applyInPandas라는 고급기술에 들어가기전에 이론을 짚고 넘어가겠습니다.
머신러닝을 사용할때 많이 사용하는 기법이다.
applyInPandas
- 복잡한 작업을 위한 간단한 코드 : pandas라고하는 엄청난 데이터 분석 라이브러리가 있다. pandas를 이용하게 되면 데이터프레임에 대한 다양한 표현이 쉽습니다.Spark의 SQL적인 문법보다 훨씬 더 프로그래밍 적으로 훨씬 더 복잡한 표현을 쉽게 표현할수 있다.
- Pandas 기능 활용
- 메모리 내 처리: Pandas 자체는 디스크에다가 데이터를 쓰거나 하지않습니다. 순수하게 메모리에 탑재해서 인메모리 처리를 하게됩니다. 스파크가 인메모리 연산을 지향하지만, 스파크가 경우에 따라서 메모리 오버플로우가 발생을 하게되면 스파크는 데이터 스필리지(Data spillage)라고해서 디스크에 데이터를 쓰고 읽고를 합니다. 왜냐면 메모리에서 감당이 안되기 때문입니다. 또한 Spark 입장에서는 데이터의 무결성을 중요시 생각합니다.(메모리 잡아먹는 귀신..)
- 단일 변환: 판다스에서는 RDD의 개념처럼 계속쌓아나가는 개념은 아니기때문에 단일변환을 통해서 똑같은 데이터 변환이라 하더라도 RDD가 축적되면서 메모리 공간을 쌓아가면서 분산처리하는 Spark와 달리 간단한 스텝으로 데이터 변환을 할수있는 장점이 있습니다.
단점
- 메모리 사용량 : spark같은 경우에는 메모리가 부족하게 되면 디스크i/o를 하게된다. 스플릿지가 발생하는데 pandas에서는 그렇치 않다
- Spark 최적화 손실 : spark는 런타임을 하면서 우리가 Lazy Execution 스파크는 명령을 받게되면 스파크 드라이버 입장에서 해당의 연산이나 어떤 데이터 변형의 과정을 최적화 값을 찾아 나가는 과정이 먼저 이루어지게 된다. Catalyst같은 분석 툴을 이용해서 최적화의 어떤방법을 찾은다음에 데이터 연산을 하게 되는 과정이 있다.
- 직렬화/역직렬화 오버헤드 : 판다스로 변환하고 다시 그것을 spark로 변환하는 과정, 직렬화/역직렬화를 하면서 퍼포먼스의 처리속도를 줄게된다.
- 장애 허용 불가 : 스파크는 대신 특정 엑시큐터가 연산하는 과정에서 엑시큐터가 장애가 발생하는 경우 다른 노드를 붙혀서 사용해도 극복해 나갈수가 있다. 판다스는 에러를 마주치게 되면 그 즉시 Fail 처리가 된다.

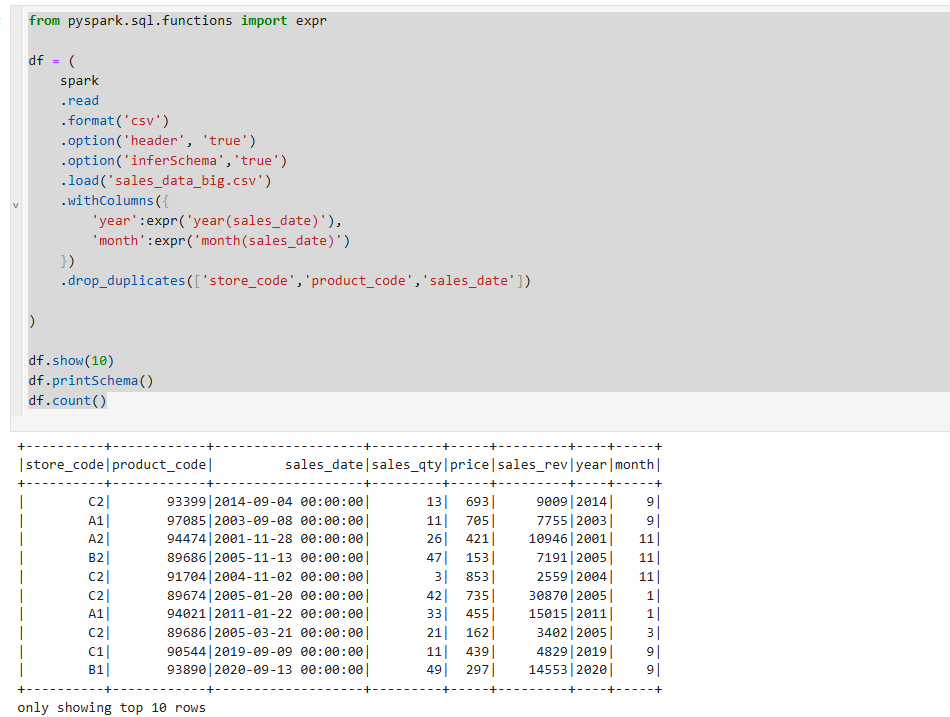
learn_applyInPandas로 Spark를 만들어주고 기존에 만들었던 sales_data_big.csv를 사용해서 데이터를 불러왔습니다.
applypandas로 GroupBy 결과를 동일하게 만들어 보도록 하겠습니다.

처음에 def process_df 라는 데이터프레임을 만들어놓고 데이터프레임은 pandas 데이터프레임으로 만들었습니다.
store_code 단위로 applyInpandas로 파티션이 맺어진 분류된것을 schema를 통해 넘겨주는 과정입니다.
(schema=schema) spark입장에서는 비록 사용자함수로 처리된 결과값에 대해서 그 결과물이 예측되는 스키마와 일치를 해야지만 데이터를 받아들입니다.
판다스 데이터 프레임에 pivot을 활용하여 index,value값을 주어서 어떤값을 줘서 통계를 낼지 만들어주고,reset()함수를 이용해서 칼럼값으로 변환해주었습니다. 그리고나서 mapping을 활용해서 str,uint값으로 설정해서 데이터 값을 설정해주었습니다.
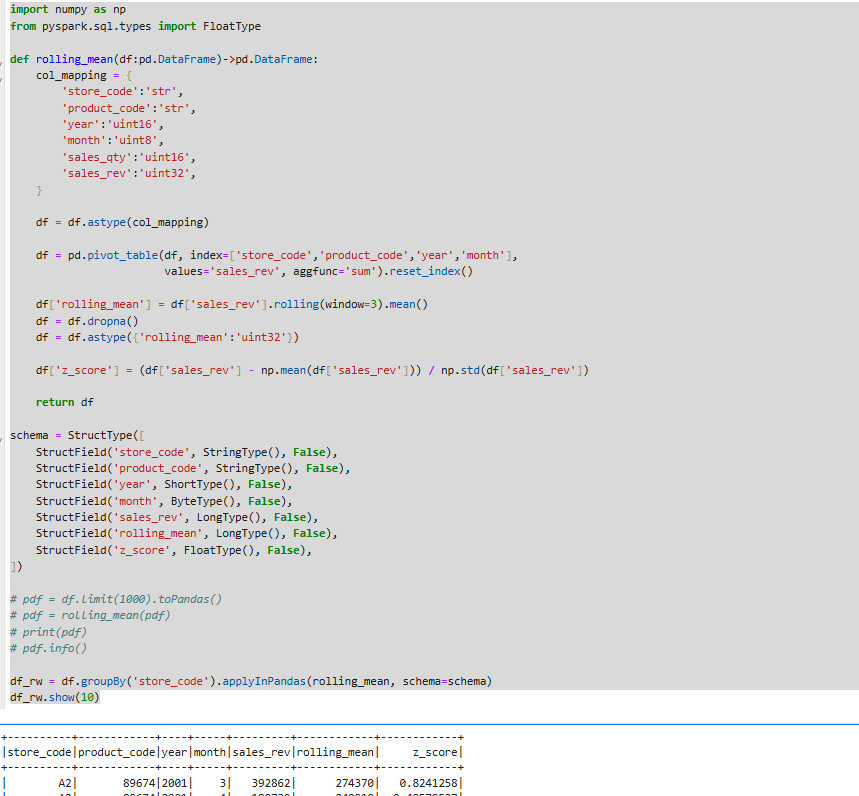
아래는 rollingwindow를 만든 예제입니다.
rolling_min으로 판다스 데이터프레임을 만들어주었습니다.
.roiing을 사용해서 과거 3개월치 데이터를 보는 과정을 만들어 주었습니다.
dropna()를 사용해서 null값을 없애고,astype으로 데이터를 변형해서 소수점 값을 없애주었습니다.
z_score를 통해서 표준 분포 곡선에서의 z값을 주었습니다. 표준분포 곡선에서 해당 값을 구하기 위해서는 표준 편차를 0으로 하면서 표준 분포 곡선을 구하는 것이기 때문에 해당 데이터와 평균을 뺀것을 다시 표준편차로 나누는 과정을 그렸습니다.
각각의 sales 판매 매출에 대하여 평균을 뺀다음에 numpy 표준편차 sales 외분류에 표준편차를 나눠주게 되면 z_score가 구해지게 됩니다.

마지막으로 어플라이드 판다스의 세번째 예시입니다.머신러닝에서 가장 많이 사용하는 예입니다.
머신러닝이 연산하는 과정에서 스케일이 다름으로서 성능이 떨어지는 경우가 발생합니다.
그럴때 하는것이 바로 표준화,정규화 작업입니다.즉, 표준분포 곡선에 정규화 값을 적용하게 되는겁니다.
전문용어로는 normalized 라고도 합니다.
이와값이 normalized 하게될때 pandasDataFrame을 활용하게 될 수밖에 없을겁니다.
왜냐면 이와같은 데이터가 존재할때 우리가 데이터를 분석할때 점포별로 제품별로 어떠한 수요를 예측을 한다던가 어떤 머신러닝을 돌려서 어떤 결과를 받아보고싶은 경우가 있을때 필요하게 됩니다.
'Spark' 카테고리의 다른 글
| [Spark] - Catalyst & Tungsten (0) | 2026.03.23 |
|---|---|
| [Spark] - Spark 소개 및 분산스파크 구조 (0) | 2026.03.22 |
| [Spark] - Window part(rank,row_number,accumulation,rowsBetween) (0) | 2026.03.22 |
| [Spark] - 12bestCodingQuestions - 스파크 핵심 기법 (0) | 2026.03.21 |
| [Spark] - DataFrame (0) | 2026.03.18 |