이번 블로그는 스파크에서 12가지 실무적으로 가장 많이다루는 스파크기법을 가지고 다뤄봤습니다.
anaconda_prompt를 사용하여 sythetic_date를 만들고 vscode로 들어가서 sales_data.csv라는 가상데이터를 만들어 활용해봤습니다. 이번블로그 주제는 내용이 많이 길긴하지만, 실무적으로 많이 사용하니 정리해봤습니다 :)

1. Open a dataset(CSV)

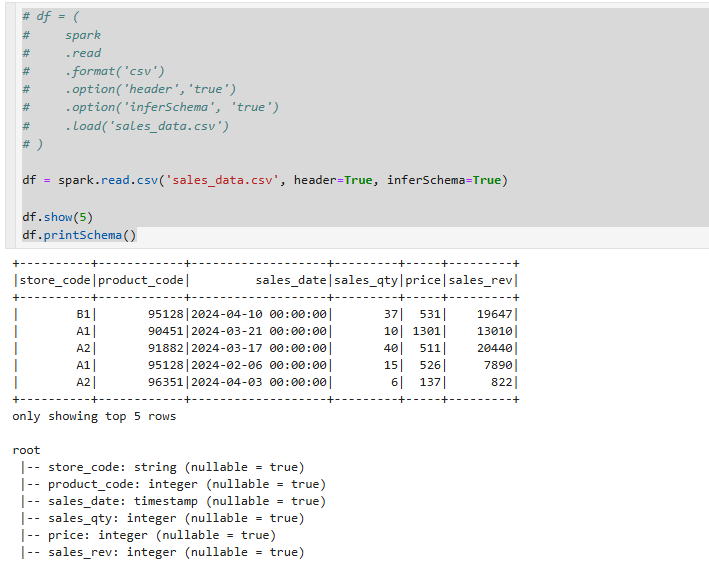
데이터를 불러오는 방법은 몇가지있습니다.
주석처리한 방식으로 불러올수도 있으나,spark.read.csv로 path를 걸고 header값을 넣고, inferSchema를 True로 넣습니다.
inferSchema를 넣으면 데이터타입이 스스로 알아서 판단해 들어가게 됩니다.
2. Filtering by dates
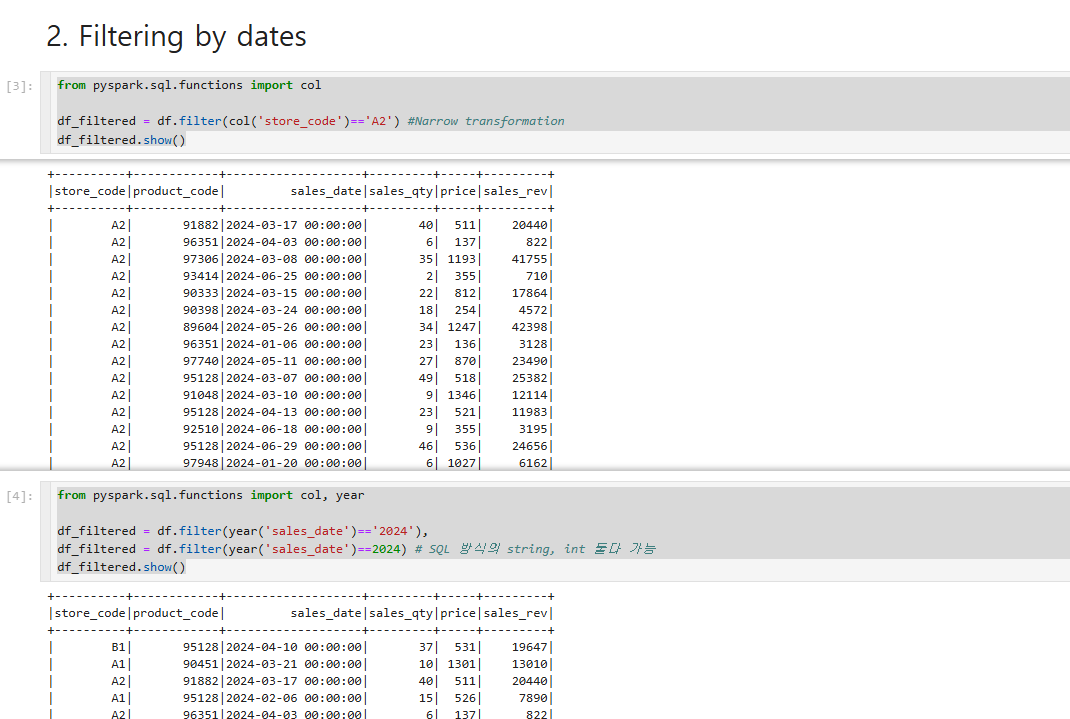
Spark에서 필터링은 명령이 매우 간단합니다. 첫번째는 스토어코드 점포명이 A2로 되어있는 점포만 추출한 결과입니다.
두번째는 2024년 데이터만 추출한 결과입니다. String,int 형식으로 둘다 추출이 가능합니다.
3. join

첫번째는 pandas랑 numpy를 통해서 store_code랑 product_code와 loyal customers를 사용하여 5에서 300까지의 랜덤하게 pdf2 데이터 갯수만큼 만들었다.그리고 pandas df > spark df로 만들어주었다.

조인은 store_code 와 product_code를 가지고 join을 했다. explain을 사용해봤더니 broadcastjoin을 하여서
두개의 데이터 프레임중 하나가 극히 작을때 일반적으로 와이드 셔플을 쓰지않고 사용된다.
funtions에서 broadcast를 명시적으로 사용하여 나타내줬다.
4. aggregation

Aggregation같은 경우는 사실 통계를 내는 과정이다.
sum,max,min,avg,month,countDistinct 등등 각각의 통계를 내는 과정이다.
withColumns로 년도와 월을 만들고 그걸 store_code를 가져와서 그룹바이를 해줬다.
5. Rename Columns

말그대로 Column의 이름을 변경하는거다.
withColumnsRenamed를 사용해서 Total로 이름을 바꿔줬다.
여러개의 컬럼을 변경을 하였는데 s를 붙히고 {} 주석을 달아주면 된다.
단일로도 변경이 가능하다.
6. Change date types
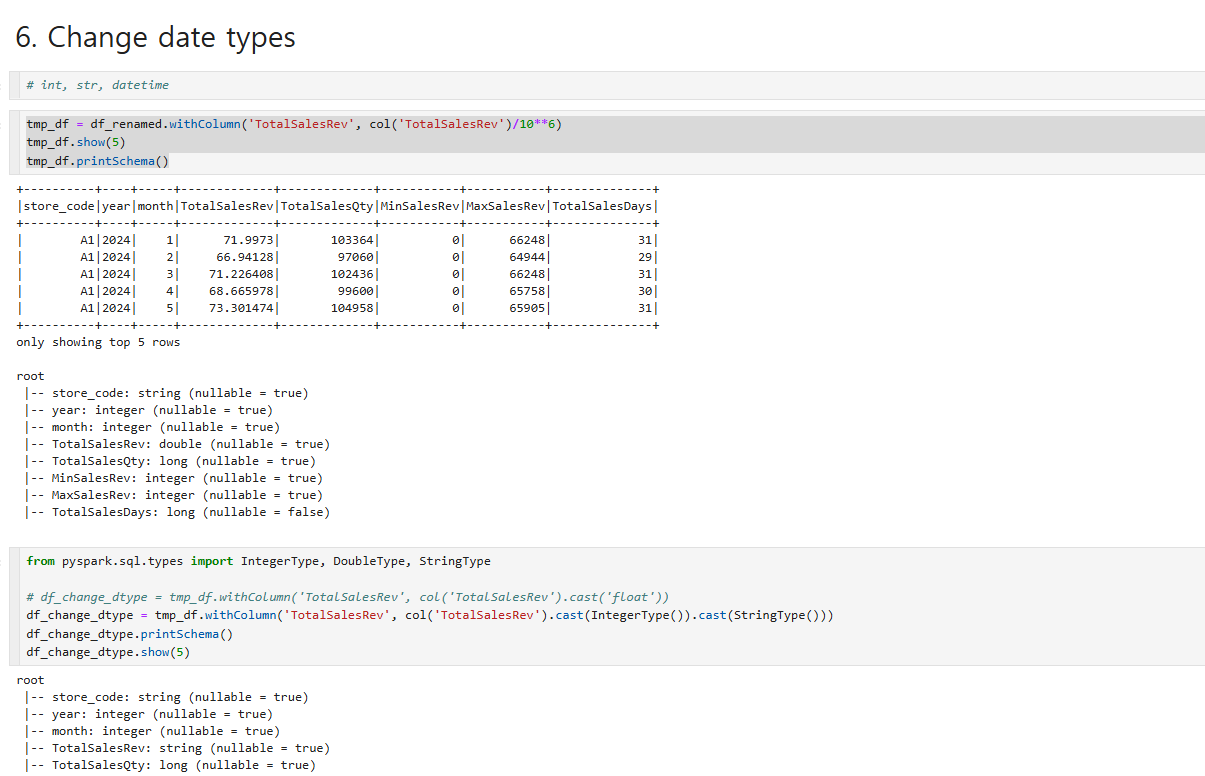
첫번째는 데이터를 만들어 출력을 한 결과이고
두번째는 데이터를 변경하는 과정이다 데이터를 컴팩트하게 빠르게 처리하기위해 cast문을 사용해서 IntegerType으로 변경해주었다.
7. Drop Duplicate

데이터를 분석할때 중요한것중 하나가 바로 데이터의 중복값이 있을 경우이다.
가공할때 결과물이 실제로 내가 원하는값이 아니게 되는경우 중복된 데이터를 제거하는것이 매우중요하다.
첫번째는 일별데이터를 지금 내가 받고있는데 상품코드 날짜 기준으로 동일한 날짜가 여러번 존재하는경우를 체크하기 위해서
확인결과이다. count를 해본결과 숫자가 올라간걸 확인할수 있다. 이와같이 엑스트라로 존재하고있는경우이다
두번째는 drop_duplicate를 활용해서 중복값을 제거한 경우이다.
같은날에 여러개의 중복값을 삭제하기위한 명령어이다.
즉 중복이될때 처음에 포착되는 데이터를 하나를 남기고 나머지는 제거하는 형태이다.
8. Visualization

Spark를 활용할 때는 이것은 Spark를 시뮬레이션 하는 환경이기 때문에 그와같은 기능이 제공되진 않는다.
코드를 작성해서 시각화를 해야하는데, 시각화를 무시할수 없는게 데이터 분석에서 매우 중요한 단계로서 데이터에 대한 직관적인 모습을 나타낸다.
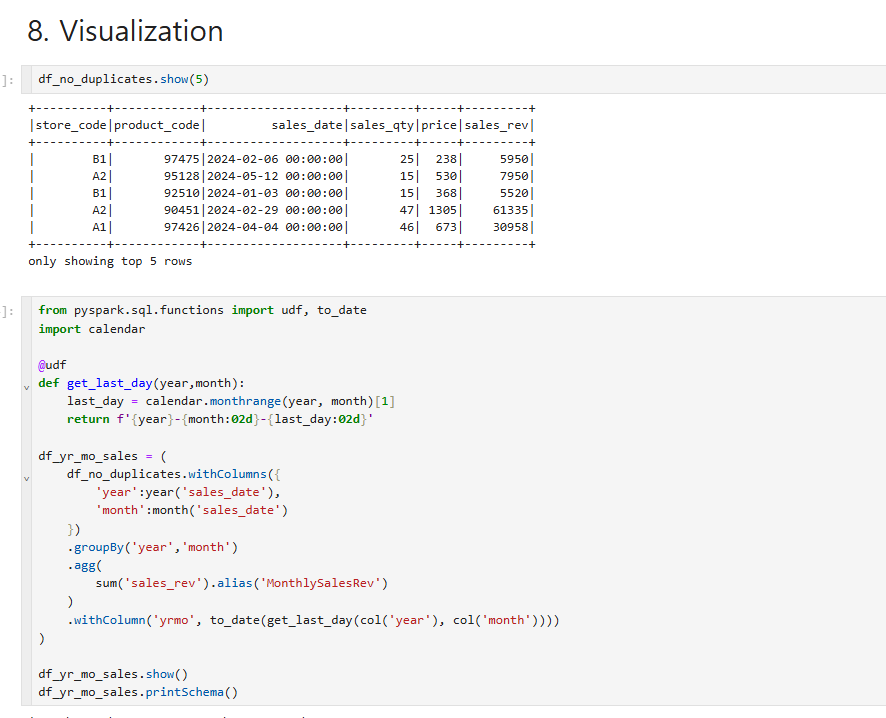
첫번째는 중복데이터를 제거한걸로 사용해보았다.
6개의 칼럼이 존재하는걸 확인해볼수있고
두번째는 데이터프레임의 이름을 정해주고, 전체 회사차원에서 "지점별 모든 매출을 합산해서 월별 매출을 보고싶다" 라고 가정하에 year(년 결과) month(월 결과)를 활용했고,년월 단위로 그룹핑을 하고 aggrigation을 활용해서 sum을 해주었고,
판다스 데이터프레임을 변형해서 맥플롭matplotlib 라이브러리를 사용해서 시각화를 시킨 과정이다.
calender를 사용한이유는 월에 마지막날을 알수 없기 때문에 시각화에 필요해서 사용자 함수를사용하였고
calender 함수는 파이썬에서 함수와 만드는것과 똑같다.
get_Last_day에 year month 를 받아주고 튜플값을 받아준다 마지막날짜는 [1]로 받아준다.
withColumn을 사용해서 'yrmo' get_Last_day 를 넣어줍니다
return값은 year-month-lastday를 설정해두었다.
show를 해보면 날짜가 들어가있는걸 확인해볼수있다.
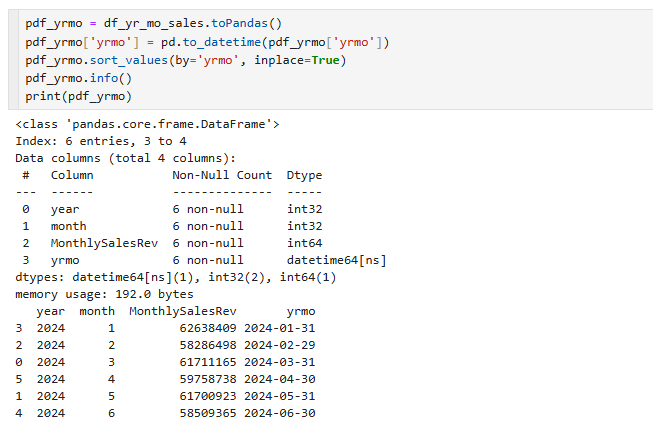
세번째는 판다스 데이터프레임으로 바꿔주고, to_date를 사용해서 datetype을 바꿔주는 모습입니다.
이렇게 되면 시계열로 쓸수가있게 됩니다.
마지막은 맥플롭을 가져와서 시각화를 해주는 과정입니다.
가로가 8 세로가 4로 크기설정해주었습니다.
시계열 데이터의 시각화는 X축 Y축이 필요한데, X축에는 yrmo = 연도와 월별, Y는 MonthlyRev를 넣어주고
data는 paf_yrmo를 넣어줬습니다.
9. Expr
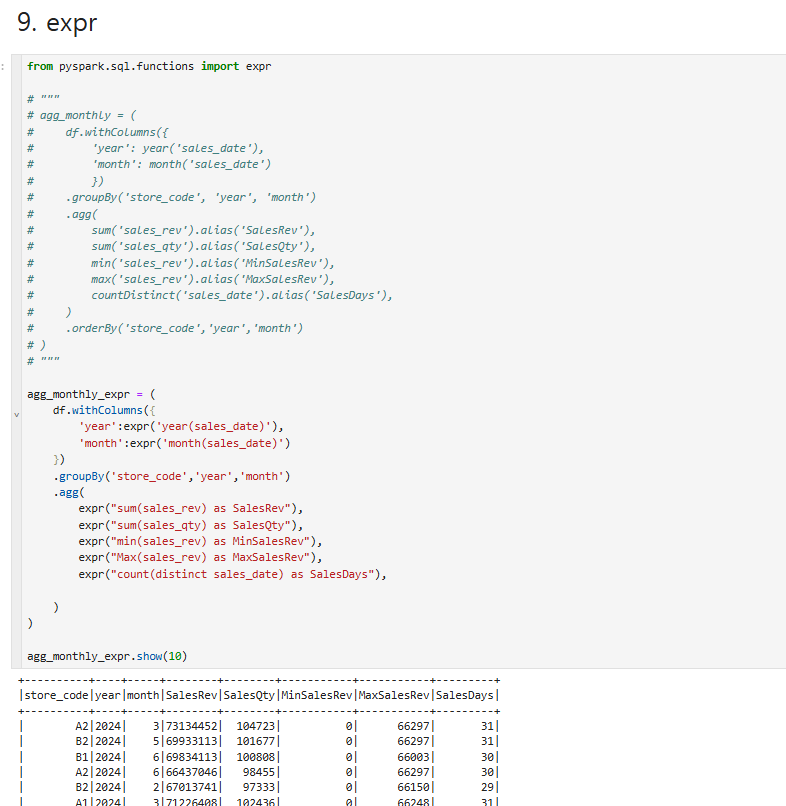
pyspark는 import에서 year,month,sum,min을 불러와서 사용할수 있지만, expr를 사용해서 손쉽게 구현이 가능하다.
위 예제는 expr를 활용해서 데이터처리를 하는 결과이다.
sql문을 쉽게 구사할수도 있지만 python문법이 편한경우 이와같이 처리도 가능하다.
10. Schema and Data Types
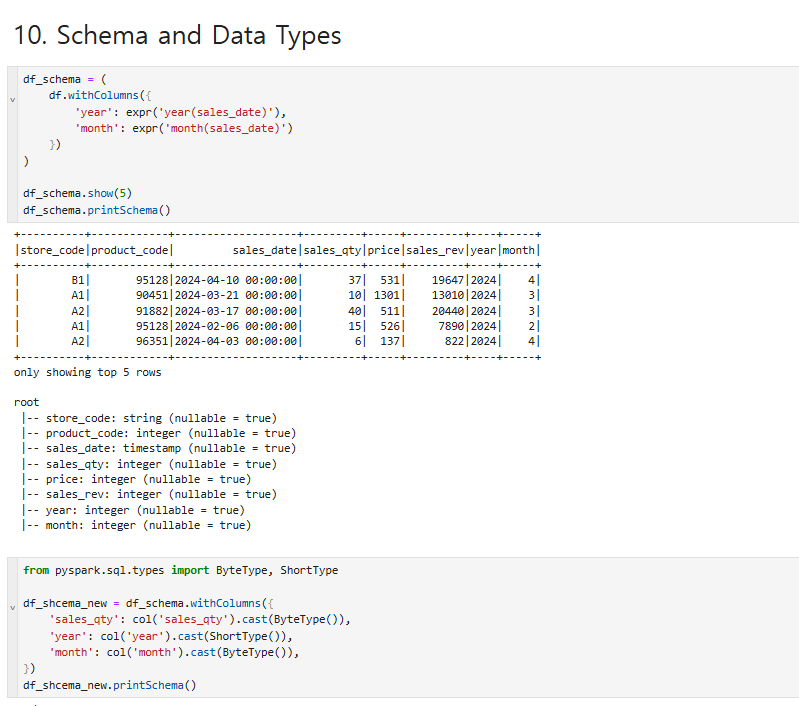

데이터 타입 변경은 6번째 방법에서 간단하게 cast라는 방식을 써서 변경했었다.
그렇다면 스키마와 데이터타입을 이렇게 별도로 뽑아낸 과정에 대한 이유는 뭐냐면, 데이터 타입을 변환하는 방법과 별도로
spark에서는 schema를 spark 스스로가 데이터의 자료형에 대해서 칼럼별로 분석을해서 schema를 추론할 수 있습니다.
즉 칼럼에 해당되는 데이터의 형태를 보고서 schema를 spark 스스로가 추론한다.
그래서 맨처음에 데이터를 불러올때 보면 inferschema를 통해서 명시적으로 알려줍니다.
스키마는 파이스파크로 스칼라가 아닌 파이스파크로 스파크 동작을 명령을 하게 되면 런타임에서 스키마를 자료형을 맞딱뜨리게 된다.런타임에서 스키마를 추론합니다. 즉, 실행하는 과정에서 스키마가 추론하다가 데이터에 오류가 생겼다 라고 하게 되면 에러를 뱉어네게 되는데 컴파일 단계에서부터 에러가 존재하는 데이터타입이 명확하게 해당 컬럼에 규칙에 정확하게 들어있는지를 정합성을 맞추지 못한다. 그렇기 때문에 런타임에서 발생하게 되면 에러가 생기거나 여러가지 문제가 생길수 있기때문에 명시적으로 선언해주면 원천적으로 막을수 있다.
두번째 structField를 보면 데이터 타입을 변형된걸 확인할수 있다.
이게 단순하게 로컬환경보다 데이터가 엄청 많을시에는 저런 데이터 타입이 조금만 달라도 용량에 대한 스파크 성능저하라던지
컴퓨팅 소모가 많게 되는 현상을 막을수 있다.
11. UDF = 사용자 지정 함수


UDF를 가지고 시각화를 한번해봤었는데 UDF는 왜 사용될까?
우리가 스파크를 사용하다 보게되면 스파크가 파이썬과 같은 프로그래밍 언어는 사실 아니다.
그러다 보니까 소위말하는 프로그래밍 언어에서 활용할수 있는 다양한 데이터변환같은 것들을 파이스파크에서 상당히 번거로운 과정을 거쳐야 한다. spark의 분산처리와 같은 강력한 기능이 있음에도 불구하고 우리가 마주치는 데이터라고 하는 녀석들이 사실 생김새가 다양하고 상황에 따라서 다양한 모형으로 가공을 할 필요가 상당히 많다.
그럴때 spark의 어떤 불편한 기능 또는 제한적인 기능들을 벗어나서 파이썬과 같은 프로그래밍의 여러가지 방법론을 도입해서 사용하는것이 바로 사용자 지정함수 입니다.
12. Save Result Dataframe

마지막은 저장하는 방식입니다. parquet 저장과 csv 저장 그리고 append를 사용해서 덮어쓰기를 할수있는 과정 등
저장하는 방식에 대한 내용입니다. csv는 option에 header를 명시해줘야지만 가능하지만 parquet은 option을 사용하지 않아도 됩니다.
정리
스파크관련된 기법을 정리하기위해 2틀밤을 꼬박 샜지만 나름 의미있는 연습이였다.
다음시간에는 window part와 apply 문자열 데이터 처리 방식, null값 처리, 파티션 최적화등 고급데이터 처리는 어떻게 하는지에 대해 자세히 공부해보고 정리할 예정입니다.
'Spark' 카테고리의 다른 글
| [Spark] - applyInPandas(머신러닝&정규화) (0) | 2026.03.22 |
|---|---|
| [Spark] - Window part(rank,row_number,accumulation,rowsBetween) (0) | 2026.03.22 |
| [Spark] - DataFrame (0) | 2026.03.18 |
| [Spark] - Cluster (0) | 2026.03.18 |
| [Spark] - Partition&Shuffle (0) | 2026.03.17 |