Window part에서 총 4가지를 가지고 다뤄봤습니다.
- rank
- row_number
- accumulation
- rowsBetween
일단 window part를 다루기위해서 데이터량을 100만단위로 만들어서 실습과정을 만들어 보았습니다.


기존에 만들었던 sales_date를 가지고 연월 단위로 압축해서 통계를 보기위해서 withcolumns을 사용해서 추출하는 과정입니다.
expr를 활용했고, 100만개의 데이터를 만드는 과정에서같은날에 스토어코드,프로덕트 코드가 데이터중복이 발생할수 있기때문에 drop_duplicates를 사용해서 중복값을 없애줬습니다.
RANK & ROW_NUMBER

window_spac이라고하는 변수에다가 partition by에 윈도우 값을 넣어줍니다.orderBy를 사용해서 price값을 내림차순을 하였고,
df_rank에 withColumns를 사용해서 rank와 row_number를 같이 사용해서 두개의 차이점을 확인할수있게 같이 적용시켜뒀습니다.
price를 보게되면 7~8,8,8위가 3개가 있는걸 확인할수있고 row_number는 count형식으로 되어있는걸 확인할수있습니다.
Accumulation
어큐뮬레이션 같은 경우는 GroupBy를 했을때 window를 사용한 accumulation은 어떻게 다른가 한번 살펴보도록 하겠습니다.

데이터프레임은 별로도 만들지 않고 GroupBy 결과만 가져와본 상태입니다.
aggrigation하고 accumulation이랑 좀 다른 의미이다.
aggrigation = 취합해서 통계를하는 의미이고 accumulation은 누적합을 구하는 의미이다.

df_rev_acc로 sales_date 날짜별로 취합한데이터를 expr를 활용해서 sum을 한 상황입니다.
데이터 결과를 보면 윈도우같은 경우에는 데이터를 압축하지 않습니다.
groupby같은 경우에는 group으로 나눴던 것들이 집합화되면서 안에있던 세부 디테일 내용들을 취합해서 SUM을 한다던가 평균을 낸다던가 MAX를 낸다던가 이와같은 통계데이터를 구하는것인 반면 윈도우 같은 경우는 압축하지 않고 파티션한것일 뿐 모든 데이터 포인트는 그대로 살아있는걸 확인할수 있습니다.
즉 만약 내가 원한다면 A1 89674 2001 07 01월에 하나의 값만 나와야 되는데 20개값만해도 11월 06일까지 나와있는걸 볼수있다.
order by Sales_Date = sales_date를 하게 되면 파티션 year,month가 sales_date단위로 오름차순 나열된 다음에 각각의 데이터 포인트 행마다 sales_rev에 대한 합이 출력된걸 볼수있다. 결국은 누적합이 AccsalesRev로 가는걸 볼수가있다.
이게바로 Accumulation이다.
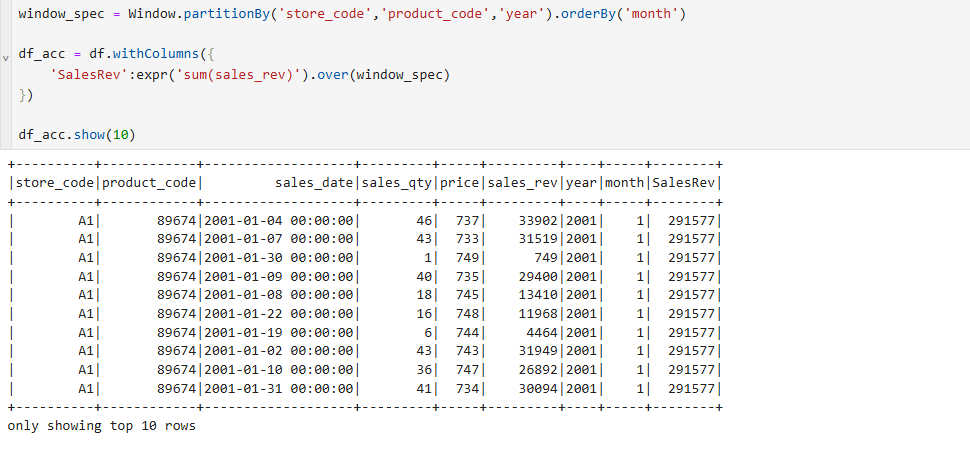
Accumulation을 하다보면 종종 실수하는게 있는데, 동일한 연도에 월을 위에 그림처럼 나열해서 해당 월별로 데이터를 취합을 하고자 위와 같은 방식으로 데이터를 뽑았을때 SalesRev가 동일하게 나오는걸 볼수가있다.
그러면 윈도우를 가지고 누적합이 되려면 어떤방식으로 해야될까!?
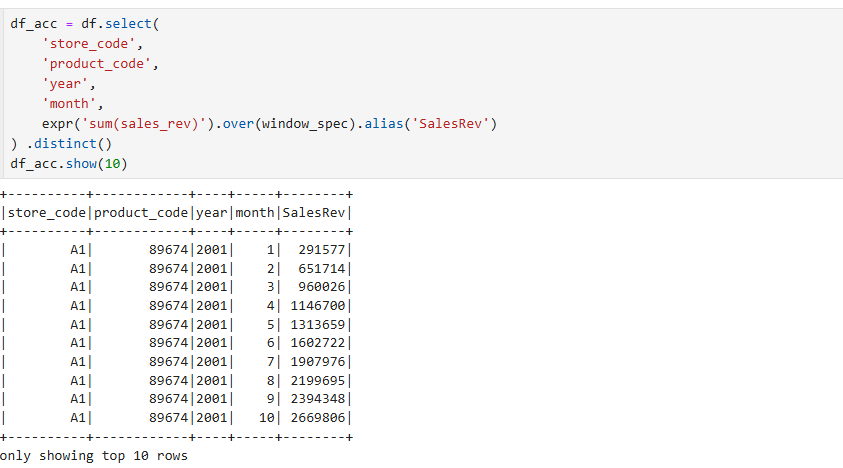
바로 위와같은 방식으로 select를 형성해서 expr를 한다음에 마지막에 .distinct를 활용해서 중복값을 없애고 month에 해당하는 누적값을 구해주면 된다.
rowsBetween
이동평균에 대한 개념을 잠깐 설명하고 가겠습니다
이동평균이란, 말그대로 어떤것이 방향성을 가지고 움직일때 이동하면서 구해지는 평균을 의미합니다. 실제로 많이 사용되는곳은 주가 데이터 5일 이동평균선, 10일 이동평균선 등등 현재를 포함해서 과거 3개월까지의 주가의 평균값을 구해서 같이 현재 당월에 또는 당일에 평균하고 비교해 보면서 주가의 추이를 분석할수 있는 개념이다.

과거 3개월 이전의 값과 과거 3개월이전의 평균값을 구해봤습니다 rowsBetween을 사용할때는 -3 = 3개월전 -1과 0이 있는데 0이라고 하는것은 당월을 포함한다는 뜻입니다. 즉 우리가 들여다볼 Moving Average를 기준으로, 이동 평균을 구한다고 하게되면 직전 3개월, 당월을 포함한 3개월 데이터를 구한다는뜻입니다. 4월을 포함해서 -1,-2,-3을 해서 4개월치의 평균을구한다고 생각하면 된다. 하지만 그림에서는 -1을 주었기 때문에 당월이 NULL값이 나오는걸 확인할수 있습니다.
'Spark' 카테고리의 다른 글
| [Spark] - Spark 소개 및 분산스파크 구조 (0) | 2026.03.22 |
|---|---|
| [Spark] - applyInPandas(머신러닝&정규화) (0) | 2026.03.22 |
| [Spark] - 12bestCodingQuestions - 스파크 핵심 기법 (0) | 2026.03.21 |
| [Spark] - DataFrame (0) | 2026.03.18 |
| [Spark] - Cluster (0) | 2026.03.18 |