 그것들을 맵핑한것
지금만든것을 SparkDataFrame으로 만들어보겠다.
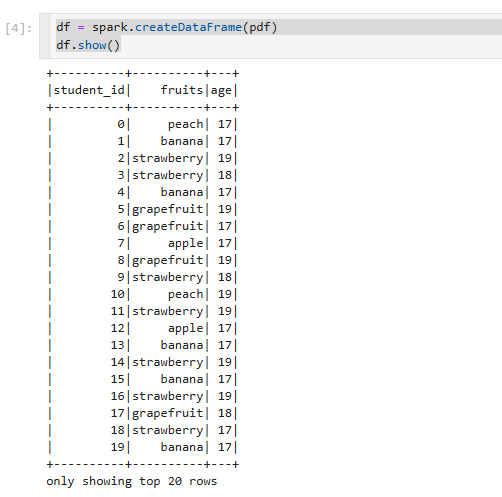
SparkDataFrame
그래픽적으로는 UI만 좀 다를뿐 생긴게 똑같을순 있지만 맨 아래밑에 보면 only showing top 20 rows
20개만 보여주는데 spark는 극도로 효율적인 데이터 처리를 하기위해서 만들어진 프레임을 구한다.
spark는 모든 데이터를 메모리상에 탑재해서 처리는 하지만 pandas처럼 전체의 데이터를 모두다 스캔해서 보여주는 개념이 아니라 sparkdataframe은 전체 메모리를 읽는것이 아니다.
그리고 sparkDataFrame은 pandasDataFrame처럼 index값이 존재하지 않는다.
왜냐면 데이터프레임이 파티션 단위로 저장되기 때문이다.
즉 SparkDataFrame은 분산 처리할 목적에 최적화 되어있는 데이터 저장 형태이다.
PandasDataFrame 과 SparkDataFrame의 차이점
가장 큰 차이점중 하나는 Pandas는 mutable하다는 특징이 있고 spark는 immutable하다는 특징을 가지고있다.
mutable 하게됬다 이말은 프로그램에서 변경,변형이 가능하다라는 뜻이다
immutable은 프로그램에서 변경,변형이 불가능하다는 뜻이다
데이터변형이 불가하다는 뜻이다 python의 tuple과 list로 생각하는게 편하다
python에서는 tuple은 immutable 하지만 list는 mutable한것처럼 말이다.
이것의 가장 큰 장점은 데이터 무결성(integrity)을 나타낸다는 뜻이다.
데이터가 흠결없이 종속되고 보존되기 때문에 Spark가 데이터프레임을 처리하는 과정에서
에러가 발생할수 있습니다 그렇게 에러가 발생했을때 그 에러를 복구 가능한 상태로 만들어주고 다시 이어서
연산을 할수 있는 가장 큰 장점을 가지고 있다.
SparkDataFrame의 또하나의 특징은 pandas에서는 불가능한 실제로 데이터베이스화를 시킬수 있다.
정확히 말하면 데이터베이스에서 사용하는 View형태로 만들수 있습니다.
DB를(View)형태로 만들수 있다는것은 SQL을 직접 날릴수도 있다는 얘기다

위와같이 동일한 데이터 프레임에 index값의 이름을 변경해봤다.
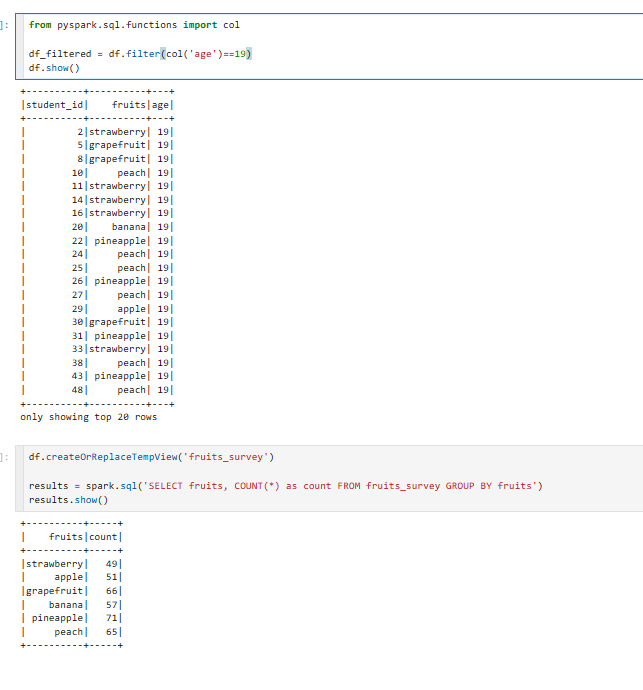
이와같이 데이터프레임에 필터를 직접 적용해서 19세만 뽑아봤습니다.
그러면 위에 pandas와 spark는 이름이 같다. 하지만 spark는 메모리상에 독립적으로 존재하는 서로 다른 데이터 프레임이다.
실제로 spark를 다룰때는 변형단계에서의 데이터프레임 이름을 가독성이 높은 형태로 바꿔주기를 권장한다.
두번째는 TempView의 이름을 만들어서 results 결과값에 spark.sql을 직접 날릴수있다.
전체카운트를 해서 as를 count로 바꾼뒤 그룹으로 묶어주고 결과값을 show로 확인할수있다.
'Spark' 카테고리의 다른 글
| [Spark] - Window part(rank,row_number,accumulation,rowsBetween) (0) | 2026.03.22 |
|---|---|
| [Spark] - 12bestCodingQuestions - 스파크 핵심 기법 (0) | 2026.03.21 |
| [Spark] - Cluster (0) | 2026.03.18 |
| [Spark] - Partition&Shuffle (0) | 2026.03.17 |
| [Spark] - Spark UI,Lazy Oparation, Action (0) | 2026.03.17 |